Friday, September 29th 2023

AMD Zen 5 Microarchitecture Referenced in Leaked Slides
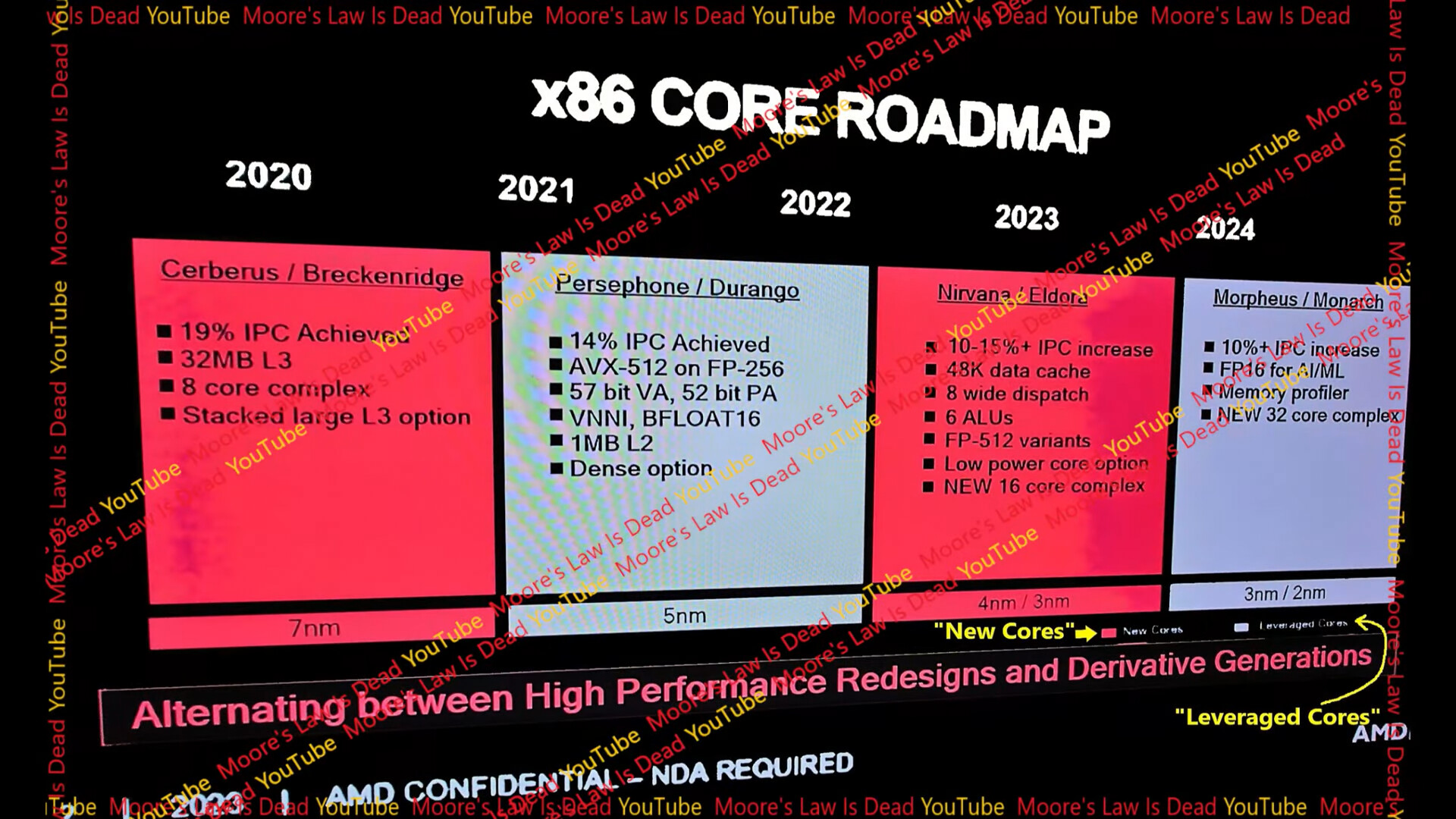
A couple of slides from AMD's internal presentation were leaked to the web by Moore's Law is Dead, referencing what's allegedly the next-generation "Zen 5" microarchitecture. Internally, the performance variant of the "Zen 5" core is referred to as "Nirvana," and the CCD chiplet (CPU core die) based on "Nirvana" cores, is codenamed "Eldora." These CCDs will make up either the company's Ryzen "Granite Ridge" desktop processors, or EPYC "Turin" server processors. The cores themselves could also be part of the company's next-generation mobile processors, as part of heterogenous CCXs (CPU core complex), next to "Zen 5c" low-power cores.
In broad strokes, AMD describes "Zen 5" as introducing a 10% to 15% IPC increase over the current "Zen 4." The core will feature a larger 48 KB L1D cache, compared to the current 32 KB. As for the core itself, it features an 8-wide dispatch from the micro-op queue, compared to the 6-wide dispatch of "Zen 4." The integer execution stage gets 6 ALUs, compared to the current 4. The floating point unit gets FP-512 capabilities. Perhaps the biggest announcement is that AMD has increased the maximum cores per CCX from 8 to 16. At this point we don't know if it means that "Eldora" CCD will have 16 cores, or whether it means that the cloud-specific CCD with 16 "Zen 5c" cores will have 16 cores within a single CCX, rather than spread across two CCXs with smaller L3 caches. AMD is leveraging the TSMC 4 nm EUV node for "Eldora," the mobile processor based on "Zen 5" could be based on the more advanced TSMC 3 nm EUV node.
 The opening slide also provides a fascinating way AMD describes its CPU core architectures. According to this, "Zen 3" and "Zen 5" are new cores, while "Zen 4" and the future "Zen 6" cores are leveraged cores. If you recall, "Zen 3" had provided a massive 19% IPC uplift over "Zen 2," which helped AMD dominate the CPU market. Although with a more conservative 15% IPC gain estimate over "Zen 4," the "Zen 5" core is expected to have as big of an impact on AMD's competitiveness.
The opening slide also provides a fascinating way AMD describes its CPU core architectures. According to this, "Zen 3" and "Zen 5" are new cores, while "Zen 4" and the future "Zen 6" cores are leveraged cores. If you recall, "Zen 3" had provided a massive 19% IPC uplift over "Zen 2," which helped AMD dominate the CPU market. Although with a more conservative 15% IPC gain estimate over "Zen 4," the "Zen 5" core is expected to have as big of an impact on AMD's competitiveness.
Speaking of the "Zen 6" microarchitecture and the "Morpheus" core, AMD is anticipating a 10% IPC increase over "Zen 5," new FP16 capabilities for the core, and a 32-core CCX (maximum core-count). This would see a second round of significant increases in CPU core counts.
Diving deep into the "Zen 5" core, and we see AMD introduce an even more advanced branch prediction unit. If you recall, branch predictor improvements had the largest contribution toward the generational IPC gain of "Zen 4." The new branch predictor comes with zero bubble conditional branches capabilities, accuracy improvements, and a larger BTB (branch target buffer). As we mentioned, the core has a larger 48 KB L1D cache, and an unspecified larger D-TLB. There are throughput improvement across the front-end and load/store stages, with dual basic block fetch units, 8-wide op dispatch/rename; Op Fusion, a 50% increase in ALCs, a deeper execution window, a more capable prefetcher, and updates to the CPU core ISA and security. The dedicated L2 cache per core remains 1 MB in size.
Sources:
cyperalien (Reddit), Moore's Law is Dead (YouTube)
In broad strokes, AMD describes "Zen 5" as introducing a 10% to 15% IPC increase over the current "Zen 4." The core will feature a larger 48 KB L1D cache, compared to the current 32 KB. As for the core itself, it features an 8-wide dispatch from the micro-op queue, compared to the 6-wide dispatch of "Zen 4." The integer execution stage gets 6 ALUs, compared to the current 4. The floating point unit gets FP-512 capabilities. Perhaps the biggest announcement is that AMD has increased the maximum cores per CCX from 8 to 16. At this point we don't know if it means that "Eldora" CCD will have 16 cores, or whether it means that the cloud-specific CCD with 16 "Zen 5c" cores will have 16 cores within a single CCX, rather than spread across two CCXs with smaller L3 caches. AMD is leveraging the TSMC 4 nm EUV node for "Eldora," the mobile processor based on "Zen 5" could be based on the more advanced TSMC 3 nm EUV node.

Speaking of the "Zen 6" microarchitecture and the "Morpheus" core, AMD is anticipating a 10% IPC increase over "Zen 5," new FP16 capabilities for the core, and a 32-core CCX (maximum core-count). This would see a second round of significant increases in CPU core counts.
Diving deep into the "Zen 5" core, and we see AMD introduce an even more advanced branch prediction unit. If you recall, branch predictor improvements had the largest contribution toward the generational IPC gain of "Zen 4." The new branch predictor comes with zero bubble conditional branches capabilities, accuracy improvements, and a larger BTB (branch target buffer). As we mentioned, the core has a larger 48 KB L1D cache, and an unspecified larger D-TLB. There are throughput improvement across the front-end and load/store stages, with dual basic block fetch units, 8-wide op dispatch/rename; Op Fusion, a 50% increase in ALCs, a deeper execution window, a more capable prefetcher, and updates to the CPU core ISA and security. The dedicated L2 cache per core remains 1 MB in size.
111 Comments on AMD Zen 5 Microarchitecture Referenced in Leaked Slides
I still think AMD should be putting more on the CPU die and put an end to this L3 cache starved design. Zen clearly needs more L3 to work properly, and this situation with the glued on L3 is silly. At first it was great, and a novel approach, 2nd time was a little weird, but still fine, but going into the 3rd gen of this, it's clear that it's just a money-making racket, and that the CPU needs this extra cache to work properly. Zen6 will really need a larger L2 cache too, as a 10% IPC increase will be insufficient to counter Intel. Doubling of L2 cache is worth 3-5% IPC uplift, too much to be ignored if all your offering is a 10% uptick. AMD needs at least a 15% IPC uptick each generation.
Quad channel memory support on the Desktop is really needed if we are looking at the possibility of 32 cores on the desktop. AMD's DDR5 memory controller is crap compared to Intel's, so another thing for AMD to fix.
while the chip is produced in 5nm (U$ 17k), they should use even more with 3nm as the yield per wafer is well below expectations
I just wanted to see dual channel(128bit) per module :P
.
10-15% isn't exactly ground breaking!
If a leaker gets something wrong it hangs over them for the rest of time like badge of shame and reason not to trust anything they say, ever.Tapeout.Both are pretty competitive. At least on desktop and mobile. Less so on worstation and server. And if what ever comes out?Not true. Extra L3 can benefit some workloads more than others but more L3 is not universally faster.There is a balance beteween cache size and latency. The bigger the cache, the higher the latency.
Cache increases need to be worked in to design to minimize adverse effects from size increase.Based in Intel's fairy tale leaks?Never going to happen. Quad channel will not come to mainstream. Id say AMD's memory controller is better actually. Atleast there you can run 8000 stable where as with Intel its tough even for experts to get it stable.What kind on "news"? The only way this gets more official is if AMD themselves comes out and confirms it which is never gonna happen.
At best we can expect some sort of teaser for Zen 5 during CES 2024 in January.
Really ? Would you put your money on this? Let's think, Apple depends on iPhone sales... and TSMC has no competition, so there are no options, TSMC can charge whatever it wants and Apple cannot say "no, I'm not going to pay that and I'm going to manufacture my processors at Samsung or intel and lose 30-40% efficiency." it makes no sense.
As far as Zen 5 is concerned, given the list of improvements, a 10% increase in IPC seems rather low. Zen 4 didn't do as many changes and still managed an average of 13%.
Another advantages of having a dedicated die for cache is they are able to squeeze more into the same area since you can use a different libraries.
The IPC gains aren't incredible, but they aren't that bad too. the key thing is the cadence they release, if they get it every 12-18 month, they should remain competitive.
Edit: Somebody is having fun, on multiple sites and sources, with the definition of and counts related to CCX and CCD.
BUBBA!
I think from what i know that the best options would be to have a cache die on top or bellow a CCD using TSV. But we could be surprised. I would be surprised if it's in the I/O die because currently, there is really not enough bandwidth between a CCD and the I/O die to support that. But if they have a new I/O die (Witch i think, from rumors they won't) they could increase the size of the infinity fabric link and maybe put cache there. The thing is that would make that I/O die even bigger reducing the yield of it and maybe killing it's main benefits.
Also i am not sure if there is enough space on the die to put a dedicated cache die that is not stacked. but who know ! i would be very surprised.
Heck If anything I wish the world had more consequences for ffing up.