Tuesday, April 6th 2021

Intel Announces 10 nm Third Gen Xeon Scalable Processors "Ice Lake"
Intel today launched its most advanced, highest performance data center platform optimized to power the industry's broadest range of workloads—from the cloud to the network to the intelligent edge. New 3rd Gen Intel Xeon Scalable processors (code-named "Ice Lake") are the foundation of Intel's data center platform, enabling customers to capitalize on some of the most significant business opportunities today by leveraging the power of AI.
New 3rd Gen Intel Xeon Scalable processors deliver a significant performance increase compared with the prior generation, with an average 46% improvement on popular data center workloads. The processors also add new and enhanced platform capabilities including Intel SGX for built-in security, and Intel Crypto Acceleration and Intel DL Boost for AI acceleration. These new capabilities, combined with Intel's broad portfolio of Intel Select Solutions and Intel Market Ready Solutions, enable customers to accelerate deployments across cloud, AI, enterprise, HPC, networking, security and edge applications.


 "Our 3rd Gen Intel Xeon Scalable platform is the most flexible and performant in our history, designed to handle the diversity of workloads from the cloud to the network to the edge," said Navin Shenoy, executive vice president and general manager of the Data Platforms Group at Intel. "Intel is uniquely positioned with the architecture, design and manufacturing to deliver the breadth of intelligent silicon and solutions our customers demand."
"Our 3rd Gen Intel Xeon Scalable platform is the most flexible and performant in our history, designed to handle the diversity of workloads from the cloud to the network to the edge," said Navin Shenoy, executive vice president and general manager of the Data Platforms Group at Intel. "Intel is uniquely positioned with the architecture, design and manufacturing to deliver the breadth of intelligent silicon and solutions our customers demand."
3rd Gen Intel Xeon Scalable Processors
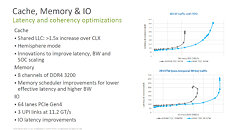
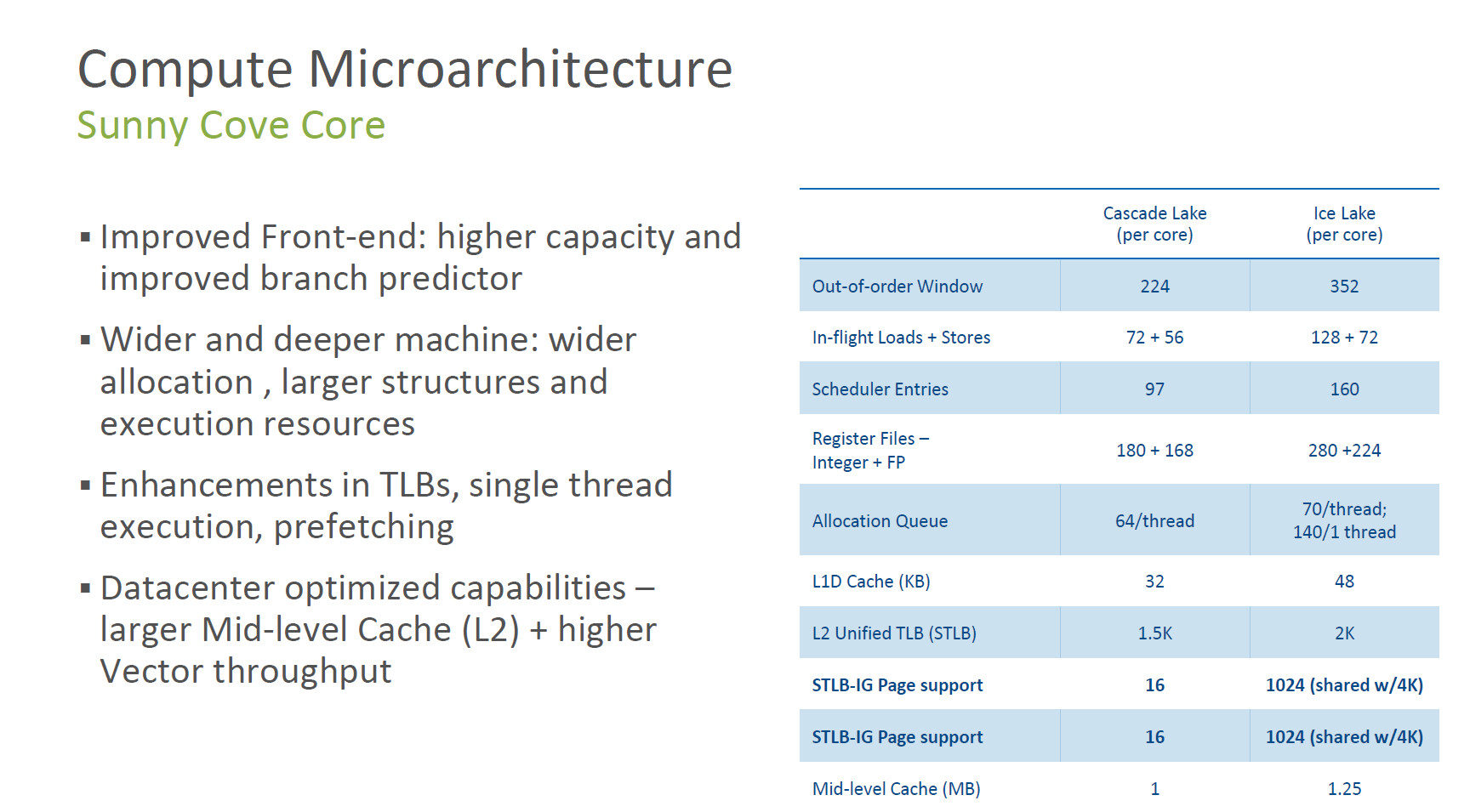
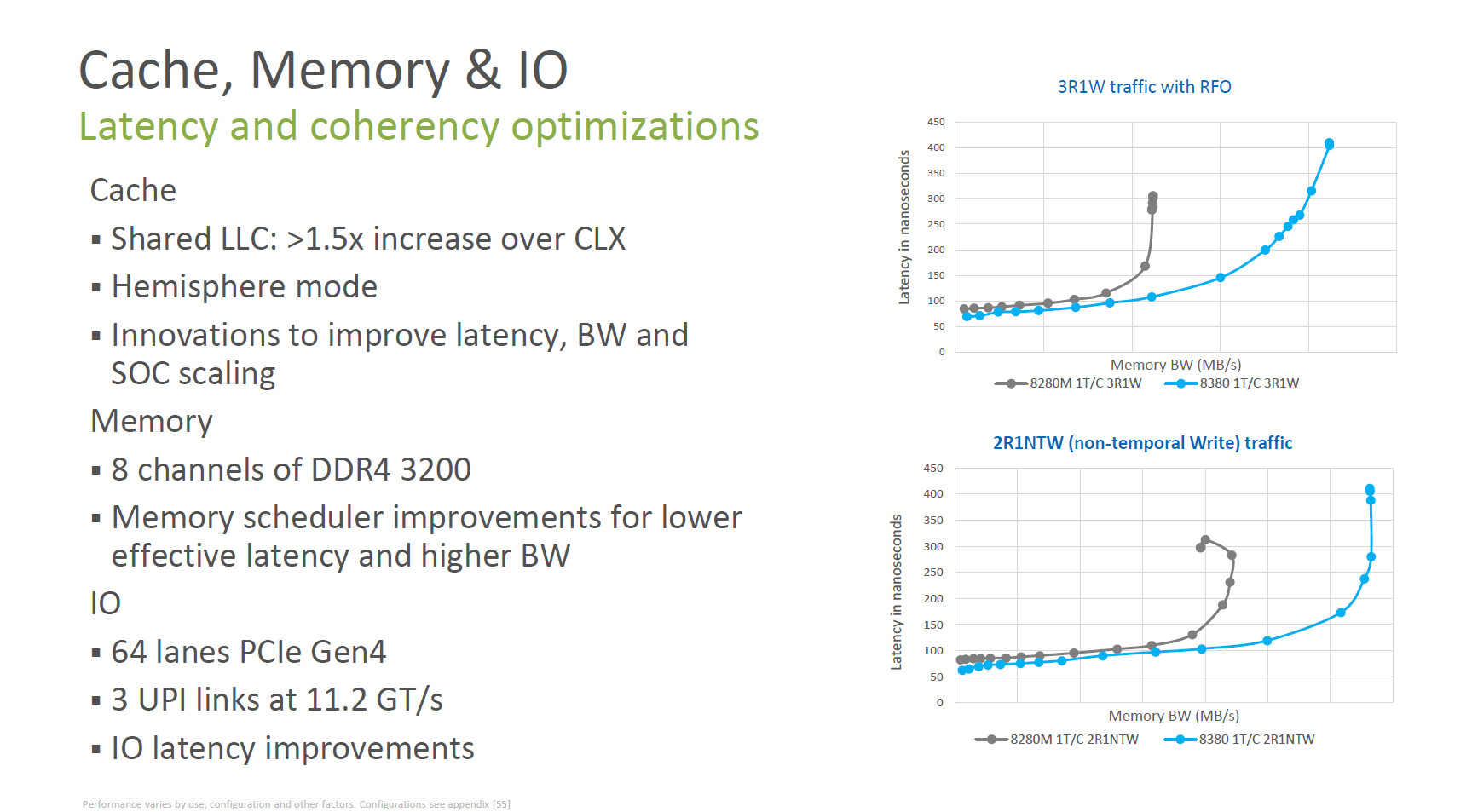
Leveraging Intel 10 nanometer (nm) process technology, the latest 3rd Gen Intel Xeon Scalable processors deliver up to 40 cores per processor and up to 2.65 times higher average performance gain compared with a 5-year-old system. The platform supports up to 6 terabytes of system memory per socket, up to 8 channels of DDR4-3200 memory per socket and up to 64 lanes of PCIe Gen4 per socket.
New 3rd Gen Intel Xeon Scalable processors are optimized for modern workloads that run in both on-premise and distributed multicloud environments. The processors provide customers with a flexible architecture including built-in acceleration and advanced security capabilities, leveraging decades of innovation.
Intel Xeon Scalable processors are supported by more than 500 ready-to-deploy Intel IoT Market Ready Solutions and Intel Select Solutions that help to accelerate customer deployments—with up to 80% of our Intel Select Solutions being refreshed by end of year.
Industry-Leading Data Center Platform
Intel's data center platforms are the most pervasive on the market, with unmatched capabilities to move, store and process data. The latest 3rd Gen Intel Xeon Scalable platform includes the Intel Optane persistent memory 200 series, Intel Optane Solid State Drive (SSD) P5800X and Intel SSD D5-P5316 NAND SSDs, as well as Intel Ethernet 800 Series Network Adapters and the latest Intel Agilex FPGAs. Additional information about all these is available in the 3rd Gen Intel Xeon Scalable platform product fact sheet.
Delivering Flexible Performance Across Cloud, Networking and Intelligent Edge
Our latest 3rd Gen Xeon Scalable platform is optimized for a wide range of market segments—from the cloud to the intelligent edge.






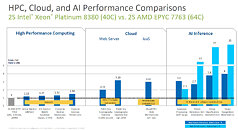


New 3rd Gen Intel Xeon Scalable processors deliver a significant performance increase compared with the prior generation, with an average 46% improvement on popular data center workloads. The processors also add new and enhanced platform capabilities including Intel SGX for built-in security, and Intel Crypto Acceleration and Intel DL Boost for AI acceleration. These new capabilities, combined with Intel's broad portfolio of Intel Select Solutions and Intel Market Ready Solutions, enable customers to accelerate deployments across cloud, AI, enterprise, HPC, networking, security and edge applications.




3rd Gen Intel Xeon Scalable Processors
Leveraging Intel 10 nanometer (nm) process technology, the latest 3rd Gen Intel Xeon Scalable processors deliver up to 40 cores per processor and up to 2.65 times higher average performance gain compared with a 5-year-old system. The platform supports up to 6 terabytes of system memory per socket, up to 8 channels of DDR4-3200 memory per socket and up to 64 lanes of PCIe Gen4 per socket.
New 3rd Gen Intel Xeon Scalable processors are optimized for modern workloads that run in both on-premise and distributed multicloud environments. The processors provide customers with a flexible architecture including built-in acceleration and advanced security capabilities, leveraging decades of innovation.
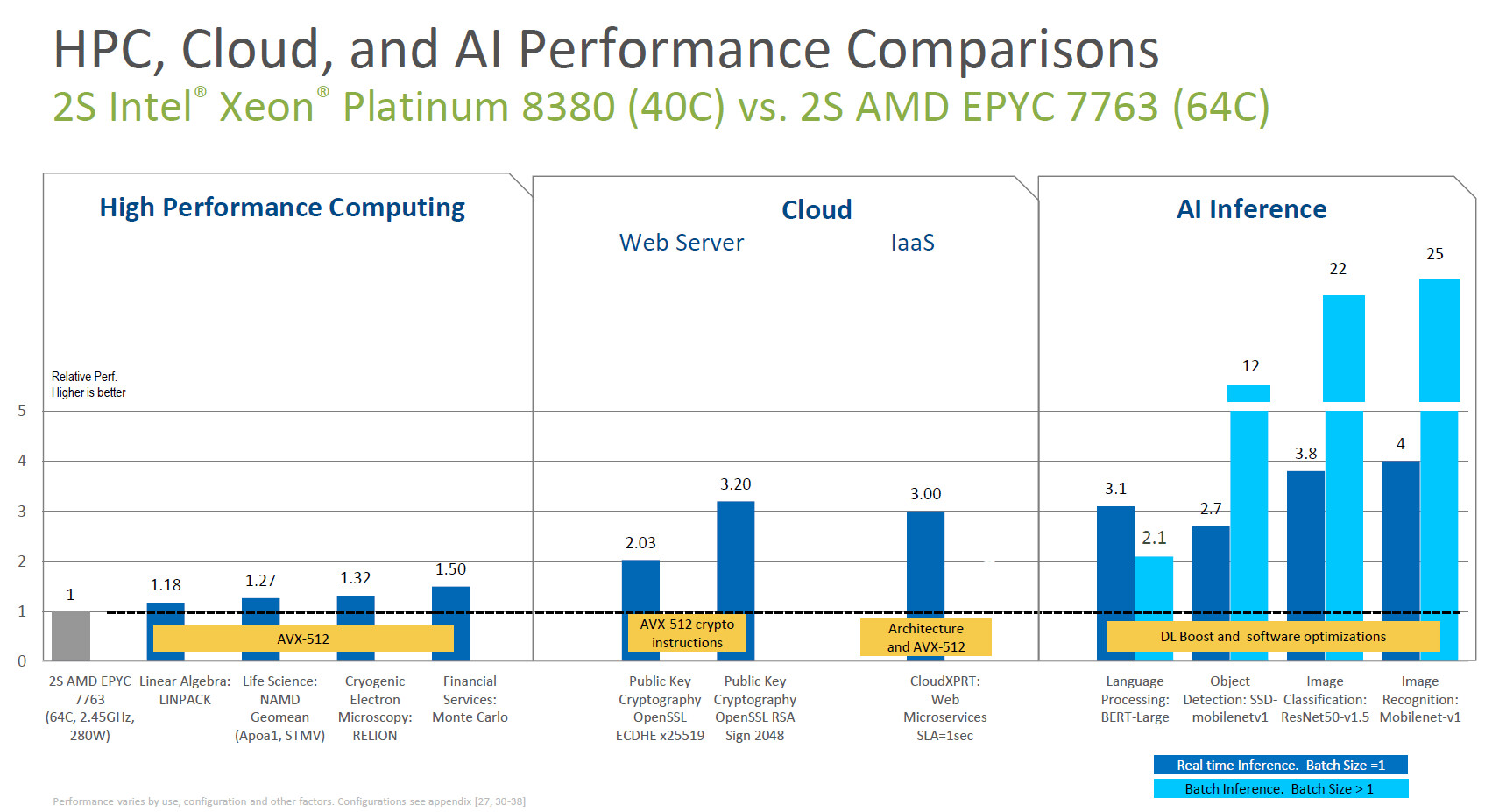
- Built-in AI acceleration: The latest 3rd Gen Intel Xeon Scalable processors deliver the AI performance, productivity and simplicity that enable customers to unlock more valuable insights from their data. As the only data center CPU with built-in AI acceleration, extensive software optimizations and turnkey solutions, the new processors make it possible to infuse AI into every application from edge to network to cloud. The latest hardware and software optimizations deliver 74% faster AI performance compared with the prior generation and provide up to 1.5 times higher performance across a broad mix of 20 popular AI workloads versus AMD EPYC 7763 and up to 1.3 times higher performance on a broad mix of 20 popular AI workloads versus NVIDIA. A100 GPU.
- Built-in security: With hundreds of research studies and production deployments, plus the ability to be continuously hardened over time, Intel SGX protects sensitive code and data with the smallest potential attack surface within the system. It is now available on 2-socket Xeon Scalable processors with enclaves that can isolate and process up to 1 terabyte of code and data to support the demands of mainstream workloads. Combined with new features, including Intel Total Memory Encryption and Intel Platform Firmware Resilience, the latest Xeon Scalable processors address today's most pressing data protection concerns.
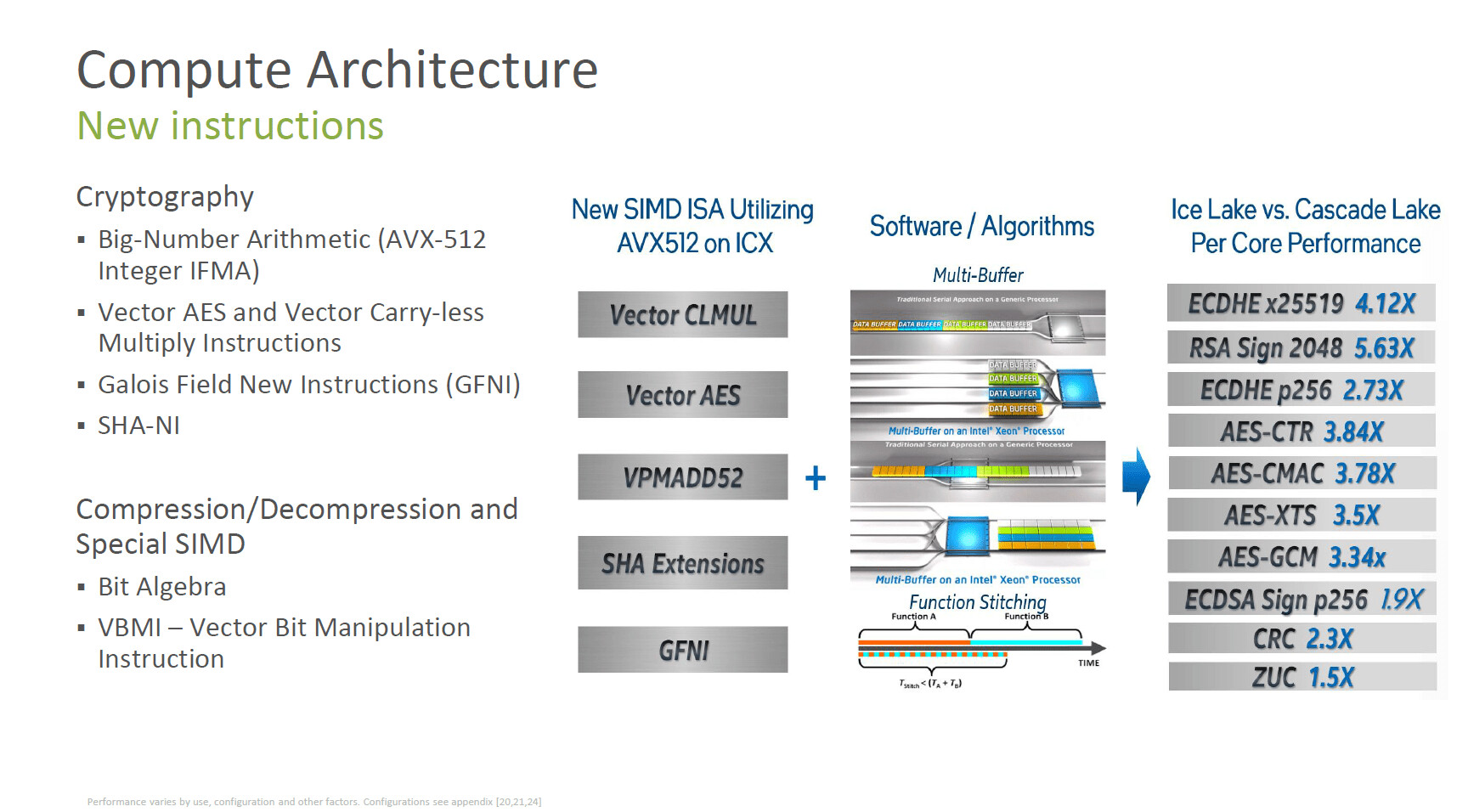
- Built-in crypto acceleration: Intel Crypto Acceleration delivers breakthrough performance across a host of important cryptographic algorithms. Businesses that run encryption-intensive workloads, such as online retailers who process millions of customer transactions per day, can leverage this capability to protect customer data without impacting user response times or overall system performance.
Intel Xeon Scalable processors are supported by more than 500 ready-to-deploy Intel IoT Market Ready Solutions and Intel Select Solutions that help to accelerate customer deployments—with up to 80% of our Intel Select Solutions being refreshed by end of year.
Industry-Leading Data Center Platform
Intel's data center platforms are the most pervasive on the market, with unmatched capabilities to move, store and process data. The latest 3rd Gen Intel Xeon Scalable platform includes the Intel Optane persistent memory 200 series, Intel Optane Solid State Drive (SSD) P5800X and Intel SSD D5-P5316 NAND SSDs, as well as Intel Ethernet 800 Series Network Adapters and the latest Intel Agilex FPGAs. Additional information about all these is available in the 3rd Gen Intel Xeon Scalable platform product fact sheet.
Delivering Flexible Performance Across Cloud, Networking and Intelligent Edge
Our latest 3rd Gen Xeon Scalable platform is optimized for a wide range of market segments—from the cloud to the intelligent edge.
- For the cloud: 3rd Gen Intel Xeon Scalable processors are engineered and optimized for the demanding requirements of cloud workloads and support a wide range of service environments. Over 800 of the world's cloud service providers run on Intel Xeon Scalable processors, and all of the largest cloud service providers are planning to offer cloud services in 2021 powered by 3rd Gen Intel Xeon Scalable processors.
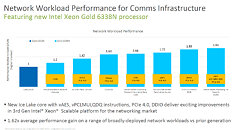
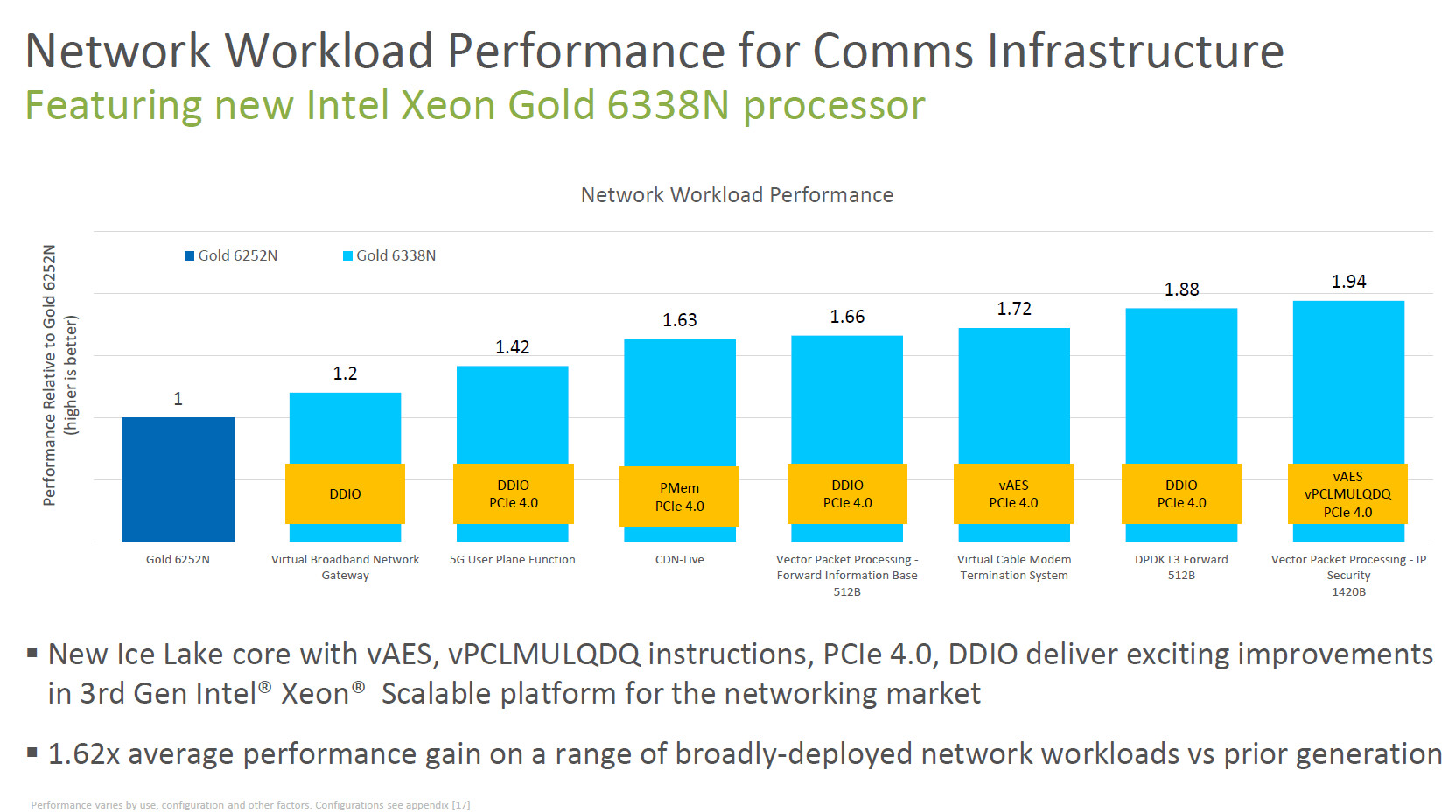
- For the network: Intel's network-optimized "N-SKUs" are designed to support diverse network environments and optimized for multiple workloads and performance levels. The latest 3rd Gen Intel Xeon Scalable processors deliver on average 62% more performance on a range of broadly-deployed network and 5G workloads over the prior generation. Working with a broad ecosystem of over 400 Intel Network Builders members, Intel delivers solution blueprints based on 3rd Gen Intel Xeon Scalable processor "N SKUs," resulting in accelerated qualification and shortened time-to-deployment for vRAN, NFVI, virtual CDN and more.
- For the intelligent edge: 3rd Gen Intel Xeon Scalable processors deliver the performance, security and operational controls required for powerful AI, complex image or video analytics, and consolidated workloads at the intelligent edge. The platform delivers up to 1.56 times more AI inference performance for image classification than the prior generations.







65 Comments on Intel Announces 10 nm Third Gen Xeon Scalable Processors "Ice Lake"
It seems like Intel's main problem with 10nm is the low clock rates, which leads to worse performance compared to their 14nm+++++++++++ process clocked at well over 5GHz (boost). Servers don't want to boost so high. Low and slow benefits servers, as these computers are designed for maximum compute in a given datacenter (Datacenters are limited by two things: either power, or cooling... and cooling is itself limited by power).
--------
The cache game is very interesting now. AMD offers more L3 cache than anyone else, but I've discussed the downsides of AMD's "split L3 cache" before. In short: AMD's L3 cache is only useful to a "CCX" (for Zen3: a cluster of 8 processors / 16 threads max), while L3 cache from traditional processors (Various ARM chips or Intel) are unified. Consider if 1MB from address 0x80008000 were being read-shared on a 64-core AMD chip with its 8x "split cache", there would be 8-copies of that one address (!!!), leading to 8MBs of read-data across AMD's 8x split cache (of size 256MBs): 3% of its cache. In contrast, Intel would only have 1MB in its unified 60MB L3 cache, or 1.6% of Intel's cache.
As such, large singular datasets (like Databases) will likely perform better on Intel's "smaller" 60MB L3 cache, despite AMD having 256MBs of L3 cache available. On the other hand, any workload with "split data", such as a 8-core / 16thread cloud-servers, will benefit grossly from AMD's architecture. So Azure / AWS / Google Compute are likely leaning towards AMD, while database engineers at Oracle / IBM are thinking Intel still. Or from a LAMP stack perspective: your PHP / Apache processes are most efficient on AMD, but your MySQL processes might be more efficient on Intel.
-------
In the past, I've talked about how AMD's L3 cache has latency penalties. Lets consider that 1MB region again. If one core were to change the data, it'd have to send a MESI message to Exclusive control of the data it wishes to change. The 63 other processors then need to communicate that their L1 and L2 caches remain unchanged (Total Store Ordering: all writes must be written in order on x86 architecture). Then the core changes the data, and broadcasts the new data to all 63 other processors.
However, as latency intensive as that operation is: there's a huge benefit to AMD's architecture I never thought of till now. AMD's "chiplet + I/O" architecture, starting with Zen2 (and later), means that this kind of MESI-like negotiation of data takes place over IF without affecting DDR4 bandwidth. (Zen1 on the other hand: because DDR4 was "behind" the IFOPs, the necessary MESI messages would reduce DDR4 bandwidth). So core#63, if it was NOT reading/writing to the changed region of memory, would have full memory bandwidth to DDR4 while the cores #0 through #62 were playing with MESI messages.
Of course, Intel's unified L3 and "flatter" NUMA profile (40-cores per NUMA zone instead of AMD's 8-cores per NUMA). But it should be noted that AMD's 4x NUMA (64-core single-socket EPYC) is "more efficient" than Intel's 4x NUMA (160-core quad-socket Xeon Gold) MESI + DDR4 bandwidth perspective. Each of Intel's chips has a memory controller attached (similar to Zen1), instead of a networked I/O chip that can more efficiently allocate bandwidth (like Zen2+). That is to say: Intel's UPI has to share both DDR4 bandwidth AND MESI messages. While AMD's on-package CCXes probably don't suffer much of a DDR4 bandwidth penalty.
'nuff said.
Not that this is a bad thing for AMD, mind you. But its the nature of today's market. TSMC only has so much capacity, and the iPhone, Snapdragon, and NVidia are both eating up TSMC's precious fab space. Intel owns their own fabs, and easily has the ability to deliver these chips.
Its the good old principle... the moment you can bring your design win to the mainstream is when you get that share and become the norm.
Both are sold out, yet the latter is a better outcome
Its good to understand the recent expansions are not at all focused on 'a response to pandemic' but long term, and even just strategical. TSMC's safety is a strong tie to the US, because China's really knocking on the door. Its an insurance policy, capacity is secondary and a bonus result. And yes, overall, demand is likely not going to come down, but they're also just compensating for all the other players that aren't playing anymore, like GF.
Pandemic being under control = lower demand? So far, all of the big ones that drive new demand are still in play, most notably automotive industry. This is going to be just like DRAM... constant race against the demand monster. I reckon we'll see older nodes get re-used more as they get smaller and/or smaller nodes to be used for very specific products. Apple was chasing those node shrinks, but they're going to find new competition there. Who cares about phones anyway.
X12SPA-TF
I don't see any of the W-series Xeons yet, but I assume this motherboard is for that lineup.
AMD has both reached its market share goals AND is doing so with far higher margins than it probably ever imagined (forcing Intel to cut its margins down to compete).
AMD's current plan was to diversify / reduce risk, by buying out Xilinx. I can't say that was necessarily a bad move, even though in the short / mid-term, its looking like doubling down on more CPUs would have been the better move. In 5 or 10 years, AMD probably will rely upon Xilinx's steady profits to keep the company stable.
That doesn't... seem small to me at all?
They just started production of D2 stepping lol. These things are TRICKLING out. Intel will be selling 14nm xeons as their main product for the forseeable future (all year). Plus, icelake is garbage, of course.
Imagine just hitting actual mass production of your 1 yr late money maker and zen 4 arrives :roll:
I can't wait for TSMC supply issues to wane. Bye, bye, intel.