Huawei Aims to Develop Homegrown HBM Memory Amidst US Sanctions
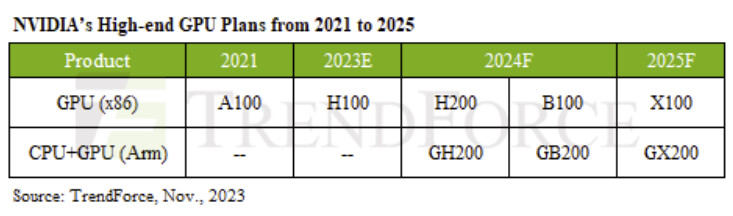
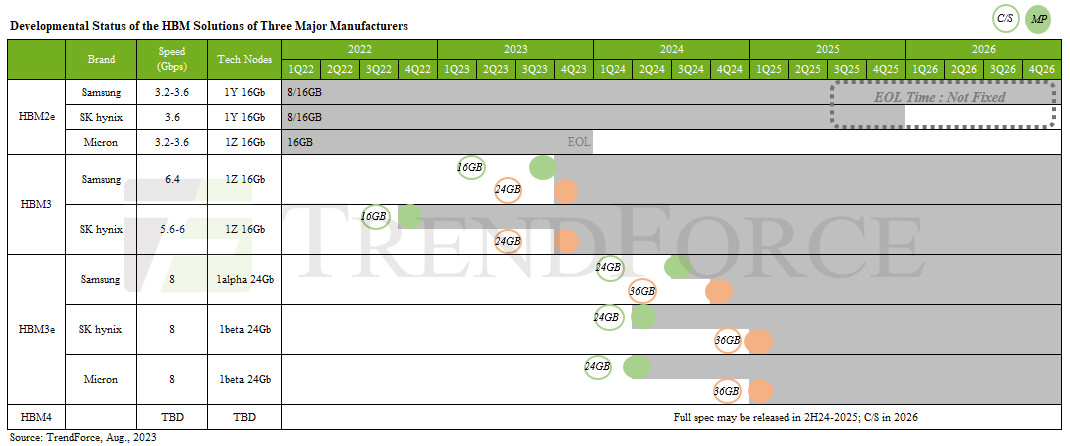
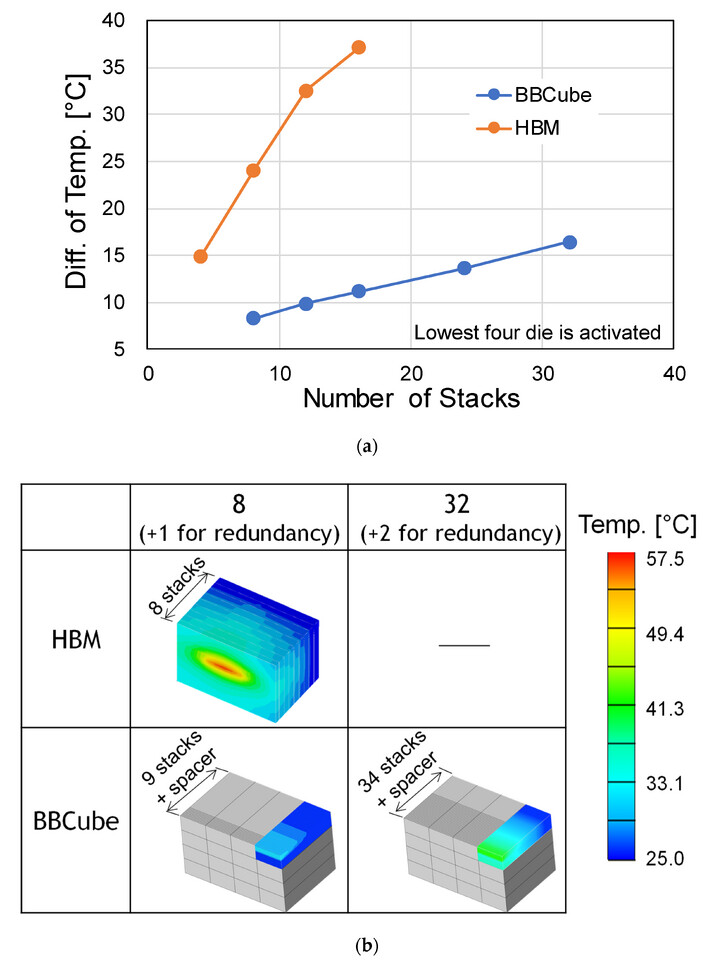
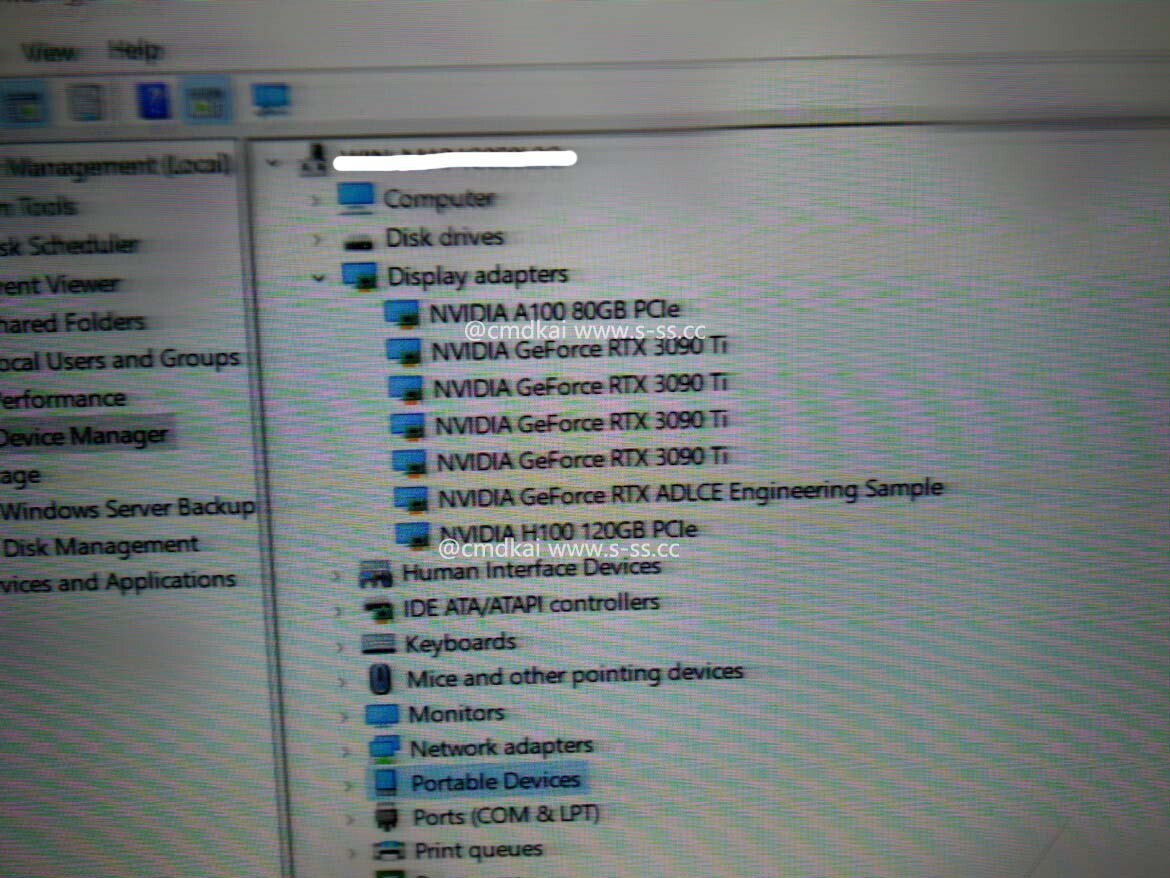
According to The Information, in a strategic maneuver to circumvent the constraints imposed by US sanctions, Huawei is accelerating efforts to establish domestic production capabilities for High Bandwidth Memory (HBM) within China. This move addresses the limitations that have hampered the company's advancements in AI and high-performance computing (HPC) sectors. HBM technology plays a pivotal role in enhancing the performance of AI and HPC processors by mitigating memory bandwidth bottlenecks. Recognizing its significance, Huawei has assembled a consortium comprising memory manufacturers backed by the Chinese government and prominent semiconductor companies like Fujian Jinhua Integrated Circuit. This consortium is focused on advancing HBM2 memory technology, which is crucial for Huawei's Ascend-series processors for AI applications.
Huawei's initiative comes at a time when the company faces challenges in accessing HBM from external sources, impacting the availability of its AI processors in the market. Despite facing obstacles such as international regulations restricting the sale of advanced chipmaking equipment to China, Huawei's efforts underscore China's broader push for self-sufficiency in critical technologies essential for AI and supercomputing. By investing in domestic HBM production, Huawei aims to secure a stable supply chain for these vital components, reducing reliance on external suppliers. This strategic shift not only demonstrates Huawei's resilience in navigating geopolitical challenges but also highlights China's determination to strengthen its technological independence in the face of external pressures. As the global tech landscape continues to evolve, Huawei's move to develop homegrown HBM memory could have far-reaching implications for China's AI and HPC capabilities, positioning the country as a significant player in the memory field.
Huawei's initiative comes at a time when the company faces challenges in accessing HBM from external sources, impacting the availability of its AI processors in the market. Despite facing obstacles such as international regulations restricting the sale of advanced chipmaking equipment to China, Huawei's efforts underscore China's broader push for self-sufficiency in critical technologies essential for AI and supercomputing. By investing in domestic HBM production, Huawei aims to secure a stable supply chain for these vital components, reducing reliance on external suppliers. This strategic shift not only demonstrates Huawei's resilience in navigating geopolitical challenges but also highlights China's determination to strengthen its technological independence in the face of external pressures. As the global tech landscape continues to evolve, Huawei's move to develop homegrown HBM memory could have far-reaching implications for China's AI and HPC capabilities, positioning the country as a significant player in the memory field.