TSMC to Introduce Location Premium for Overseas Chip Production
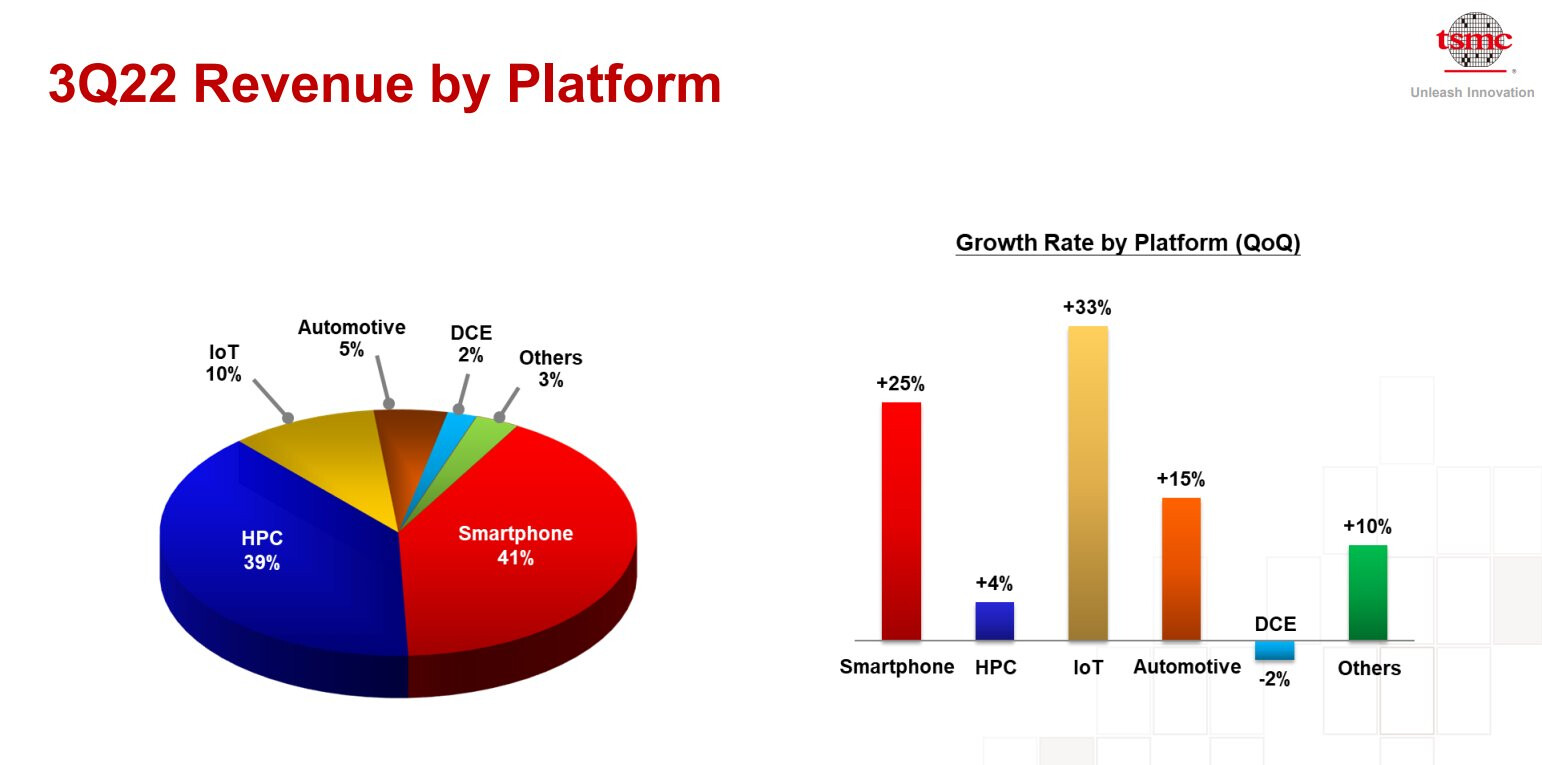
As a part of its Q1 earnings call discussion, one of the largest semiconductor manufacturers, TSMC, has unveiled a strategic move to charge a premium for chips manufactured at its newly established overseas fabrication plants. During an earnings call, TSMC's CEO, C.C. Wei, announced that the company will impose higher pricing for chips produced outside Taiwan to offset the higher operational costs associated with these international locations. This move aims to maintain TSMC's target gross margin of 53% amidst rising expenses such as inflation and elevated electricity costs. This decision comes as TSMC expands its global footprint with new facilities in the United States, Germany, and Japan (JAMS) to meet the increasing demand for semiconductor chips worldwide. The company's new US-based Arizona facility, known as Fab 21, has faced delays due to equipment installation issues and labor negotiations.
Chips produced at this site, utilizing TSMC's advanced N5 and N4 nodes, could cost between 20% to 30% more than those manufactured in Taiwan. TSMC's strategy to manage the cost disparities across different geographic locations involves strategic pricing, securing government support, and leveraging its manufacturing technology leadership. This approach reflects the company's commitment to maintaining its competitive edge while navigating the complexities of global semiconductor manufacturing in today's fragmented market. Introducing a location premium is expected to impact American semiconductor designers, who may need to pass these costs on to specific market segments, particularly those with lower price sensitivity, such as government-related projects. Despite these challenges, TSMC's overseas expansion underscores its adaptive strategies in the face of global economic pressures and industry demands, ensuring its continued position as a leading player in the semiconductor industry.
Chips produced at this site, utilizing TSMC's advanced N5 and N4 nodes, could cost between 20% to 30% more than those manufactured in Taiwan. TSMC's strategy to manage the cost disparities across different geographic locations involves strategic pricing, securing government support, and leveraging its manufacturing technology leadership. This approach reflects the company's commitment to maintaining its competitive edge while navigating the complexities of global semiconductor manufacturing in today's fragmented market. Introducing a location premium is expected to impact American semiconductor designers, who may need to pass these costs on to specific market segments, particularly those with lower price sensitivity, such as government-related projects. Despite these challenges, TSMC's overseas expansion underscores its adaptive strategies in the face of global economic pressures and industry demands, ensuring its continued position as a leading player in the semiconductor industry.