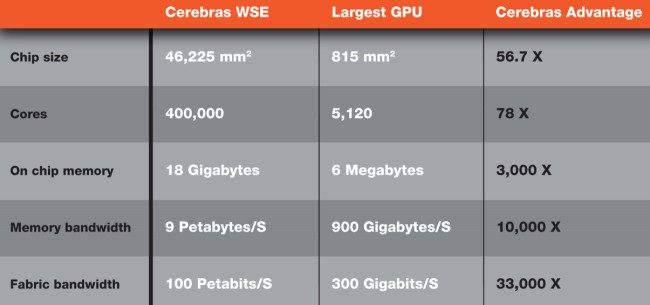
Cerebras Systems, the pioneer in high performance artificial intelligence (AI) computing, today announced, for the first time ever, the ability to train models with up to 20 billion parameters on a single CS-2 system - a feat not possible on any other single device. By enabling a single CS-2 to train these models, Cerebras reduces the system engineering time necessary to run large natural language processing (NLP) models from months to minutes. It also eliminates one of the most painful aspects of NLP—namely the partitioning of the model across hundreds or thousands of small graphics processing units (GPU).
"In NLP, bigger models are shown to be more accurate. But traditionally, only a very select few companies had the resources and expertise necessary to do the painstaking work of breaking up these large models and spreading them across hundreds or thousands of graphics processing units," said Andrew Feldman, CEO and Co-Founder of Cerebras Systems. "As a result, only very few companies could train large NLP models - it was too expensive, time-consuming and inaccessible for the rest of the industry. Today we are proud to democratize access to GPT-3 1.3B, GPT-J 6B, GPT-3 13B and GPT-NeoX 20B, enabling the entire AI ecosystem to set up large models in minutes and train them on a single CS-2."