Apple Introduces the M4 Chip
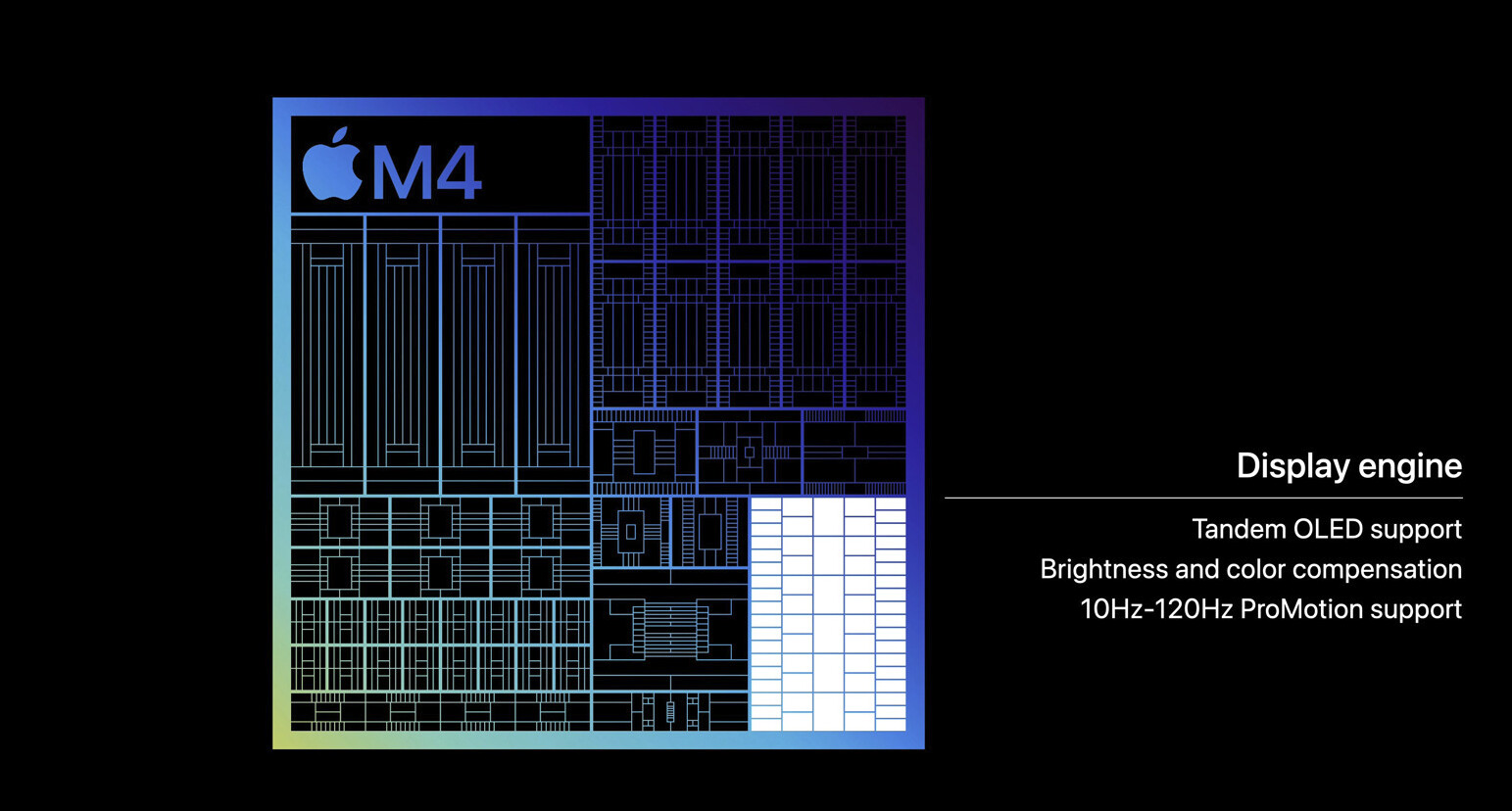
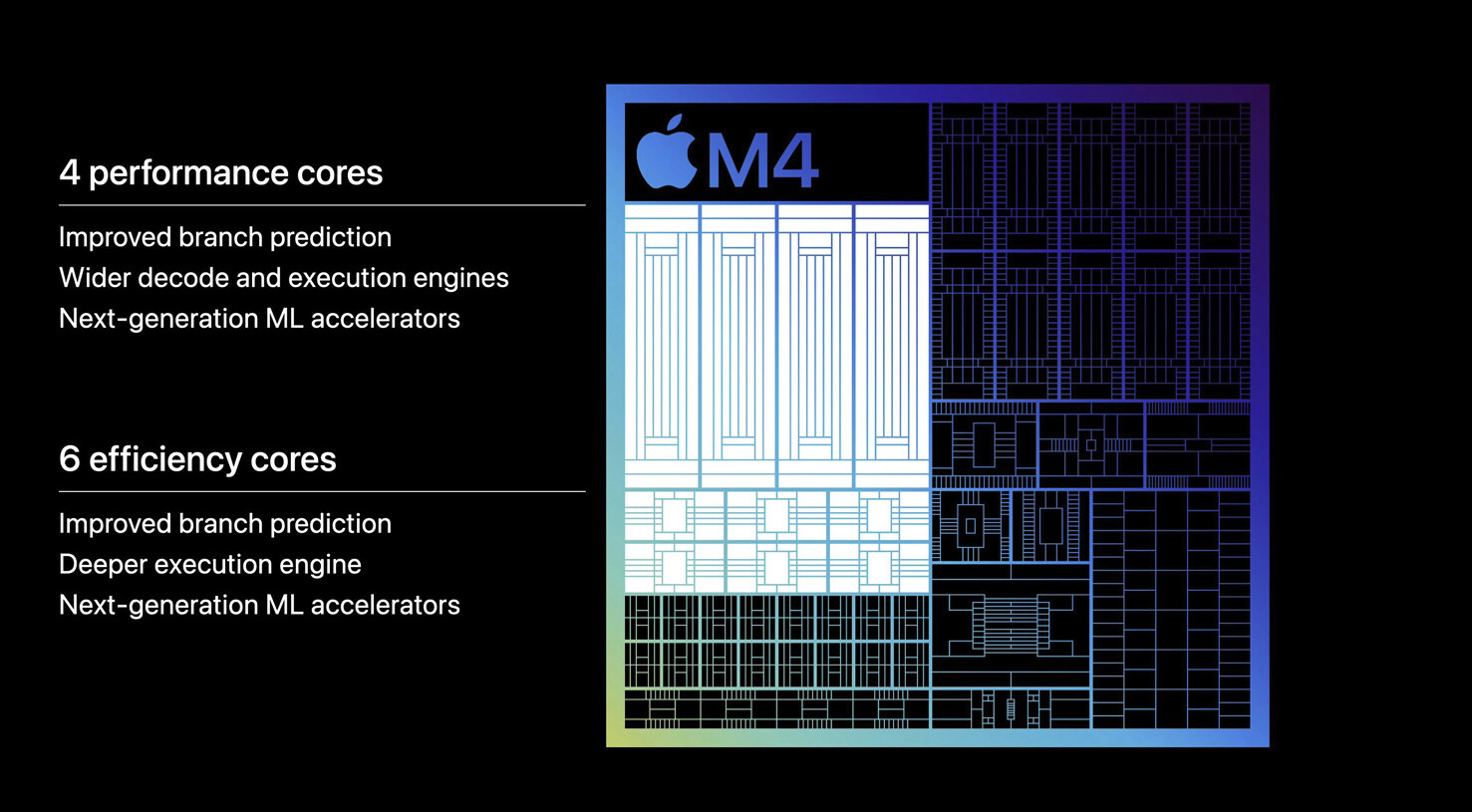
Apple today announced M4, the latest chip delivering phenomenal performance to the all-new iPad Pro. Built using second-generation 3-nanometer technology, M4 is a system on a chip (SoC) that advances the industry-leading power efficiency of Apple silicon and enables the incredibly thin design of iPad Pro. It also features an entirely new display engine to drive the stunning precision, color, and brightness of the breakthrough Ultra Retina XDR display on iPad Pro. A new CPU has up to 10 cores, while the new 10-core GPU builds on the next-generation GPU architecture introduced in M3, and brings Dynamic Caching, hardware-accelerated ray tracing, and hardware-accelerated mesh shading to iPad for the first time. M4 has Apple's fastest Neural Engine ever, capable of up to 38 trillion operations per second, which is faster than the neural processing unit of any AI PC today. Combined with faster memory bandwidth, along with next-generation machine learning (ML) accelerators in the CPU, and a high-performance GPU, M4 makes the new iPad Pro an outrageously powerful device for artificial intelligence.
"The new iPad Pro with M4 is a great example of how building best-in-class custom silicon enables breakthrough products," said Johny Srouji, Apple's senior vice president of Hardware Technologies. "The power-efficient performance of M4, along with its new display engine, makes the thin design and game-changing display of iPad Pro possible, while fundamental improvements to the CPU, GPU, Neural Engine, and memory system make M4 extremely well suited for the latest applications leveraging AI. Altogether, this new chip makes iPad Pro the most powerful device of its kind."




"The new iPad Pro with M4 is a great example of how building best-in-class custom silicon enables breakthrough products," said Johny Srouji, Apple's senior vice president of Hardware Technologies. "The power-efficient performance of M4, along with its new display engine, makes the thin design and game-changing display of iPad Pro possible, while fundamental improvements to the CPU, GPU, Neural Engine, and memory system make M4 extremely well suited for the latest applications leveraging AI. Altogether, this new chip makes iPad Pro the most powerful device of its kind."