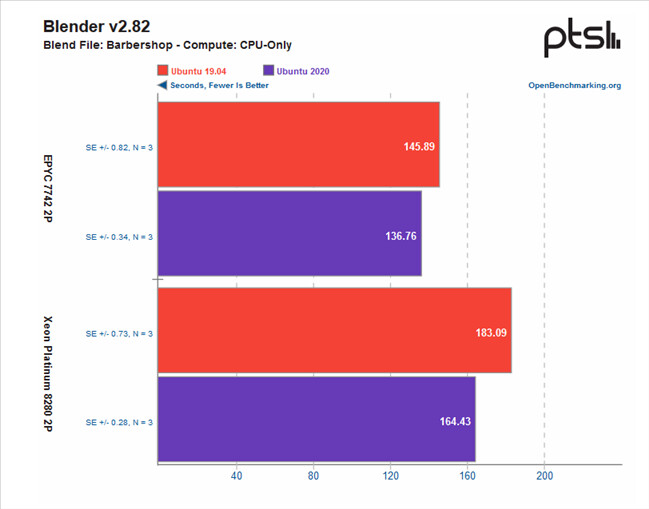
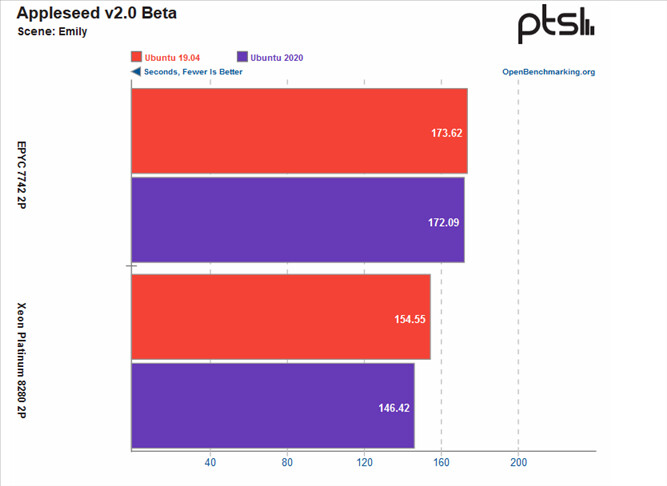
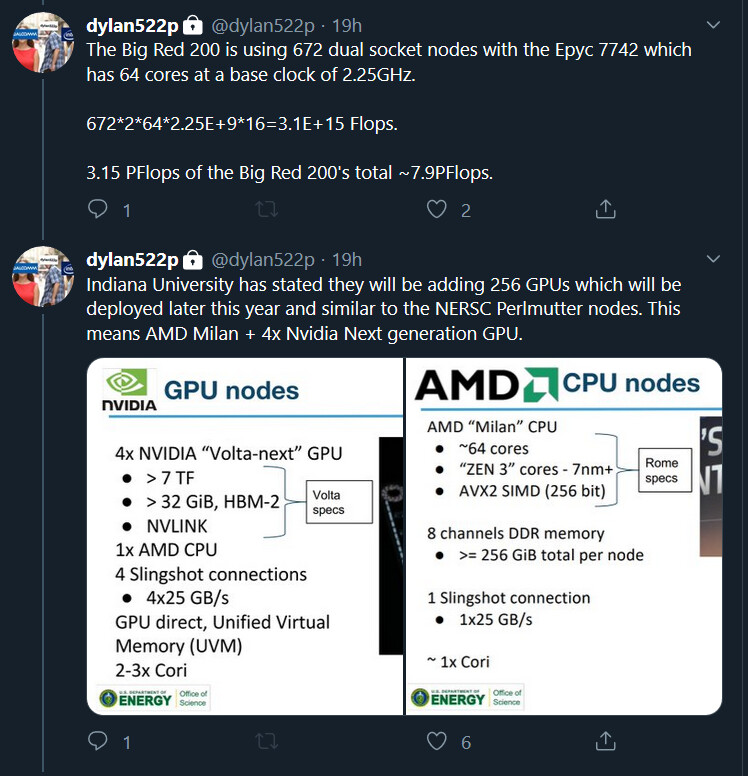
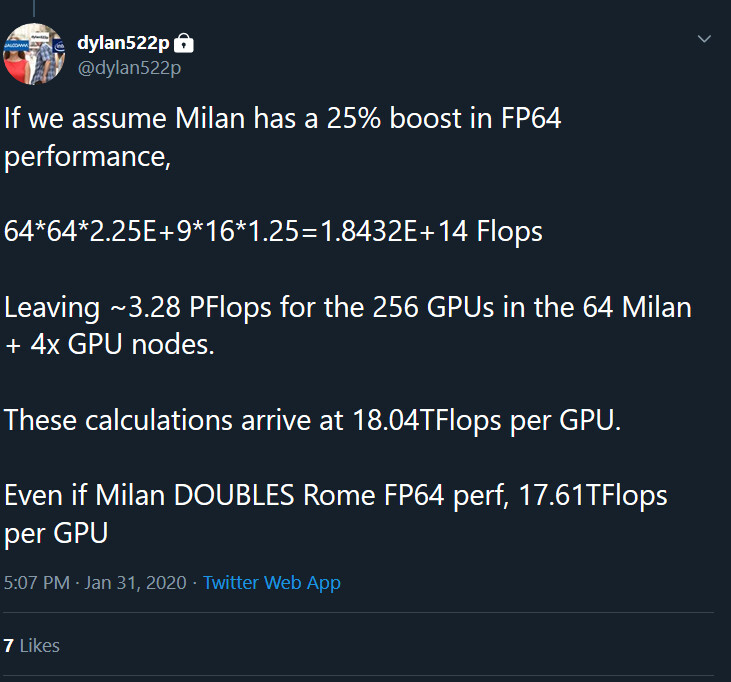
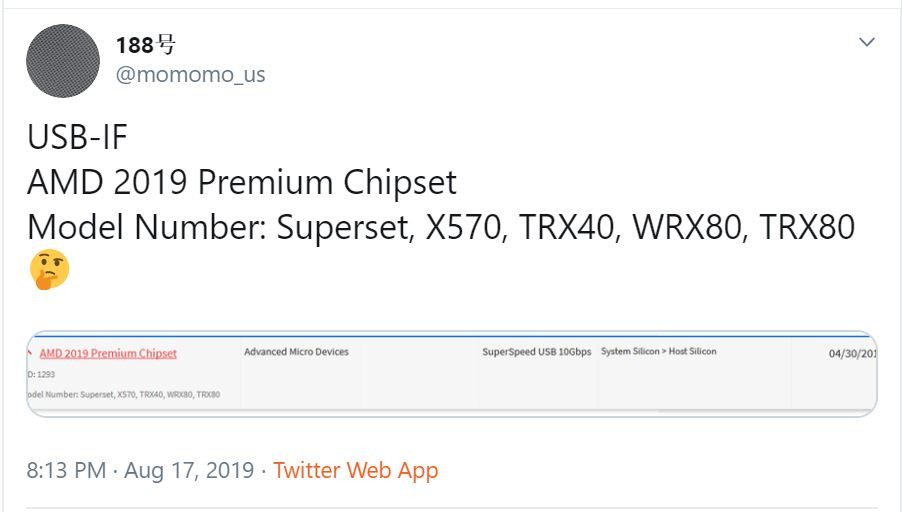
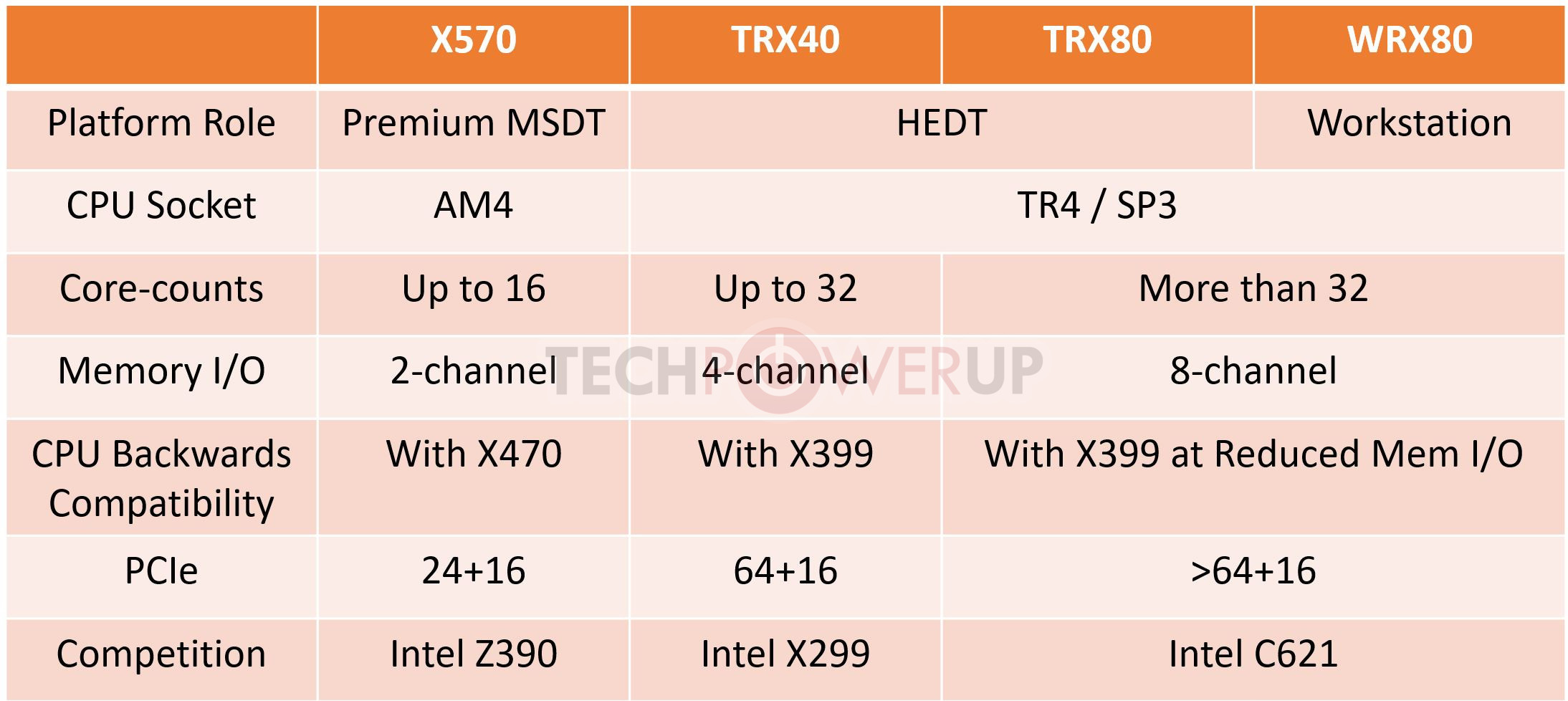
AMD Response to "ZENHAMMER: Rowhammer Attacks on AMD Zen-Based Platforms"
On February 26, 2024, AMD received new research related to an industry-wide DRAM issue documented in "ZENHAMMER: Rowhammering Attacks on AMD Zen-based Platforms" from researchers at ETH Zurich. The research demonstrates performing Rowhammer attacks on DDR4 and DDR5 memory using AMD "Zen" platforms. Given the history around Rowhammer, the researchers do not consider these rowhammering attacks to be a new issue.
Mitigation
AMD continues to assess the researchers' claim of demonstrating Rowhammer bit flips on a DDR5 device for the first time. AMD will provide an update upon completion of its assessment.
Mitigation
AMD continues to assess the researchers' claim of demonstrating Rowhammer bit flips on a DDR5 device for the first time. AMD will provide an update upon completion of its assessment.