Monday, July 17th 2023

AMD Ryzen 7040 Series Phoenix APUs Surprisingly Performant with AVX-512 Workloads
Intel decided to drop the relatively new AVX-512 instruction set for laptop/mobile platforms when it was discovered that it would not work in conjunction with their E-core designs. Alder Lake was the last generation to (semi) support these sets thanks to P-cores agreeing to play nice, albeit with the efficiency side of proceedings disabled (via BIOS settings). Intel chose to fuse off AVX-512 support in production circa early 2022, with AMD picking up the slack soon after and working on the integration of AVX-512 into Zen 4 CPU architecture. The Ryzen 7040 series is the only current generation mobile platform that offers AVX-512 support. Phoronix decided to benchmark a Ryzen 7 7840U against older Intel i7-1165G7 (Tiger Lake) and i7-1065G7 (Ice Lake) SoCs in AVX-512-based workloads.
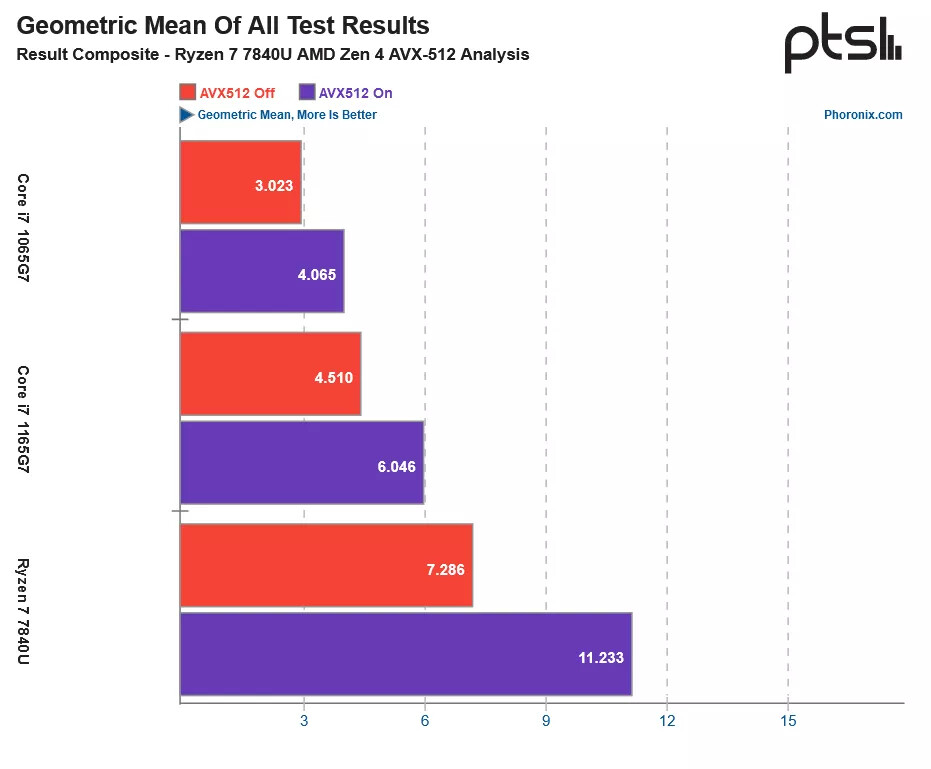
Team Red's debut foray into AVX-512 was surprisingly performant according to Phoronix's test results—the Ryzen 7 7840U did very well for itself. It outperformed the 1165G7 by 46%, and the older 1065G7 by an impressive 63%. The Ryzen 7 APU was found to attain the highest performance gain with AVX-512 enabled—a 54% performance margin over operating with AVX-512 disabled. In comparison Phoronix found that: "the i7-1165G7 Tiger Lake impact came in at 34% with these AVX-512-heavy benchmarks or 35% with the i7-1065G7 Ice Lake SoC for that generation where AVX-512 on Intel laptops became common."

 Phoronix concluded: "Overall the AVX-512 usage across the AMD Zen 4 product spectrum has been great. The efficient AVX-512 usage on the mobile/laptop processors is great for those developers wanting to work and test code from their device, if wanting to use any AI / deep learning software for edge computing or related use-cases, or just enjoying other AVX-512 optimized software from CPU-based renderers to other creator software packages. Those wishing to go through this round of data I collected for Phoenix / Tiger Lake / Ice Lake can find it here with all the individual per-test metrics."
Phoronix concluded: "Overall the AVX-512 usage across the AMD Zen 4 product spectrum has been great. The efficient AVX-512 usage on the mobile/laptop processors is great for those developers wanting to work and test code from their device, if wanting to use any AI / deep learning software for edge computing or related use-cases, or just enjoying other AVX-512 optimized software from CPU-based renderers to other creator software packages. Those wishing to go through this round of data I collected for Phoenix / Tiger Lake / Ice Lake can find it here with all the individual per-test metrics."
Sources:
Tom's Hardware, Phoronix AMD Ryzen 7040 Series Review
Team Red's debut foray into AVX-512 was surprisingly performant according to Phoronix's test results—the Ryzen 7 7840U did very well for itself. It outperformed the 1165G7 by 46%, and the older 1065G7 by an impressive 63%. The Ryzen 7 APU was found to attain the highest performance gain with AVX-512 enabled—a 54% performance margin over operating with AVX-512 disabled. In comparison Phoronix found that: "the i7-1165G7 Tiger Lake impact came in at 34% with these AVX-512-heavy benchmarks or 35% with the i7-1065G7 Ice Lake SoC for that generation where AVX-512 on Intel laptops became common."


10 Comments on AMD Ryzen 7040 Series Phoenix APUs Surprisingly Performant with AVX-512 Workloads
Execution throughput for various operations (Chips and Cheese)
This is why if one is into certain emulation this time around, it would be best to go with AMD CPUs.
I was mostly curious about the implementation as AMD was trying to save space wherever possible, and I was curious about the performance delta. Most Intel desktop processors with AVX-512 had a full-width implementation.
x86 decoders cannot saturate execution units with operations to execute, and using SIMD with longer vector register gives a boost because it requires less commands to decode.