 223
223
AMD Radeon Vega GPU Architecture
Conclusion »Next Generation Geometry, Compute, and Pixel Engine



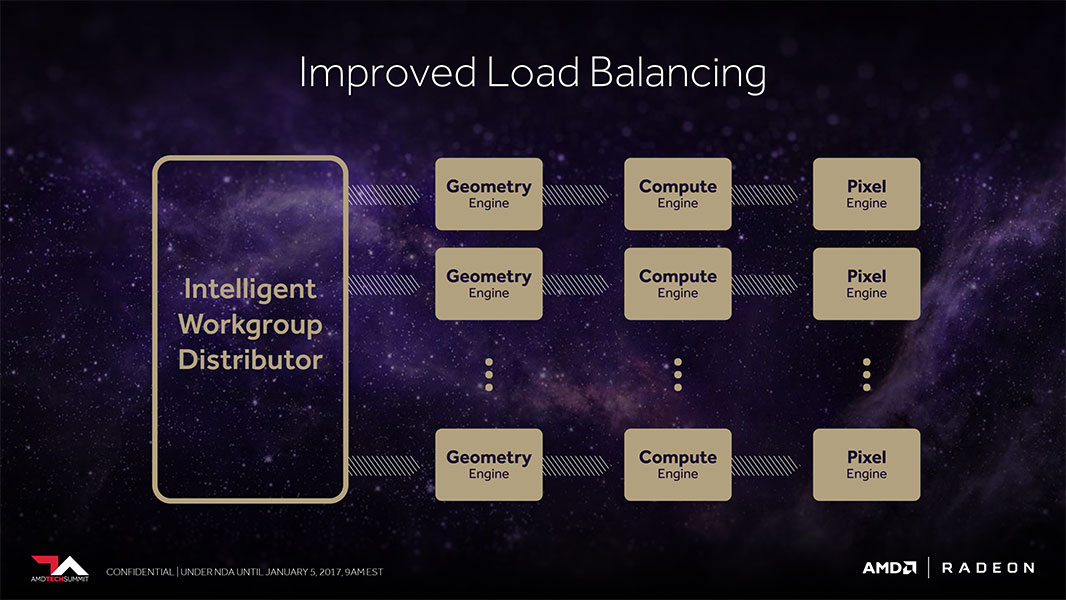
AMD improved the geometry processing machinery available to previous generations with "Vega." The new generation programmable geometry pipeline has over two times the peak throughput per clock. Vega now supports primitive shaders, besides the contemporary vertex and geometry shaders. AMD has also improved the way it distributes workloads between the geometry, compute, and pixel engines. A primitive shader is a new type of low-level shader that gives the developer more freedom to specify all the shading stages they want to use, and run those at a higher rate because they are now decoupled from the traditional DirectX shader pipeline model. While ideally the developer would perform that optimization, AMD also has the ability to use their graphics driver to predefine cases for a game, in which a number of DirectX shaders can be replaced by a single primitive shader for improved performance.


The compute unit (CU) is the basic, heavily parallelized number-crunching machinery of the GPU. With "Vega," AMD improved the functionality of the CUs, which it now calls NCUs (next-generation compute units), by adding support for super-simple 8-bit ops, in addition to the 16-bit ops (FP16) introduced with "Polaris" and the conventional single- and double-precision floating point ops support on older generations. Support for 8-bit ops lets game developers simplify their code, so if it falls within the memory footprint of the 8-bit address space, 512 of them can be crunched per clock cycle.

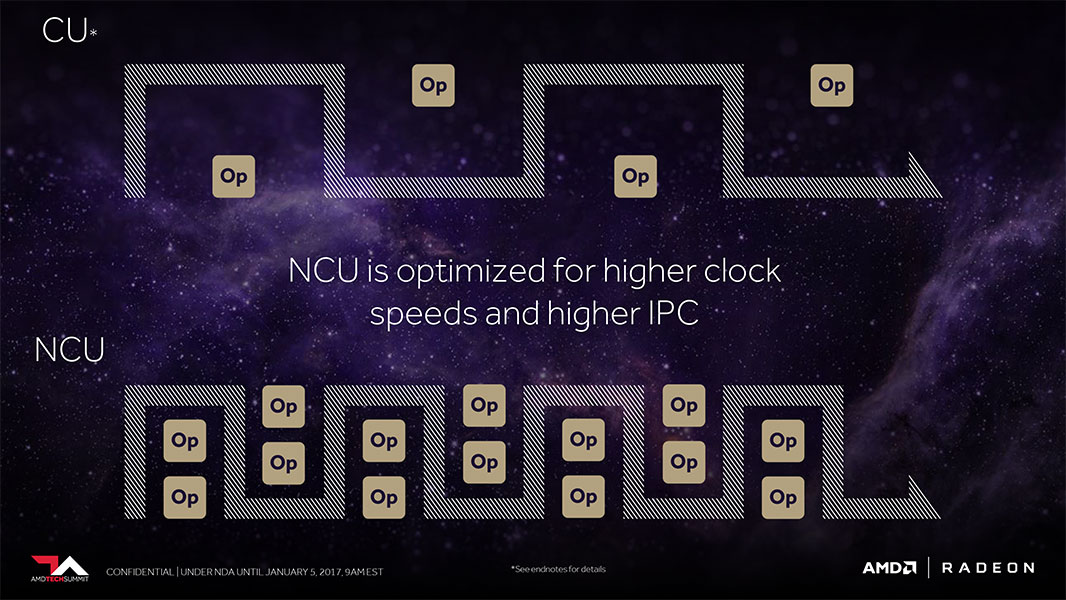
AMD also introduced a new feature called "Rapid Packed Math" in which it clumps multiple 16-bit operations between 32-bit registers for more simple work done per clock. Thanks to these improvements, the Vega NCU is able to crunch four times the operations per clock cycle as the previous generation, as well as run at double the clock speed. AMD has carried over its memory bandwidth-saving lossless compression algorithms. Lastly, AMD improved the pixel-engine with a new-generation draw-stream binning rasterizer. This conserves clock cycles, which helps with on-die cache locality and memory footprint.
AMD changed the hierarchy of the GPU in a way that improves performance of apps that use deferred shading. The geometry pipeline, the compute engine, and and the pixel engine, which output to the ROPs (L1 caches), are now tied to the L2 cache. Earlier, the pixel and texture engines had non-coherent memory access in which the pixel engine wrote to the memory controller.
Apr 18th, 2024 08:03 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- Will a RTX 4070 TI super bottleneck a Ryzen 9 7950X3D? (32)
- Unlocked Realtek HD Audio Drivers for Windows 11 (Dolby Digital Live/DTS Interactive) (152)
- The TPU UK Clubhouse (24726)
- What are you playing? (20453)
- Gigabyte gpu model differences? (33)
- DDR5 RAM Speeds and the future (25)
- [Official] Meta Quest 3 (43)
- Which air cooler for a ryzen 9 5900x (156)
- Realtek Modded Audio Driver for Windows 10/11 - Only for HDAUDIO (5677)
- Your PC ATM (34484)
Popular Reviews
- Horizon Forbidden West Performance Benchmark Review - 30 GPUs Tested
- PowerColor Radeon RX 7900 GRE Hellhound Review
- Fractal Design Terra Review
- Corsair 2000D Airflow Review
- Minisforum EliteMini UM780 XTX (AMD Ryzen 7 7840HS) Review
- Creative Pebble X Plus Review
- FiiO KB3 HiFi Mechanical Keyboard Review - Integrated DAC/Amp!
- ASUS GeForce RTX 4090 STRIX OC Review
- NVIDIA GeForce RTX 4090 Founders Edition Review - Impressive Performance
- ASUS GeForce RTX 4090 Matrix Platinum Review - The RTX 4090 Ti
Controversial News Posts
- Sony PlayStation 5 Pro Specifications Confirmed, Console Arrives Before Holidays (106)
- NVIDIA Points Intel Raptor Lake CPU Users to Get Help from Intel Amid System Instability Issues (102)
- US Government Wants Nuclear Plants to Offload AI Data Center Expansion (98)
- Windows 10 Security Updates to Cost $61 After 2025, $427 by 2028 (82)
- Developers of Outpost Infinity Siege Recommend Underclocking i9-13900K and i9-14900K for Stability on Machines with RTX 4090 (82)
- TechPowerUp Hiring: Reviewers Wanted for Motherboards, Laptops, Gaming Handhelds and Prebuilt Desktops (71)
- Intel Realizes the Only Way to Save x86 is to Democratize it, Reopens x86 IP Licensing (70)
- AMD Zen 5 Execution Engine Leaked, Features True 512-bit FPU (63)