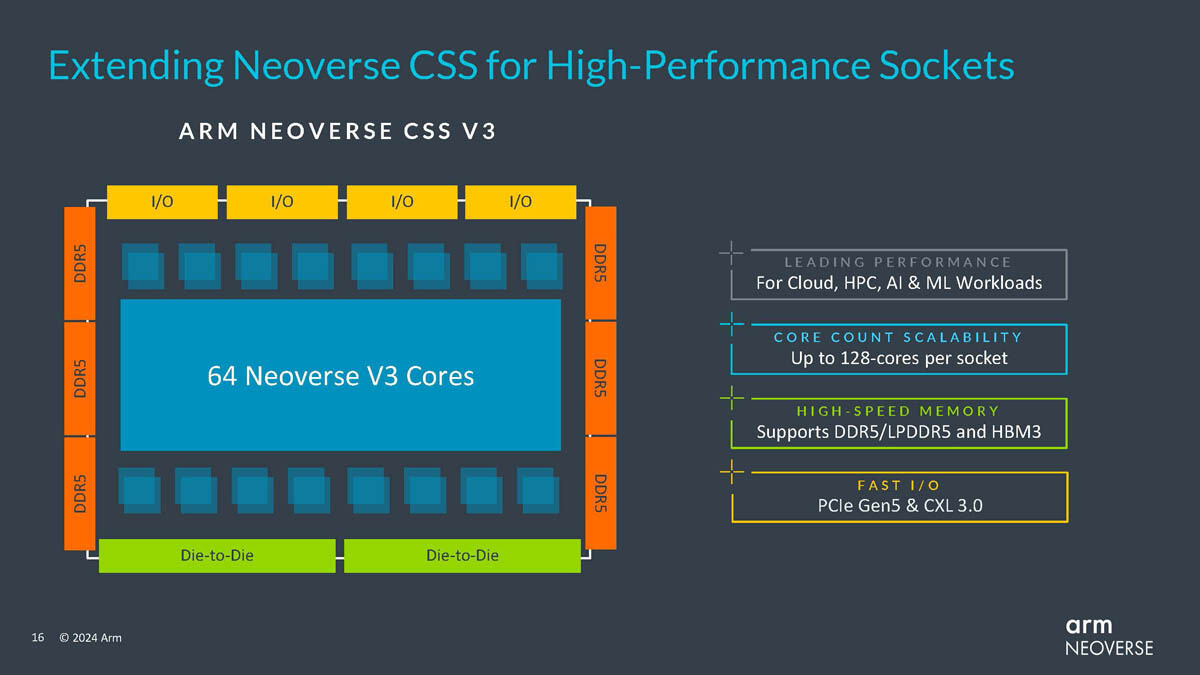
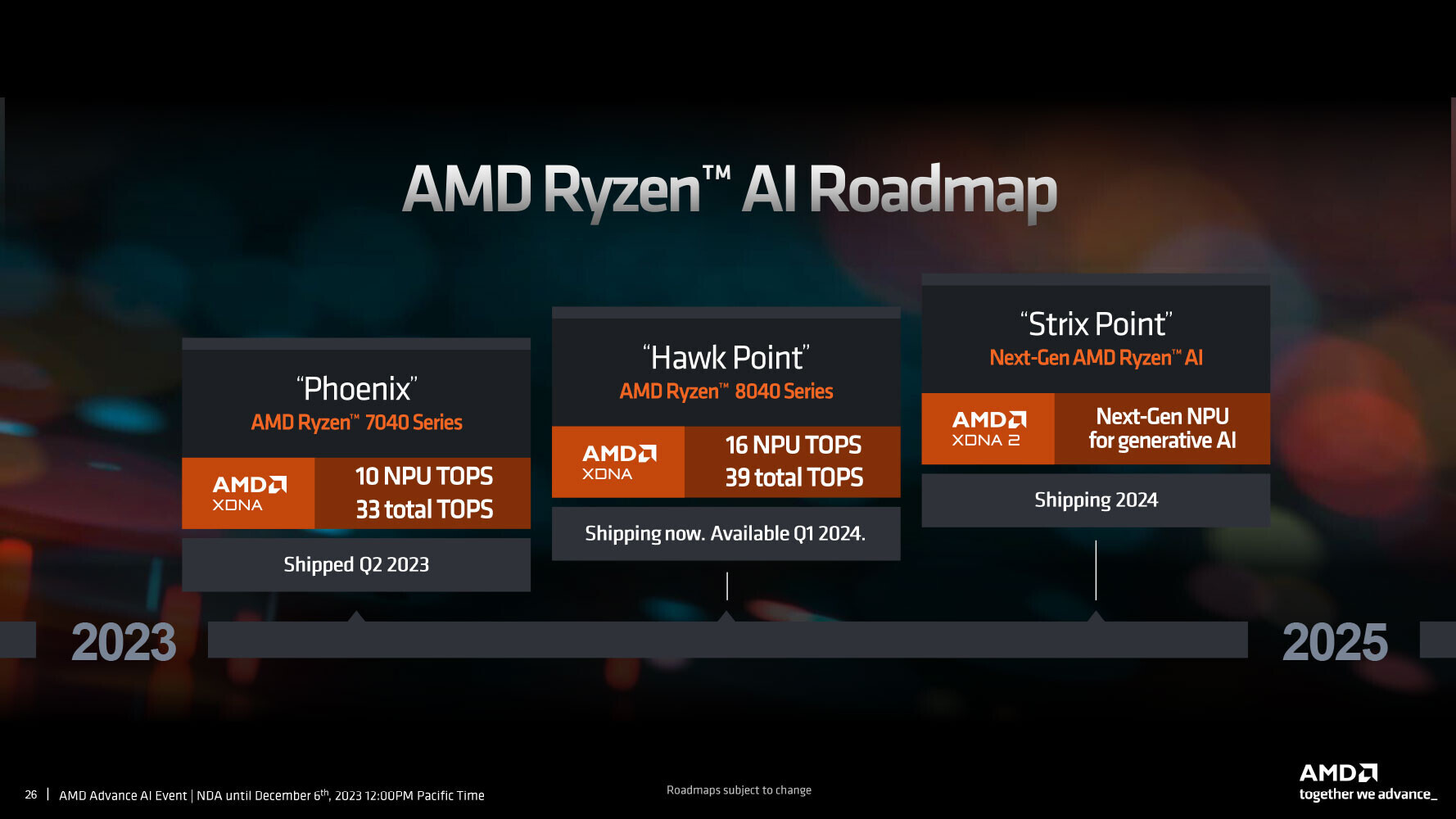
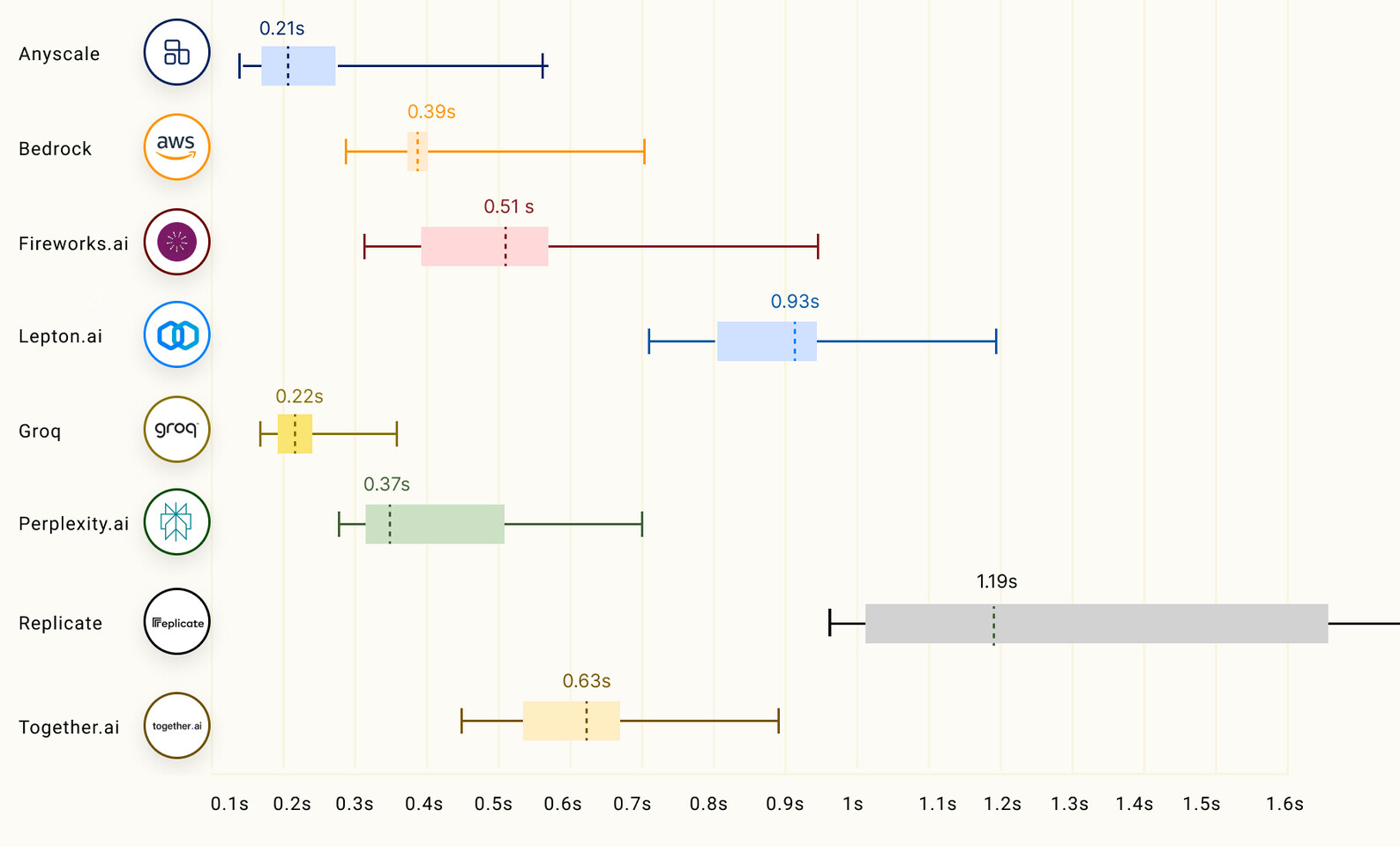
Microsoft Investment in Mistral Attracts Possible Investigation by EU Regulators
Tech giant Microsoft and Paris-based startup Mistral AI, an innovator in open-source AI model development, have announced a new multi-year partnership to accelerate AI innovation and expand access to Mistral's state-of-the-art models. The collaboration will leverage Azure's cutting-edge AI infrastructure to propel Mistral's research and bring its innovations to more customers globally. The partnership focuses on three core areas. First, Microsoft will provide Mistral with Azure AI supercomputing infrastructure to power advanced AI training and inference for Mistral's flagship models like Mistral-Large. Second, the companies will collaborate on AI research and development to push AI model's boundaries. And third, Azure's enterprise capabilities will give Mistral additional opportunities to promote, sell, and distribute their models to Microsoft customers worldwide.
However, an investment in a European startup can not go smoothly without the constant eyesight of the European Union authorities and regulators to oversee the deal. According to Bloomberg, an EU spokesperson on Tuesday claimed that the EU regulators will perform an analysis of Microsoft's investment into Mistral after receiving a copy of the agreement between the two parties. While there is no formal investigation yet, if EU regulators continue to probe Microsoft's deal and intentions, they could launch a complete formal investigation that could lead to the termination of Microsoft's plans. Of course, the formal investigation is still on hold, but investing in EU startups might become unfeasible for American tech giants if the EU regulators continue to push the scrutiny of every investment made in companies based on EU soil.
However, an investment in a European startup can not go smoothly without the constant eyesight of the European Union authorities and regulators to oversee the deal. According to Bloomberg, an EU spokesperson on Tuesday claimed that the EU regulators will perform an analysis of Microsoft's investment into Mistral after receiving a copy of the agreement between the two parties. While there is no formal investigation yet, if EU regulators continue to probe Microsoft's deal and intentions, they could launch a complete formal investigation that could lead to the termination of Microsoft's plans. Of course, the formal investigation is still on hold, but investing in EU startups might become unfeasible for American tech giants if the EU regulators continue to push the scrutiny of every investment made in companies based on EU soil.