NVIDIA Issues Warning to Upgrade Drivers Due to Security Patches
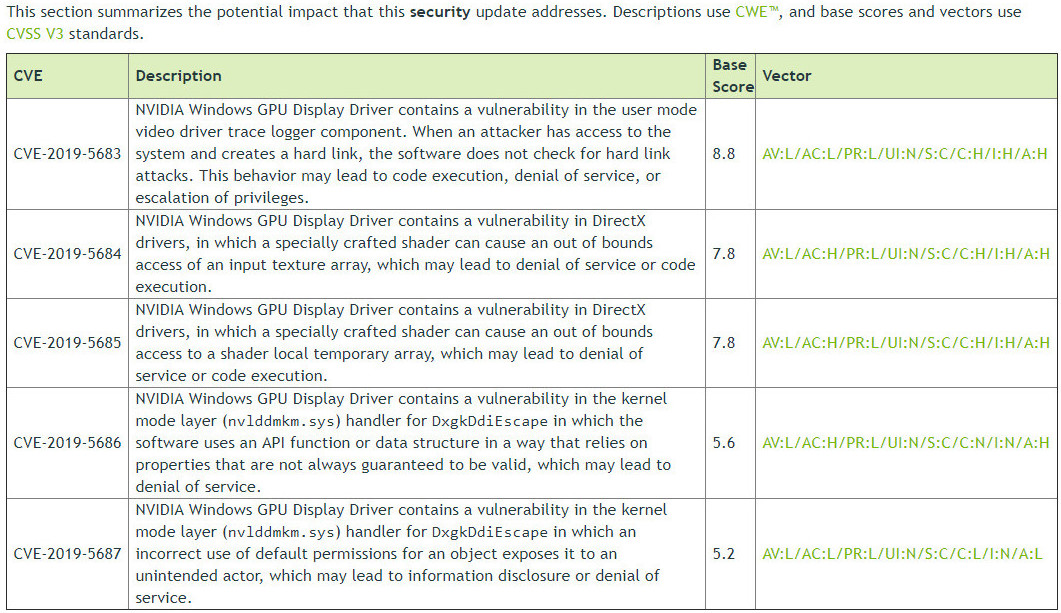
NVIDIA has found a total of five security vulnerabilities with its Windows drivers for GeForce, Quadro and Tesla lineup of graphics cards. These new security risks are labeled as very dangerous and have the potential to cause local code execution, denial of service, or escalation of privileges, unless the system is updated. Users are advised to update their Windows drivers as soon as possible in order to stay secure and avoid all of these vulnerabilities, so be sure to check your drivers for latest version. Exploits are only accessible on Windows based OSes, starting from Windows 7 to Windows 10.
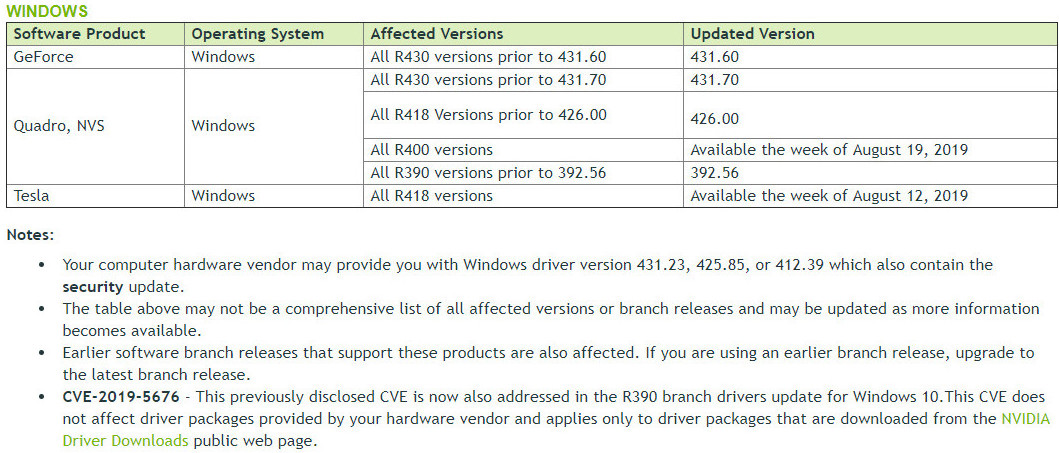
However, one fact that's reassuring is that in order to exploit a system, attacker must have local access to the machine that is running NVIDIA GPU, as remote exploit can not happen. Bellow are the tables provided by NVIDIA that show type of exploit along with rating it carries and which driver versions are affected. There are no mitigations for this exploit, as driver update is the only available solution to secure the system.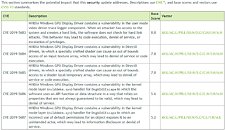

However, one fact that's reassuring is that in order to exploit a system, attacker must have local access to the machine that is running NVIDIA GPU, as remote exploit can not happen. Bellow are the tables provided by NVIDIA that show type of exploit along with rating it carries and which driver versions are affected. There are no mitigations for this exploit, as driver update is the only available solution to secure the system.