Thursday, February 24th 2022

Intel Releases OpenVINO 2022.1 to Advance AI Inferencing for Developers
Since OpenVINO launched in 2018, Intel has enabled hundreds of thousands of developers to dramatically accelerate AI inferencing performance, starting at the edge and extending to the enterprise and the client. Today, ahead of MWC Barcelona 2022, the company launched a new version of the Intel Distribution of OpenVINO Toolkit. New features are built upon three-and-a-half years of developer feedback and include a greater selection of deep learning models, more device portability choices and higher inferencing performance with fewer code changes.
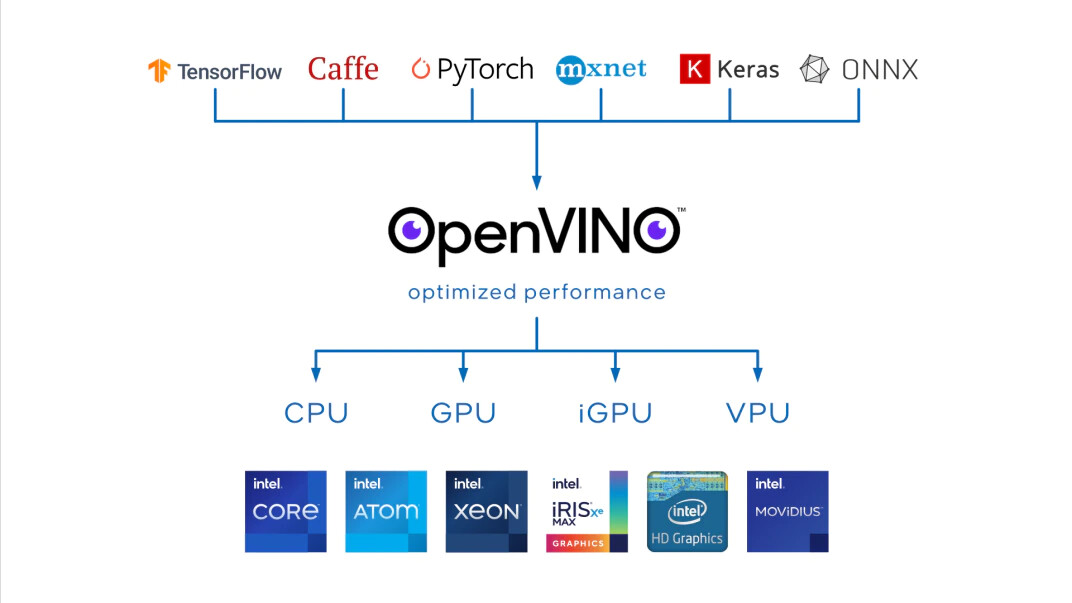
"The latest release of OpenVINO 2022.1 builds on more than three years of learnings from hundreds of thousands of developers to simplify and automate optimizations. The latest upgrade adds hardware auto-discovery and automatic optimization, so software developers can achieve optimal performance on every platform. This software plus Intel silicon enables a significant AI ROI advantage and is deployed easily into the Intel-based solutions in your network," said Adam Burns, vice president, OpenVINO Developer Tools in the Network and Edge Group. The Intel Distribution of OpenVINO toolkit - built on the foundation of oneAPI - is a tool suite for high-performance deep learning, targeted at faster, more accurate real-world results deployed into production across diverse Intel platforms from edge to cloud. OpenVINO enables high-performing applications and algorithms to be deployed in the real world with a streamlined development workflow.
The Intel Distribution of OpenVINO toolkit - built on the foundation of oneAPI - is a tool suite for high-performance deep learning, targeted at faster, more accurate real-world results deployed into production across diverse Intel platforms from edge to cloud. OpenVINO enables high-performing applications and algorithms to be deployed in the real world with a streamlined development workflow.
Edge AI is changing every market, enabling new and enhanced use cases across industries from manufacturing and health and life sciences applications to retail, safety and security. According to research from Omdia, global edge AI chipset revenue will reach $51.9 billion by 2025, driven by the increasing need for AI inference at the edge. Edge inference reduces latency and bandwidth and improves performance to meet the increasingly time-critical processing demands of emerging Internet of Things (IoT) devices and applications.
In parallel, developers' workloads are ever-increasing and changing. As a result, they are calling for simpler, more automated processes and tools with smart, comprehensive capabilities for optimized performance from build to deployment.
New features make it simpler for developers to adopt, maintain, optimize and deploy code with ease across an expanded range of deep learning models. Highlights include:
Updated, cleaner API
"The latest release of OpenVINO 2022.1 builds on more than three years of learnings from hundreds of thousands of developers to simplify and automate optimizations. The latest upgrade adds hardware auto-discovery and automatic optimization, so software developers can achieve optimal performance on every platform. This software plus Intel silicon enables a significant AI ROI advantage and is deployed easily into the Intel-based solutions in your network," said Adam Burns, vice president, OpenVINO Developer Tools in the Network and Edge Group.
Edge AI is changing every market, enabling new and enhanced use cases across industries from manufacturing and health and life sciences applications to retail, safety and security. According to research from Omdia, global edge AI chipset revenue will reach $51.9 billion by 2025, driven by the increasing need for AI inference at the edge. Edge inference reduces latency and bandwidth and improves performance to meet the increasingly time-critical processing demands of emerging Internet of Things (IoT) devices and applications.
In parallel, developers' workloads are ever-increasing and changing. As a result, they are calling for simpler, more automated processes and tools with smart, comprehensive capabilities for optimized performance from build to deployment.
New features make it simpler for developers to adopt, maintain, optimize and deploy code with ease across an expanded range of deep learning models. Highlights include:
Updated, cleaner API
- Fewer code changes when transitioning from frameworks: Precision formats are now preserved with less casting, and models no longer need layout conversion.
- An easier path to faster AI: Model Optimizer's API parameters have been reduced to minimize complexity.
- Train with inferencing in mind: OpenVINO training extensions and neural network compression framework (NNCF) offer optional model training templates that provide additional performance enhancements with preserved accuracy for action recognition, image classification, speech recognition, question answering and translation.
- Broader support for natural language programming models and use cases like text-to-speech and voice recognition: Dynamic shapes support better enables BERT family and Hugging Face transformers.
- Optimization and support for advanced computer vision: Mask R-CNN family is now more optimized and double precision (FP64) model support has been introduced.
- Direct support for PaddlePaddle models: Model Optimizer can now import PaddlePaddle models directly without first converting to another framework.
- Smarter device usage without modifying code: AUTO device mode self-discovers available system inferencing capacity based on model requirements, so applications no longer need to know their compute environment in advance.
- Expert optimization built into the toolkit: Through auto-batching functionality, device performance is increased, automatically tuning and customizing the proper throughput settings for developers' system configuration and deep learning model. The result is scalable parallelism and optimized memory usage.
- Built for 12th Gen Intel Core : Supports the hybrid architecture to deliver enhancements for high-performance inferencing on CPU and integrated GPU.
Comments on Intel Releases OpenVINO 2022.1 to Advance AI Inferencing for Developers
There are no comments yet.