Friday, November 6th 2015

AMD Dragged to Court over Core Count on "Bulldozer"
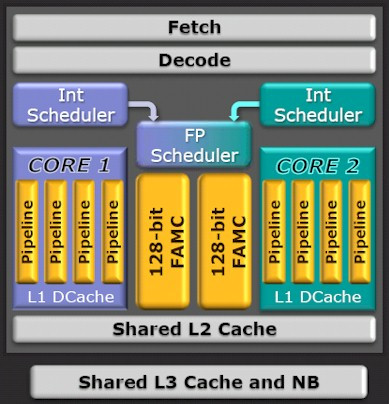
This had to happen eventually. AMD has been dragged to court over misrepresentation of its CPU core count in its "Bulldozer" architecture. Tony Dickey, representing himself in the U.S. District Court for the Northern District of California, accused AMD of falsely advertising the core count in its latest CPUs, and contended that because of they way they're physically structured, AMD's 8-core "Bulldozer" chips really only have four cores.
The lawsuit alleges that Bulldozer processors were designed by stripping away components from two cores and combining what was left to make a single "module." In doing so, however, the cores no longer work independently. Due to this, AMD Bulldozer cannot perform eight instructions simultaneously and independently as claimed, or the way a true 8-core CPU would. Dickey is suing for damages, including statutory and punitive damages, litigation expenses, pre- and post-judgment interest, as well as other injunctive and declaratory relief as is deemed reasonable.
Source:
LegalNewsOnline
The lawsuit alleges that Bulldozer processors were designed by stripping away components from two cores and combining what was left to make a single "module." In doing so, however, the cores no longer work independently. Due to this, AMD Bulldozer cannot perform eight instructions simultaneously and independently as claimed, or the way a true 8-core CPU would. Dickey is suing for damages, including statutory and punitive damages, litigation expenses, pre- and post-judgment interest, as well as other injunctive and declaratory relief as is deemed reasonable.
511 Comments on AMD Dragged to Court over Core Count on "Bulldozer"
10 million attempts
uncheck special characters
check require special charaters (creates an unsolvable situation)
minimum characters 32 Edit: Added this one because it can massively impact time if it randomly does a lot of short ones
5.9142104
Disabled even number cores in Task Manager (it still spawns 8 threads)
13.2191610
123% faster
I'm gonna add a thread limiter to make it easier to test...
When this trial ends I wager that there will be a legal definition of a core if nothing else. It will be interesting to watch AMD backpedal at that time.
This is debugging data...I'll upload updated program shortly...
1: 24.6987115
2: 13.1477996
3: 9.1914374
4: 7.4688438
5: 6.8086950
6: 6.2363480
7: 5.8927118
8: 5.7746498
...the application is working correctly. Big jumps between 1-4 where there's an actual core to do the work. Small jumps between 5-8 where HTT is kicking in. Beyond that, performance is expected to fall because the threads are fighting each other for time.
...once W1z lets me edit it that is...
1.1.4, 6700K, final...
8: 5.6961283
7: 5.7390397
6: 6.2014922
5: 6.7108575
4: 7.1342991
3: 8.8729954
2: 12.6389990
1: 24.1833987
I'll attach 1.1.4 here until I can edit the other thread. Edit: Download here: www.techpowerup.com/forums/threads/random-password-generator.164777/page-2
Edit: I'm ready for FX-8350 data.
It does have up to 20% overhead per core.
As a developer, if I have a thread that is not limited in most situation and will almost always give me a speed up of over 50% versus another thread, I consider it a core. It's tangible bandwidth that can be had and to me, that's all that matters. HTT only helps in select cases but more often than not, I can't get speed up beyond one or two threads over 4 on a quad-core Intel setup using hyperthreading where I can when bulldozer integer cores.
I'll agree with you that the integer core isn't what we've traditionally recognized as a core but, it has far too many dedicated resources to call it SMT. So while it might not be a traditional core, it's a lot more like a traditional core than like SMT.
SMT is a concept, not a hardware design. SMT is what Bulldozer does (two threads in one core).
Again, distinguishing feature of a core is nothing is shared. L2 can't be considered part of Core 2 Duo's core because it is shared with the neighboring core.Which AMD did too, but stupidly required a separate thread to access them.Well, you made me test it (everything else the same):
8: 5.6961283 sec -> 5.2848560 sec
1: 24.1833987 -> 24.1773771 sec
It stands to reason that 7 threads wouldn't see that difference because only where the main thread lies does it compete with the worker thread. 8 is still faster than 7 so...it's just a boost cutting out the UI updates.SMT isn't defined by one implementation. It does describe HTT and Bulldozer well. Bulldozer takes away from single-threaded performance to boost multi-threaded performance where Intel does the opposite. At the end of the day, they are different means to the same end (more throughput without adding additional cores).
And again it can process two threads per core or 4 per module.
It has quite the mix of hardware accelerating pretty much every conceivable task.I've yet to see any evidence that proves the module isn't a core and much to the contrary.
Nobody expects for small car to do same as a big car, but when it comes to cores people are suddenly acting like they are dealing with SI units, people valuing cpus by the core count might as well pay for cpus by the kilogram ... btw, I'm gladly trading one kilogram of celerons for same mass of i7s.
Maybe good automotive analogy would be 8 cylinder engine using one spark plug for pair of cylinders twice as often :laugh:
Anyway, operating systems are always dealing with pairs of logical processors to accommodate all possible (existing and non yet existing) physical organizations of execution units in modern super scalar cpu where both thread data dependency and pure thread parallelism are exploited for optimal gains in all scenarios. This setup is too generic and way too flexible to use logical processor from the OS as an argument in this case. AMD half a module core is a core albeit less potent and less scalable, it's not hyper threading - it's more scalable. Only in terms of scaling you could argue AMD core is less of a core than what is the norm (hence my market share tangent - intel is the norm). So the underdog in the duopoly is not putting enough asterisks and fine print on the marketing material = slap on the wrist (symbolic restitution and obligatory asterisk with fine print for the future*)
* may scale differently with different types of workload
b) I haven't used Google in a long time.I don't know whether that claims is true or not but I do know that if there is more than two threads in the core (as in "module"), those threads will have to be in a wait state. Bulldozer can't execute more than two at a time.
Sadly, there are not many compiler flags usable for bulldozer in windows even when built directly to machine code with ms compiler. All we have is generic optimizations, more generic /favor:AMD64 and some more generic /arch:[IA32|SSE|SSE2|AVX|AVX2]
Linux folks like bulldozer bit more because they have GCC with "magical" -march=bdver1 compiler option, and AMD's own continuation of Open64 compiler ... also all libraries are easily rebuilt in the appropriate "flavor"
Also WinForms is not WPF.
Coincidentally, as I felt like I have seen this before I managed to find an almost year old similar case www.leagle.com/decision/In FDCO 20160408M22/DICKEY v. ADVANCED MICRO DEVICES, INC.
and it was dismissed: