Monday, March 6th 2017

AMD's Ryzen Cache Analyzed - Improvements; Improveable; CCX Compromises
AMD's Ryzen 7 lower than expected performance in some applications seems to stem from a particular problem: memory. Before AMD's Ryzen chips were even out, reports pegged AMD as having confirmed that most of the tweaks and programming for the new architecture had been done in order to improve core performance to its max - at the expense of memory compatibility and performance. Apparently, and until AMD's entire Ryzen line-up is completed with the upcoming Ryzen 5 and Ryzen 3 processors, the company will be hard at work on improving Ryzen's cache handling and memory latency.
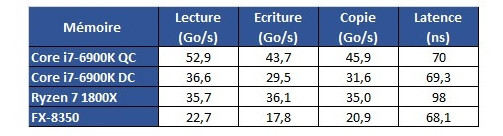
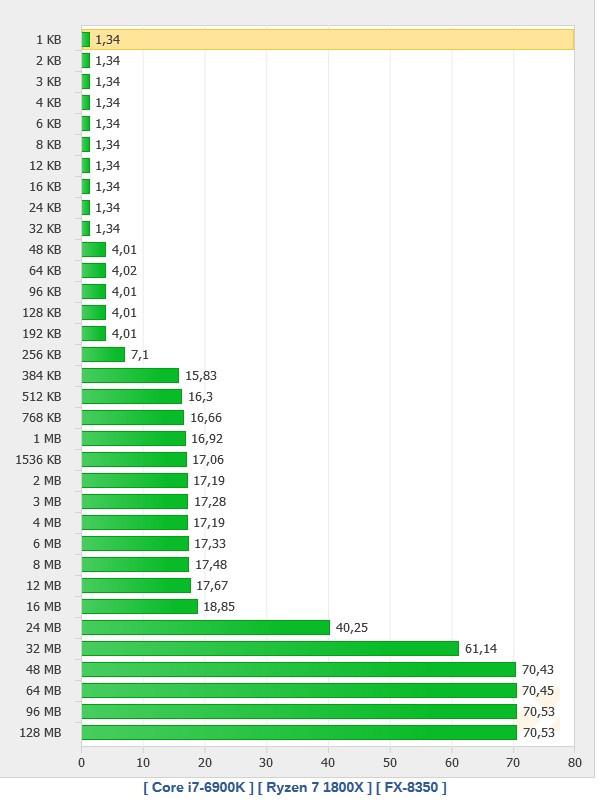
Hardware.fr has done a pretty good job in exploring Ryzen's cache and memory subsystem deficiencies through the use of AIDA 64, in what would otherwise be an exceptional processor design. Namely, the fact that there seems to be some problem with Ryzen's L3 cache and memory subsystem implementation. Paired with the same memory configuration and at the same 3 GHz clocks, for instance, Ryzen's memory tests show memory latency results that are up to 30 ns higher (at 90 ns) than the average latency found on Intel's i7 6900K or even AMD's FX 8350 (both at around 60 ns).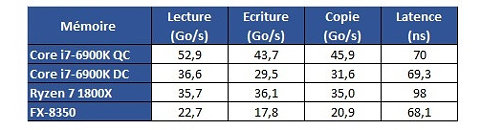 Update: The lack of information regarding the test system could have elicited some gray areas in the interpretation of the results. Hardware.fr tests, and below results, were obtained by setting the 8-core chips at 3 GHz, with SMT and HT deactivated. Memory for the Ryzen and Intel platforms was DDR4-2400 with 15-15-15-35 timings, and memory for the AMD FX platform was DDR3-1600 operating at 9-9-9-24 timings. Both memory configurations were set at 4x 4 GB, totaling 16 GB of memory.
Update: The lack of information regarding the test system could have elicited some gray areas in the interpretation of the results. Hardware.fr tests, and below results, were obtained by setting the 8-core chips at 3 GHz, with SMT and HT deactivated. Memory for the Ryzen and Intel platforms was DDR4-2400 with 15-15-15-35 timings, and memory for the AMD FX platform was DDR3-1600 operating at 9-9-9-24 timings. Both memory configurations were set at 4x 4 GB, totaling 16 GB of memory.
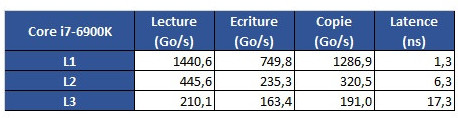
From some more testing results, we see that Intel's L1 cache is still leagues ahead from AMD's implementation; that AMD's L2 is overall faster than Intel's, though it does incur on a roughly 2 ns latency penalty; and that AMD's L3 memory is very much behind Intel's in all metrics but L3 cache copies, with latency being almost 3x greater than on Intel's 6900K.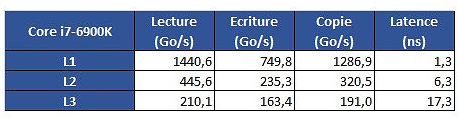
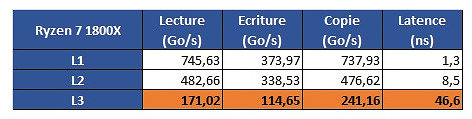
 The problem is revealed through an increasing work size. In the case of the 6900K, which has a 32 KB L1 cache, performance is greatest until that workload size. Higher-sized workloads that don't fit on the L1 cache then "spill" towards the 6900K's 256 KB L2 cache; workloads higher than 256 KB and lower than 16 MB are then submitted to the 6900 K's 20 MB L3 cache, with any workloads larger than 16 MB then forcing the processor to access the main system memory, with increasing latency in access times until it reaches the RAM's ~70 ns access times.
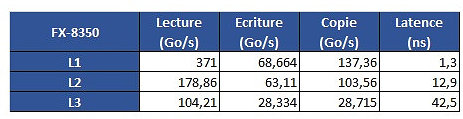
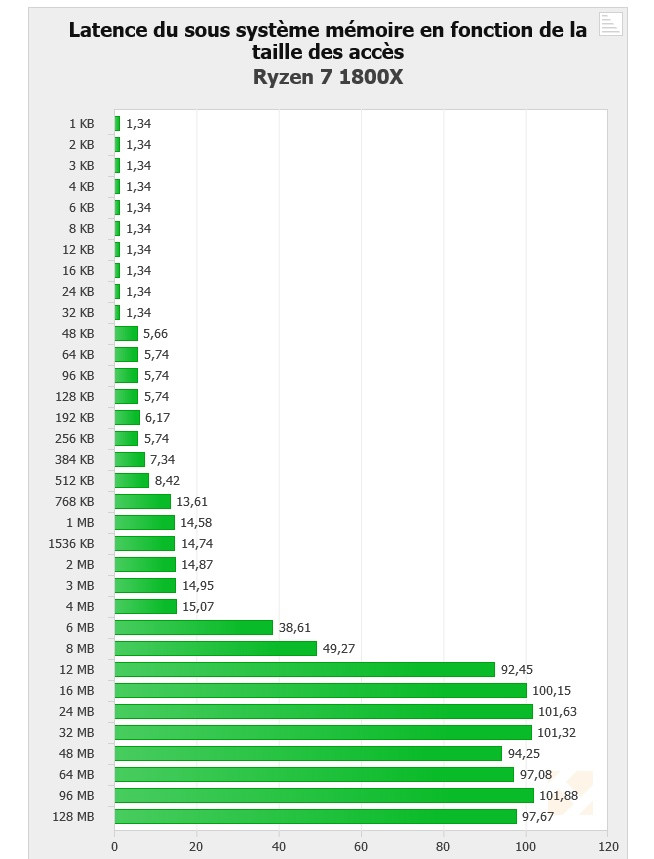
The problem is revealed through an increasing work size. In the case of the 6900K, which has a 32 KB L1 cache, performance is greatest until that workload size. Higher-sized workloads that don't fit on the L1 cache then "spill" towards the 6900K's 256 KB L2 cache; workloads higher than 256 KB and lower than 16 MB are then submitted to the 6900 K's 20 MB L3 cache, with any workloads larger than 16 MB then forcing the processor to access the main system memory, with increasing latency in access times until it reaches the RAM's ~70 ns access times. However, on AMD's Ryzen 1800X, latency times are a wholly different beast. Everything is fine in the L1 and L2 caches (32 KB and 512 KB, respectively). However, when moving towards the 1800X's 16 MB L3 cache, the behavior is completely different. Up to 4 MB cache utilization, we see an expected increase in latency; however, latency goes through the roof way before the chip's 16 MB of L3 cache is completely filled. This clearly derives from AMD's Ryzen modularity, with each CCX complex (made up of 4 cores and 8 MB L3 cache, besides all the other duplicated logic) being able to access only 8 MB of L3 cache at any point in time.
However, on AMD's Ryzen 1800X, latency times are a wholly different beast. Everything is fine in the L1 and L2 caches (32 KB and 512 KB, respectively). However, when moving towards the 1800X's 16 MB L3 cache, the behavior is completely different. Up to 4 MB cache utilization, we see an expected increase in latency; however, latency goes through the roof way before the chip's 16 MB of L3 cache is completely filled. This clearly derives from AMD's Ryzen modularity, with each CCX complex (made up of 4 cores and 8 MB L3 cache, besides all the other duplicated logic) being able to access only 8 MB of L3 cache at any point in time. The difference in access speeds between 4 MB and 8 MB workloads can be explained through AMD's own admission that Ryzen's core design incurs in different access times depending on which parts of the L3 cache are accessed by the CCX. The fact that this memory is "mostly exclusive" - which means that other information may be stored on it that's not of immediate use to the task at hand - can be responsible for some memory accesses on its own. Since the L3 cache is essentially a victim cache, meaning that it is filled with the information that isn't able to fit onto the chips' L1 or L2 cache levels, this would mean that each CCX can only access up to 8 MB of L3 cache if any given workload uses no more than 4 cores from a given CCX. However, even if we were to distribute workload in-between two different cores from each CCX, so as to be able to access the entirety of the 1800X's 16 MB cache... we'd still be somewhat constrained by the inter-CCX bandwidth achieved by AMD's Data Fabric interconnect... 22 GB/s, which is much lower than the L3 cache's 175 GB/s - and even lower than RAM bandwidth. That the Data Fabric interconnect also has to carry data from AMD's IO Hub PCIe lanes also potentially interferes with the (already meagre) available bandwidth
The difference in access speeds between 4 MB and 8 MB workloads can be explained through AMD's own admission that Ryzen's core design incurs in different access times depending on which parts of the L3 cache are accessed by the CCX. The fact that this memory is "mostly exclusive" - which means that other information may be stored on it that's not of immediate use to the task at hand - can be responsible for some memory accesses on its own. Since the L3 cache is essentially a victim cache, meaning that it is filled with the information that isn't able to fit onto the chips' L1 or L2 cache levels, this would mean that each CCX can only access up to 8 MB of L3 cache if any given workload uses no more than 4 cores from a given CCX. However, even if we were to distribute workload in-between two different cores from each CCX, so as to be able to access the entirety of the 1800X's 16 MB cache... we'd still be somewhat constrained by the inter-CCX bandwidth achieved by AMD's Data Fabric interconnect... 22 GB/s, which is much lower than the L3 cache's 175 GB/s - and even lower than RAM bandwidth. That the Data Fabric interconnect also has to carry data from AMD's IO Hub PCIe lanes also potentially interferes with the (already meagre) available bandwidth
AMD's Zen architecture is surely an interesting beast, and these kinds of results really go to show the amount of work, of give-and-take design that AMD had to go through in order to achieve a cost-effective, scalable, and at the same time performant architecture through its CCX modules. However, this kind of behavior may even go so far as to give us some answers with regards to Ryzen's lower than expected gaming performance, since games are well-known to be sensitive to a processor's cache performance profile.
Source:
Hardware.fr
Hardware.fr has done a pretty good job in exploring Ryzen's cache and memory subsystem deficiencies through the use of AIDA 64, in what would otherwise be an exceptional processor design. Namely, the fact that there seems to be some problem with Ryzen's L3 cache and memory subsystem implementation. Paired with the same memory configuration and at the same 3 GHz clocks, for instance, Ryzen's memory tests show memory latency results that are up to 30 ns higher (at 90 ns) than the average latency found on Intel's i7 6900K or even AMD's FX 8350 (both at around 60 ns).
From some more testing results, we see that Intel's L1 cache is still leagues ahead from AMD's implementation; that AMD's L2 is overall faster than Intel's, though it does incur on a roughly 2 ns latency penalty; and that AMD's L3 memory is very much behind Intel's in all metrics but L3 cache copies, with latency being almost 3x greater than on Intel's 6900K.
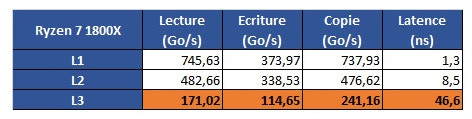
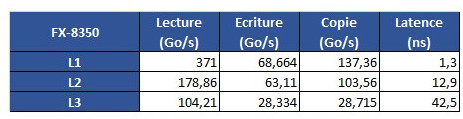
AMD's Zen architecture is surely an interesting beast, and these kinds of results really go to show the amount of work, of give-and-take design that AMD had to go through in order to achieve a cost-effective, scalable, and at the same time performant architecture through its CCX modules. However, this kind of behavior may even go so far as to give us some answers with regards to Ryzen's lower than expected gaming performance, since games are well-known to be sensitive to a processor's cache performance profile.
120 Comments on AMD's Ryzen Cache Analyzed - Improvements; Improveable; CCX Compromises
Again :
- You can't compare L3 values (especially L3 latency), they are wrong (in orange, for a reason)
- FYI, the table that they took from our article of RAM latency is done at 3 GHz with SMT and HT off. Real RAM latency @ stock is around 89.6 with DDR4-2400. That's still much higher than other CPUs with same RAM, but you can't compare a 3 GHz value to other CPUs @ stock.
Hopefully this news will get fixed, please check the original article with Google Translate if you want more details.
Whether we are splitting hairs at the 98ns in this article, the 92ns, this recent 89.6ns you reference, what we have is some pretty bad latency comparing to AMD's other offerings or Intel products. As a result of these findings, coupled with gaming performance, we have a stock that continues it's slide.
Most modern games only really use 6 threads (While jumping to 8 when necessary) depending on the workload, and thus AMD loses in most games.
Makes me once again say that AMD should try to make a 4.5 - 5.0 GHz 4c/8t Ryzen 7 chip for $275. They need a version made specifically for high-FPS gamers.
We alerted tpu this morning of the discrepancies, I have 0 doubt they will fix the summary ;)
In fact I am pretty sure they plan to build up their Navi GPU's in the same way (Interconnected clusters) so that they can make some monster 400w single-gpu chips.
I have visited your site and understand it would be more appropriate for TPU to outline the precise configuration to better represent the data. I believe the conclusion remains the same - latency is higher than we would like.
Just to make sure no one confuses anything (check my previous posts if necessary), I think this product is impressive and a remarkable value. It fell a little below AMD's hype and our expectations but is a remarkable achievement for a company previously on the verge. Even as is, it has provided some competition for Intel and with some tuning may do some decent disruption.
Considering all the contains that AMD has decked against them (budget, marketshare, less workforce, etc., etc.) it's amazing what they managed to do. I for sure will replace all my crunchers with 1700s, that's a given. :D
I'll keep my 4590 and 3770K for gaming tough. Maybe I'll replace them with 4 core R5s down the line but they still do their work just fine.
The only thing I am unsure about reading other reports is how well thread handling will improve the efficiency of the chip, it appears that the windows task scheduler is doing a poor job as its unaware of the nuances of the hardware, and may send threads to other CCX's and the huge increase in cache latency is what hurts the most, so keeping threads in the same CCX and or treating some threads as affinity bound should help the performance, the implied AI in this situation ( I haven't seen any definitive tests to show that program performance increases over runs) may be able to work as intended, or perhaps we are already seeing its effects in the already good but not great performance.
I've seen some benchmarks of the 1800x performing WORSE than a 7700K while streaming a game while doing other tasks.
They tried, i had hopes but i'm gonna give this one a pass.
Which is something that Games and OS do quite often to balance load among cores.
By doing that will have to move the data from CCX0 L3 Cache to CCX1 L3 Cache which will cause the bottleneck because of the ultra slow L3 interconnect.
The solution should be in sight, they just to make the Windows scheduler aware of the design and move thread only in the CCX that thread originates.
That way it eliminates moving data between L3 caches for both modules.
This hopefully can be confirmed benching a game that doesn't use more than 4 threads and disable SMT and one of the CCX on the Ryzen 7.
That eliminates all the above scenarios.
It would make the solution software only, exciting.
I'll take the time to read and pour through your comments and some of the questions pose to see if I can shed some light on some other things.I can compare them between your own results, which where all done with the same configuration between the 6900K and the 1800X, right? That's what I compare in the article.Latency in milliseconds or microseconds doesn't really change anything: the discrepancy remains the same, and the units of measurement remained constant. It's a "brain-farted" technicality, which doesn't affect the overall picture. Unfortunate, yes, but doesn't change anything in the grand scheme of things.
Regarding the absent configuration, a stark neglect on my part, which I will update accordingly, so thanks for bringing that to my attention =) Time isn't as we would like, hence why only now I'm here and improving the article.^
This. I will, however, edit the piece including the noted configuration.I will ignore the delivery of your criticism and focus on the content. Thank you for it.For me, that was the whole point of the post. AIDA 64 is a benchmarking utility, but until it has been "fixed", as in, properly optimized for Ryzen, I think it presents itself as a great opportunity to see Ryzen's behavior on non-optimized workloads (ie, what all games currently are).
Anyway that is the most interesting part from this launch, the 16 core, while it is nice and powerful is too much for current software.
For eg, because Ryzen won't oc much. Clock them both @ 3.9ghz, 4c/8t. I know we are gimping the i7 7700k but i'm just curious to know the result of "almost the same" setup would be. Gaming & productivity benches needed.