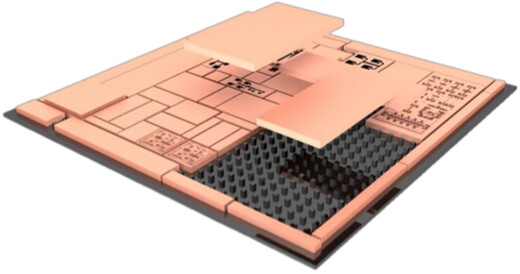
Ceremorphic Exits Stealth Mode; Unveils Technology Plans to Deliver a New Architecture Specifically Designed for Reliable Performance Computing
Armed with more than 100 patents and leveraging multi-decade expertise in creating industry-leading silicon systems, Ceremorphic Inc. today announced its plans to deliver a complete silicon system that provides the performance needed for next-generation applications such as AI model training, HPC, automotive processing, drug discovery, and metaverse processing. Designed in advanced silicon geometry (TSMC 5 nm node), this new architecture was built from the ground up to solve today's high-performance computing problems in reliability, security and energy consumption to serve all performance-demanding market segments.
Ceremorphic was founded in April 2020 by industry-veteran Dr. Venkat Mattela, the Founding CEO of Redpine Signals, which sold its wireless assets to Silicon Labs, Inc. in March 2020 for $308 million. Under his leadership, the team at Redpine Signals delivered breakthrough innovations and industry-first products that led to the development of an ultra-low-power wireless solution that outperformed products from industry giants in the wireless space by as much as 26 times on energy consumption. Ceremorphic leverages its own patented multi-thread processor technology ThreadArch combined with cutting-edge new technology developed by the silicon, algorithm and software engineers currently employed by Ceremorphic. This team is leveraging its deep expertise and patented technology to design an ultra-low-power training supercomputing chip.
Ceremorphic was founded in April 2020 by industry-veteran Dr. Venkat Mattela, the Founding CEO of Redpine Signals, which sold its wireless assets to Silicon Labs, Inc. in March 2020 for $308 million. Under his leadership, the team at Redpine Signals delivered breakthrough innovations and industry-first products that led to the development of an ultra-low-power wireless solution that outperformed products from industry giants in the wireless space by as much as 26 times on energy consumption. Ceremorphic leverages its own patented multi-thread processor technology ThreadArch combined with cutting-edge new technology developed by the silicon, algorithm and software engineers currently employed by Ceremorphic. This team is leveraging its deep expertise and patented technology to design an ultra-low-power training supercomputing chip.