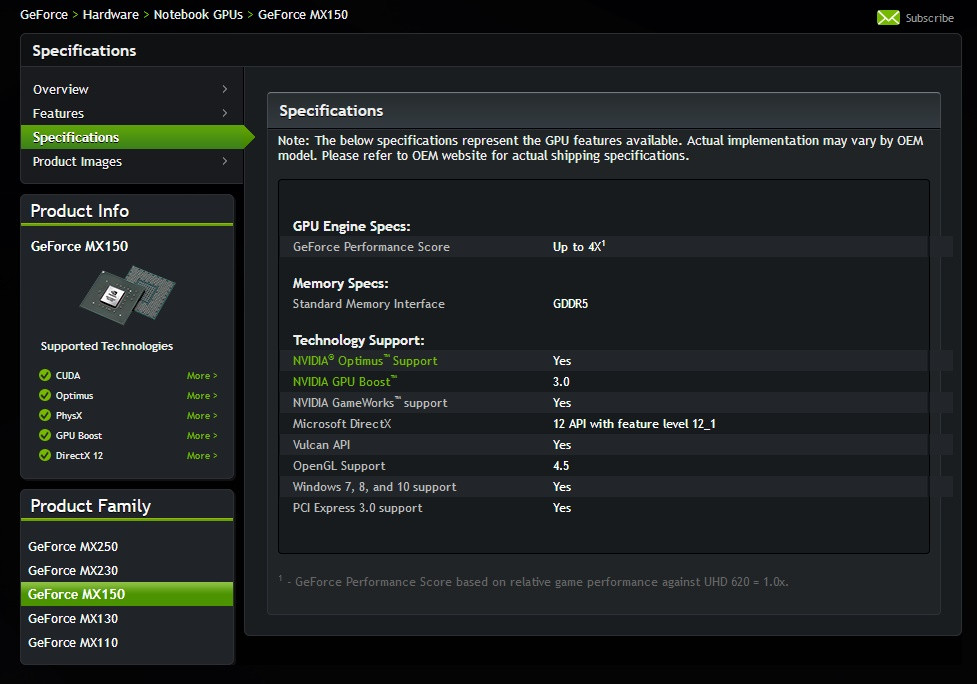
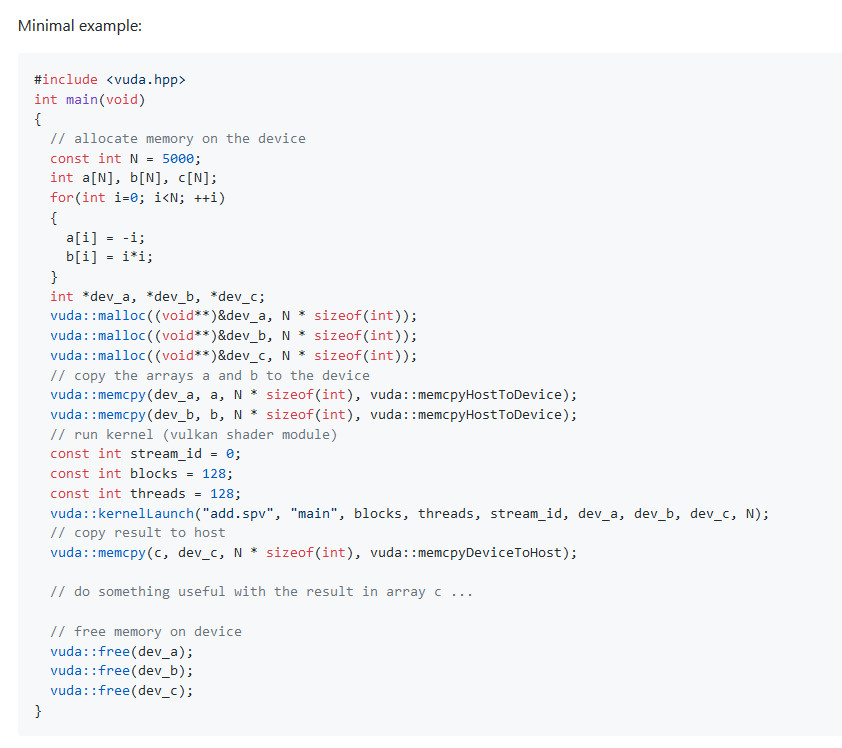
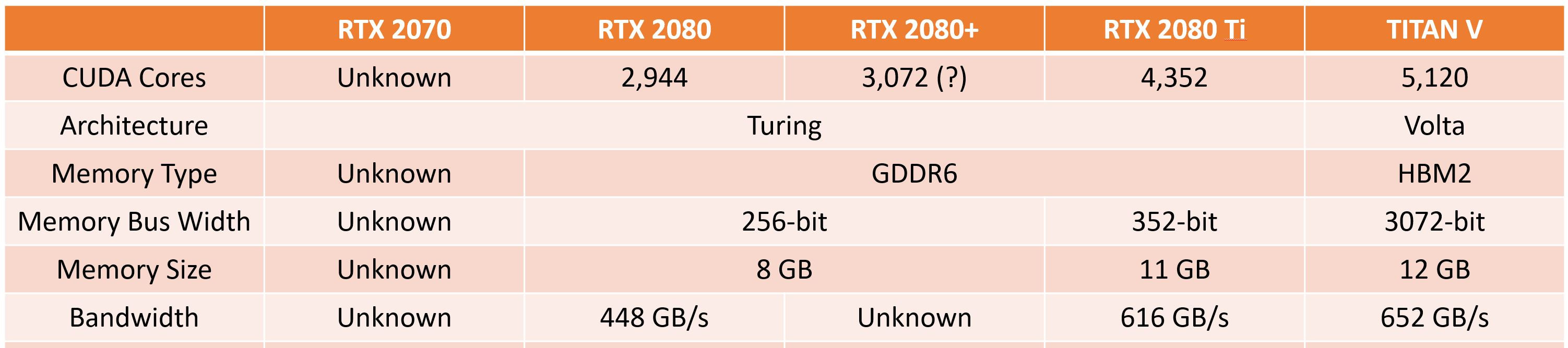
Dynics Announces AI-enabled Vision System Powered by NVIDIA T4 Tensor Core GPU
Dynics, Inc., a U.S.-based manufacturer of industrial-grade computer hardware, visualization software, network security, network monitoring and software-defined networking solutions, today announced the XiT4 Inference Server, which helps industrial manufacturing companies increase their yield and provide more consistent manufacturing quality.
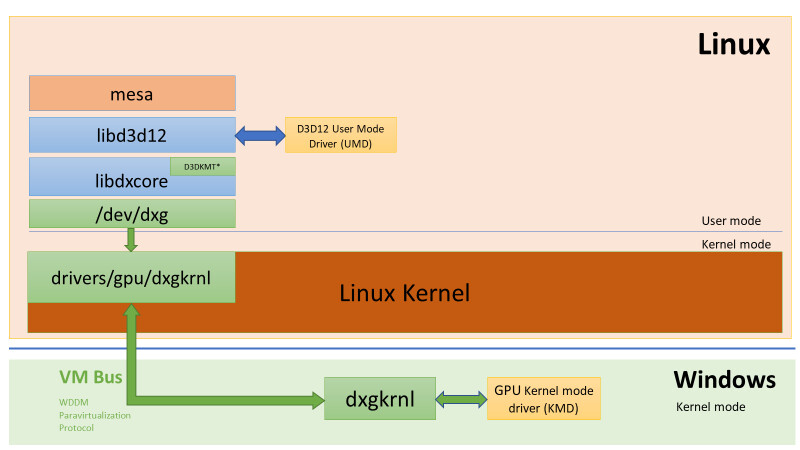
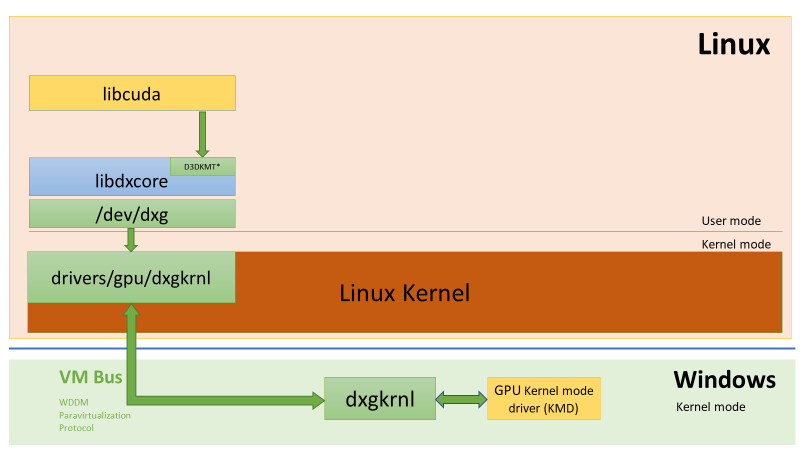
Artificial intelligence (AI) is increasingly being integrated into modern manufacturing to improve and automate processes, including 3D vision applications. The XiT4 Inference Server, powered by the NVIDIA T4 Tensor Core GPUs, is a fan-less hardware platform for AI, machine learning and 3D vision applications. AI technology is allowing manufacturers to increase efficiency and throughput of their production, while also providing more consistent quality due to higher accuracy and repeatability. Additional benefits are fewer false negatives (test escapes) and fewer false positives, which reduce downstream re-inspection needs, all leading to lower costs of manufacturing.
Artificial intelligence (AI) is increasingly being integrated into modern manufacturing to improve and automate processes, including 3D vision applications. The XiT4 Inference Server, powered by the NVIDIA T4 Tensor Core GPUs, is a fan-less hardware platform for AI, machine learning and 3D vision applications. AI technology is allowing manufacturers to increase efficiency and throughput of their production, while also providing more consistent quality due to higher accuracy and repeatability. Additional benefits are fewer false negatives (test escapes) and fewer false positives, which reduce downstream re-inspection needs, all leading to lower costs of manufacturing.