Rambus Introduces High Bandwidth Memory PHY on GlobalFoundries FX-14
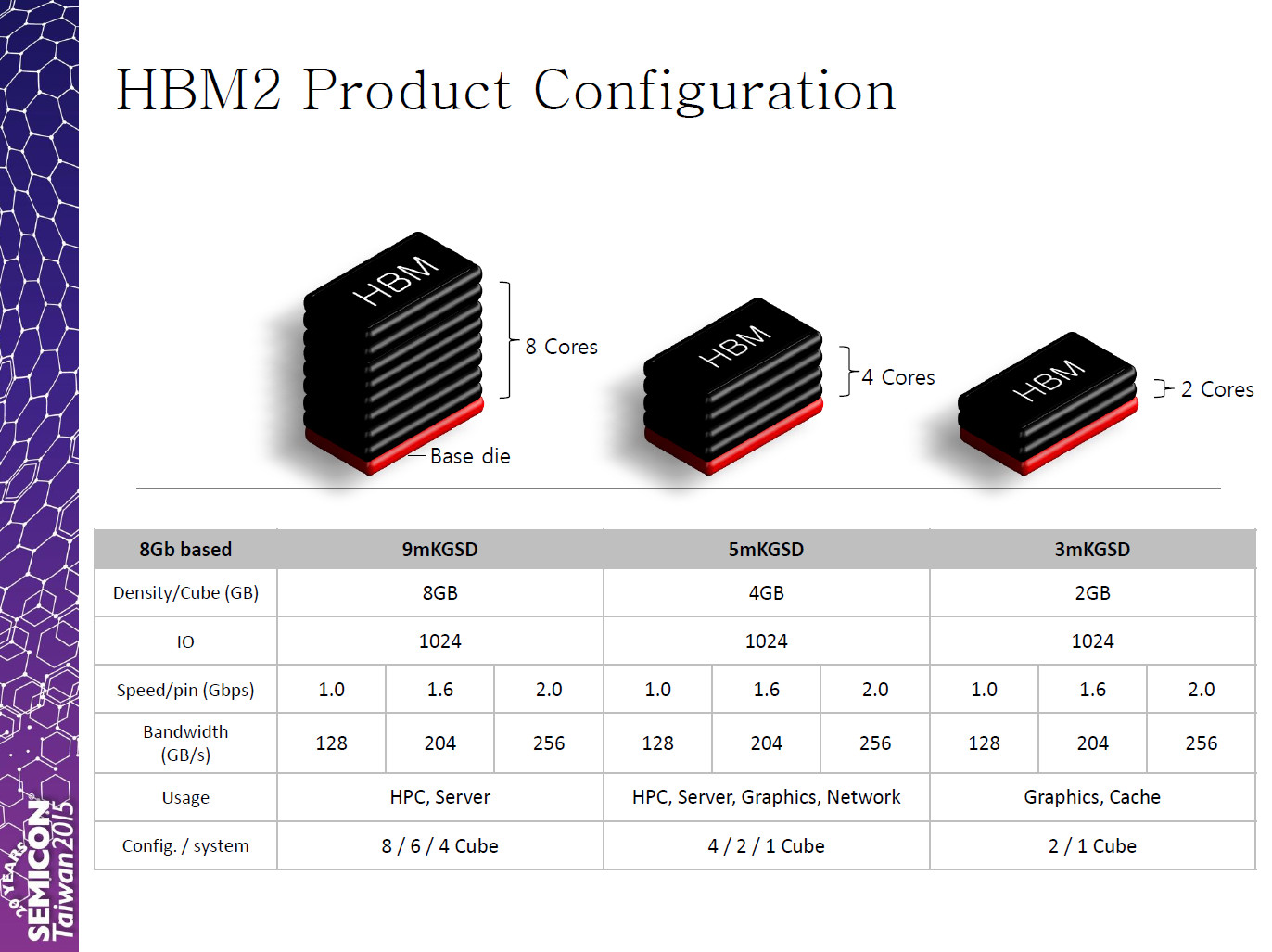
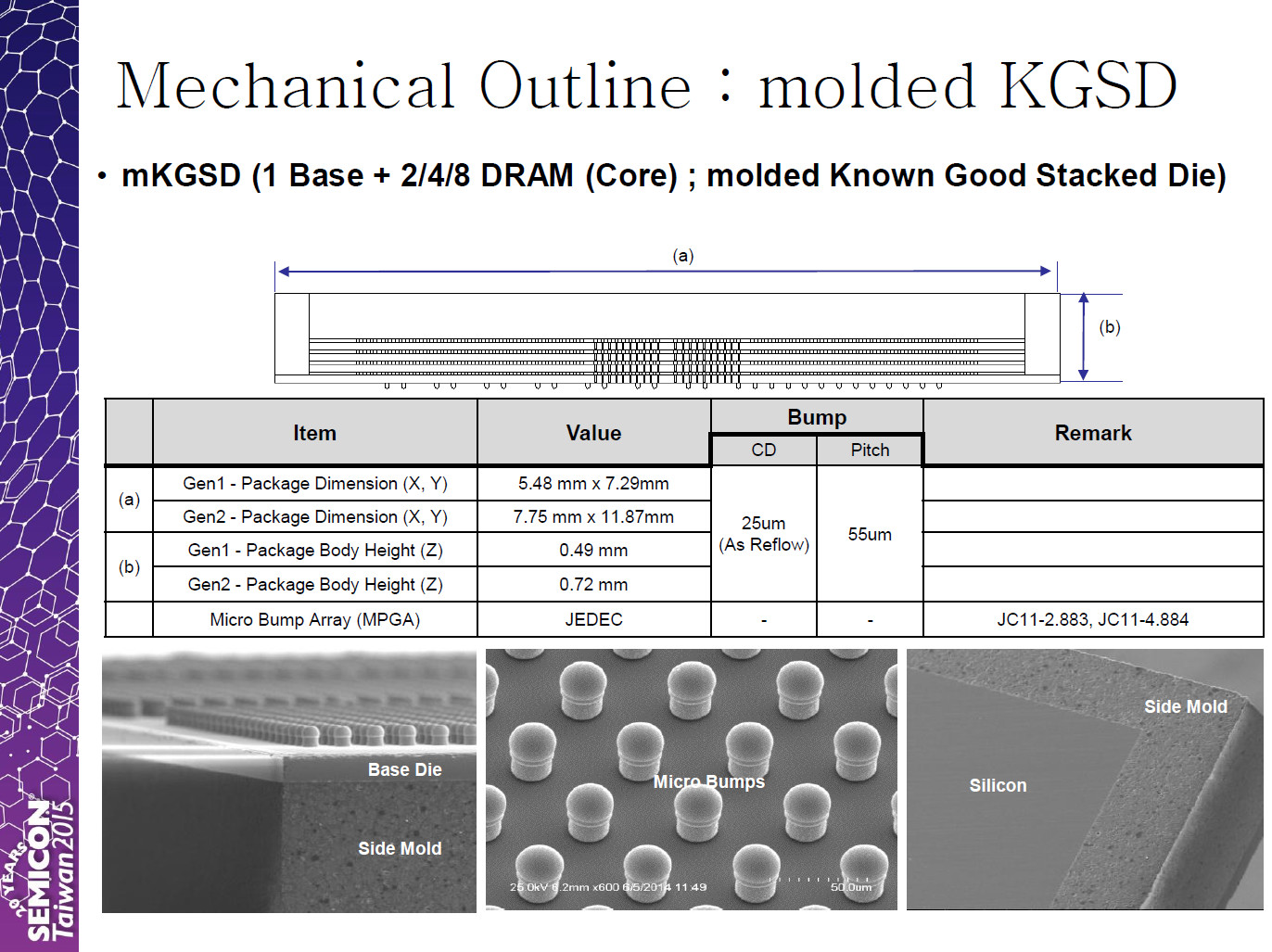
Rambus Inc. today announced the availability of its High Bandwidth Memory (HBM) Gen2 PHY developed for GLOBALFOUNDRIES high-performance FX-14 ASIC Platform. Built on the GLOBALFOUNDRIES 14nm FinFET (14LPP) process technology, the Rambus HBM PHY is aimed at networking and data center applications and designed for systems that require low latency and high bandwidth memory. This PHY is fully compliant with the JEDEC HBM2 standard and supports data rates up to 2000 Mbps per data pin, enabling a total bandwidth of 256 GB/s to meet the needs of today's most data-intensive tasks.
"Data center needs are continuously changing and we are at the forefront of delivering memory interface technology designed to meet today's most demanding workloads," said Luc Seraphin, senior vice president and general manager of the Rambus Memory and Interfaces division. "Through our collaboration with GLOBALFOUNDRIES, we are delivering a comprehensive and robust solution for high-performance data center and networking applications. Our HBM offering will allow data center solution developers to bring high performance memory closer to the CPU, thus reducing latency and improving the system throughput."
"Data center needs are continuously changing and we are at the forefront of delivering memory interface technology designed to meet today's most demanding workloads," said Luc Seraphin, senior vice president and general manager of the Rambus Memory and Interfaces division. "Through our collaboration with GLOBALFOUNDRIES, we are delivering a comprehensive and robust solution for high-performance data center and networking applications. Our HBM offering will allow data center solution developers to bring high performance memory closer to the CPU, thus reducing latency and improving the system throughput."