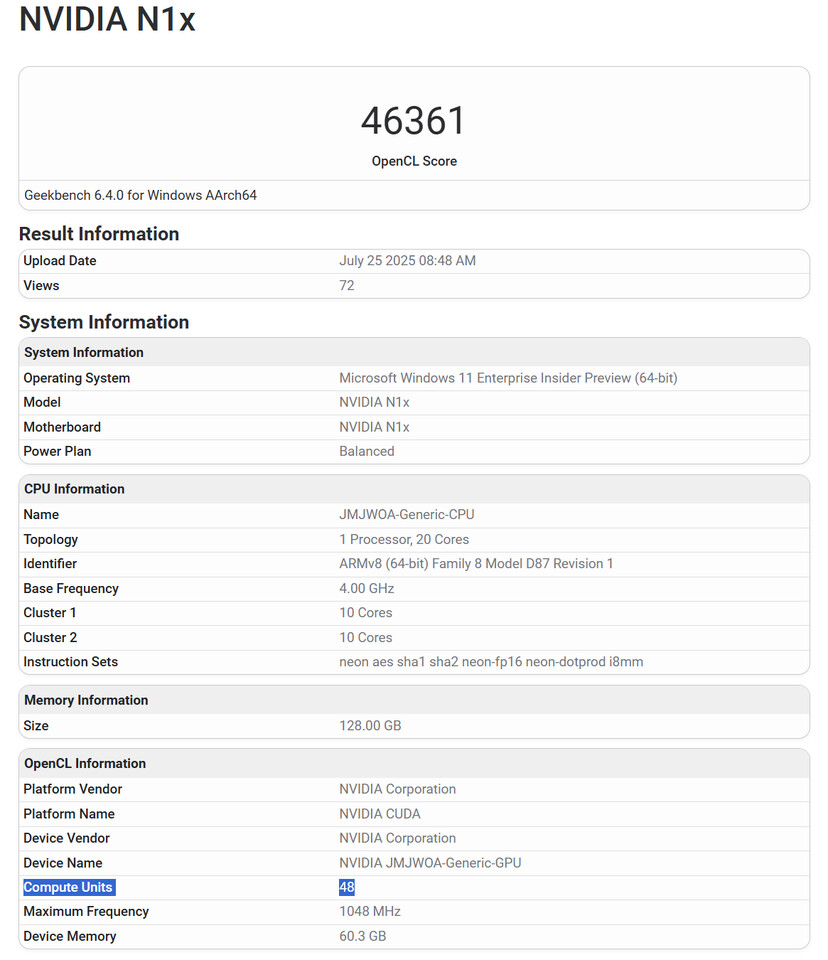
Manli Intros Nebula GeForce RTX 5090 Graphic Cards
Manli introduced its newest high-end graphics card, the Nebula GeForce RTX 5090 powered by the NVIDIA Blackwell architecture. This card is Manli's fourth RTX 5090 version and the first time a flagship GPU model has joined Manli's Nebula lineup alongside the Gallardo and Stellar RTX 5090 series. The Nebula RTX 5090 runs at base and boost clock speeds of 2017 MHz and 2407 MHz respectively. The card has 32 GB of GDDR7 memory with a 512-bit interface providing memory speeds of 28.0 Gbps and bandwidth up to 1,792 GB/s.
The graphics card needs 575 W of power and keeps its GPU temperature at a maximum of 90°C. In terms of cooling it features a large heatsink with a triple cooler setup. This includes three 100 mm fans (which stop spinning during idle states) and nine 6 mm heat pipes. For enhanced aesthetics and structural rigidity Manli's Nebula GeForce RTX 5090 features a die-cast cover and a metal backplate. Connectivity-wise, the graphics card offers three DisplayPort outputs and one HDMI port. It measures 345 x 150 x 65 mm and takes up 3.5 slots. It's worth noting that this model is intended for international markets, unlike the 5090 D variants that Manli offers specifically to the Chinese market. Exact pricing and availability are yet to be known.



The graphics card needs 575 W of power and keeps its GPU temperature at a maximum of 90°C. In terms of cooling it features a large heatsink with a triple cooler setup. This includes three 100 mm fans (which stop spinning during idle states) and nine 6 mm heat pipes. For enhanced aesthetics and structural rigidity Manli's Nebula GeForce RTX 5090 features a die-cast cover and a metal backplate. Connectivity-wise, the graphics card offers three DisplayPort outputs and one HDMI port. It measures 345 x 150 x 65 mm and takes up 3.5 slots. It's worth noting that this model is intended for international markets, unlike the 5090 D variants that Manli offers specifically to the Chinese market. Exact pricing and availability are yet to be known.