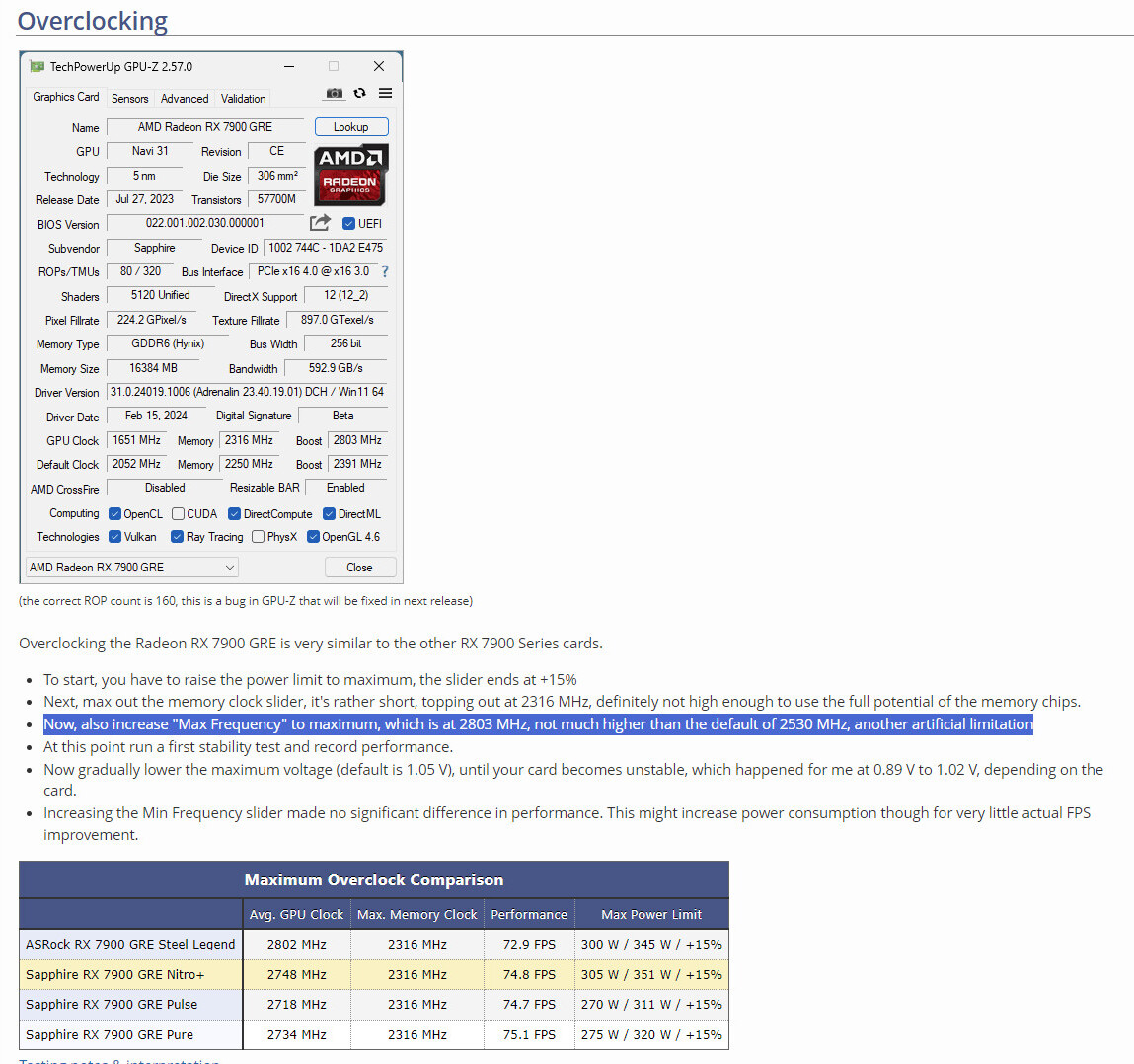
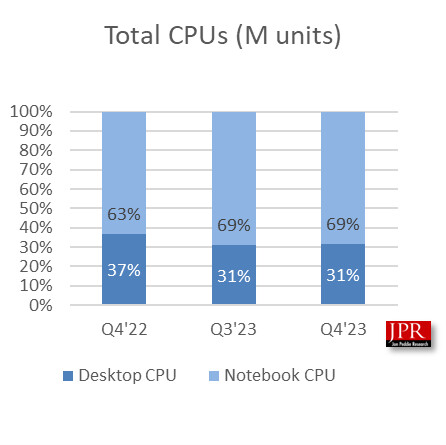
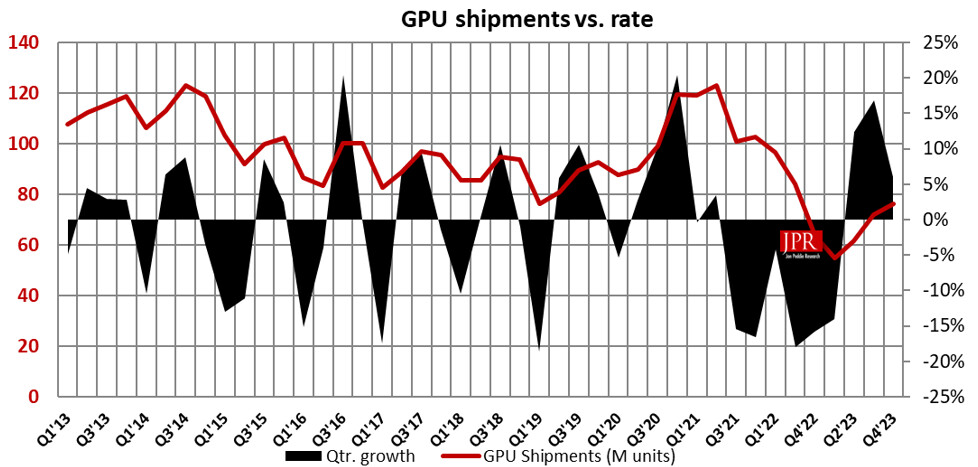
Microsoft's DirectX department
is scheduled to show off several innovations at this month's
Game Developers Conference (GDC), although a
late February preview has already spilled their DirectSR Super Resolution API's beans. Today, retail support for Shader Model 6.8 and Work Graphs has been introduced with an
updated version of the company's Agility Software Development Kit. Program manager, Joshua Tucker, stated that these technologies will be showcased on-stage at GDC 2024—Shader Model 6.8 arrives with a "host of new features for shader developers, including Start Vertex/Instance Location, Wave Size Range, and Expanded Comparison Sampling." A linked supplementary article—
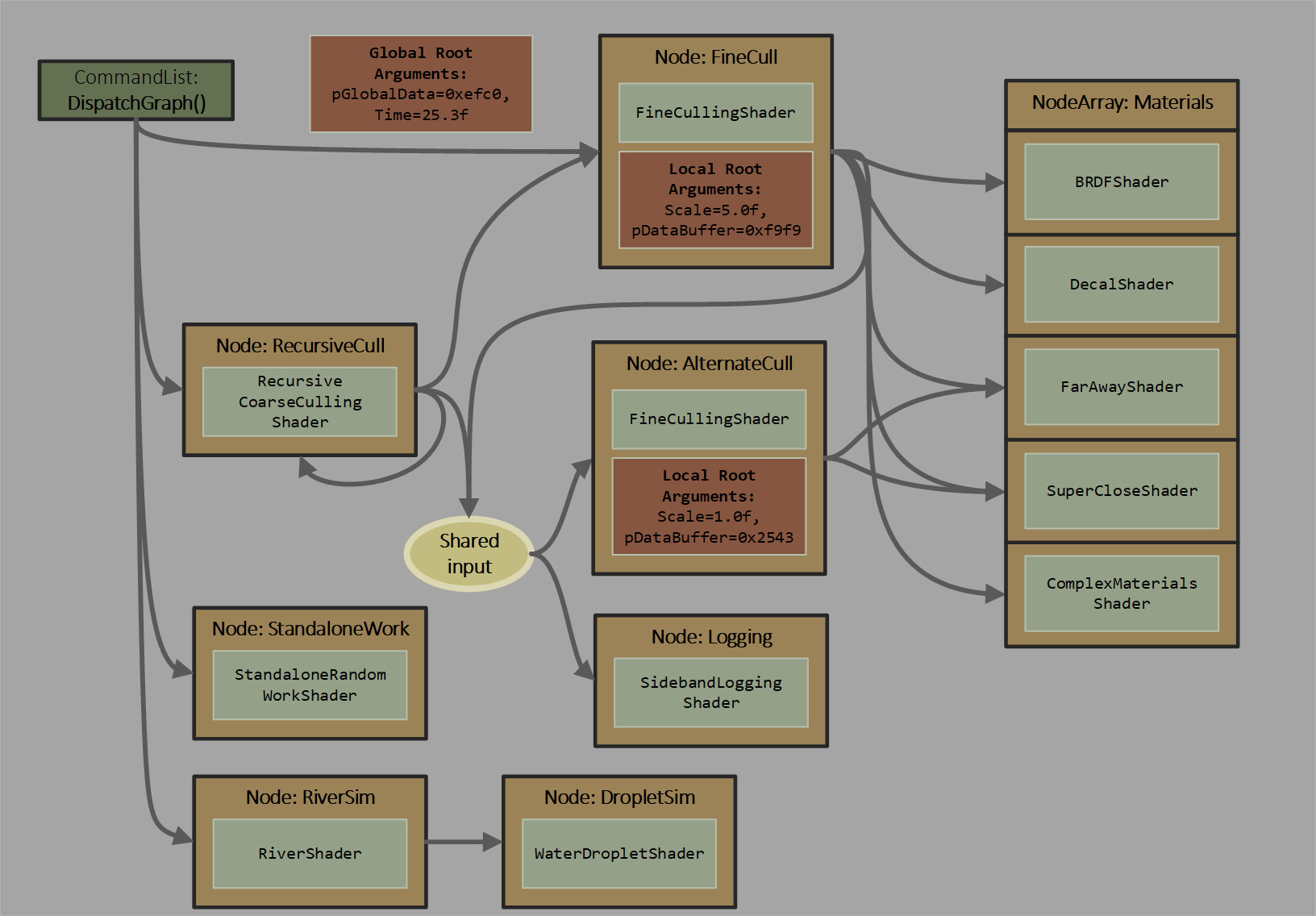
D3D12 Work Graphs—provides an in-depth look into the cutting-edge API's underpinnings, best consumed if you have an hour or two to spare.
Tucker summarized the Work Graphs API: "(it) utilizes the full potential of your GPU. It's not just an upgrade to the existing models, but a whole new paradigm that enables more efficient, flexible, and creative game development. With Work Graphs, you can generate and schedule GPU work on the fly, without relying on the host. This means you can achieve higher performance, lower latency, and greater scalability for your games with tasks such as culling, binning, chaining of compute work, and much more." AMD and NVIDIA are offering driver support on day one. Team Red has discussed the launch of "Microsoft DirectX 12 Work Graphs 1.0 API" in a
GPUOpen blog—they confirm that "a deep dive" into the API will happen during their
Advanced Graphics Summit presentation. NVIDIA's
Wessam Bahnassi has also discussed the significance of Work Graphs—check out his "
Advancing GPU-driven rendering" article.
Graham Wihlidal—of Epic Games—is excited about the latest development: "we have been advocating for something like this for a number of years, and it is very exciting to finally see the release of Work Graphs."