Monday, May 29th 2023

TSMC N3 Nodes Show SRAM Scaling is Hitting the Wall
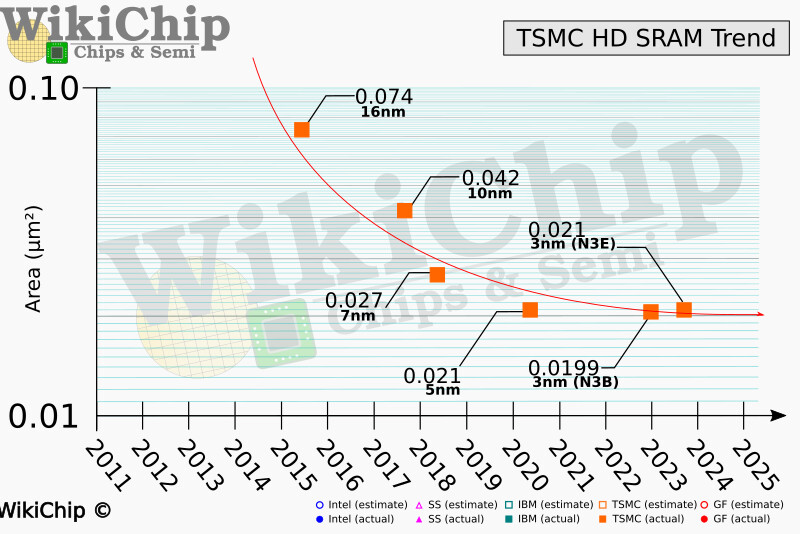
When TSMC introduced its N3 lineup of nodes, the company only talked about the logic scaling of the two new semiconductor manufacturing steps. However, it turns out that there was a reason for it, as WikiChip confirms that the SRAM bit cells of N3 nodes are almost identical to the SRAM bit cells of N5 nodes. At TSMC 2023 Technology Symposium, TSMC presented additional details about its N3 node lineup, including logic and SRAM density. For starters, the N3 node is TSMC's "3 nm" node family that has two products: a Base N3 node (N3B) and an Enhanced N3 node (N3E). The base N3B uses a new (for TSMC) self-aligned contact (SAC) scheme that Intel introduced back in 2011 with a 22 nm node, which improves the node's yield.
Regardless of N3's logic density improvements compared to the "last-generation" N5, the SRAM density is almost identical. Initially, TSMC claimed N3B SRAM density was 1.2x over the N5 process. However, recent information shows that the actual SRAM density is merely a 5% difference. With SRAM taking a large portion of the transistor and area budget of a processor, N3B's soaring manufacturing costs are harder to justify when there is almost no area improvement. For some time, SRAM scaling wasn't following logic scaling; however, the two have now completely decoupled.
Source:
WikiChip
Regardless of N3's logic density improvements compared to the "last-generation" N5, the SRAM density is almost identical. Initially, TSMC claimed N3B SRAM density was 1.2x over the N5 process. However, recent information shows that the actual SRAM density is merely a 5% difference. With SRAM taking a large portion of the transistor and area budget of a processor, N3B's soaring manufacturing costs are harder to justify when there is almost no area improvement. For some time, SRAM scaling wasn't following logic scaling; however, the two have now completely decoupled.
31 Comments on TSMC N3 Nodes Show SRAM Scaling is Hitting the Wall
For well optimized software, few megabytes of cache is sufficient
EDIT: 30 nm is the the fin pitch for TSMC's N7.
First off die would be L3, they're not getting the L1/2 cache's off die, the optic chips or another massive in memory compute evolution is necessary to change that I think.
What is a problem though is heat dissipation, which is why it currently is limited to the LLC of Zen3/4, because of its lower power density compared to the core area.
Still the X3D chips run much hotter due to the structural silicon pieces, but would be even hotter if it was covered with active silicon.
For more information on how these minimium resolutions are calculated, you can look into the Rayleigh Criterion, which is basically what governs all of this in terms of minimum critical dimension
So it will probably take a massive leap in materials technolgy again to get the next "leap" vs just optimising 13.5nm utilisation.
L1 and L2 are nothing compared to the vast expanse of L3.
What seems likely is a "blank area" where the L3 sits currently, with interconnects on-chip but no actual transistors. Then the L3, made on a larger node, is laid in the same area but is considerably higher capacity.
IMO the first-gen GPU chiplet design barely justified the effort, but it ought to improve with subsequent generations.