Monday, March 6th 2017

AMD's Ryzen Cache Analyzed - Improvements; Improveable; CCX Compromises
AMD's Ryzen 7 lower than expected performance in some applications seems to stem from a particular problem: memory. Before AMD's Ryzen chips were even out, reports pegged AMD as having confirmed that most of the tweaks and programming for the new architecture had been done in order to improve core performance to its max - at the expense of memory compatibility and performance. Apparently, and until AMD's entire Ryzen line-up is completed with the upcoming Ryzen 5 and Ryzen 3 processors, the company will be hard at work on improving Ryzen's cache handling and memory latency.
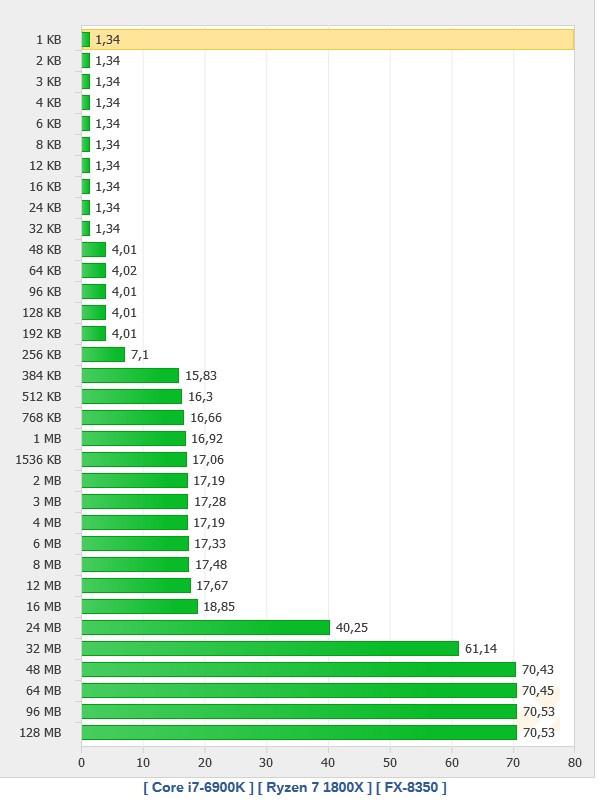
Hardware.fr has done a pretty good job in exploring Ryzen's cache and memory subsystem deficiencies through the use of AIDA 64, in what would otherwise be an exceptional processor design. Namely, the fact that there seems to be some problem with Ryzen's L3 cache and memory subsystem implementation. Paired with the same memory configuration and at the same 3 GHz clocks, for instance, Ryzen's memory tests show memory latency results that are up to 30 ns higher (at 90 ns) than the average latency found on Intel's i7 6900K or even AMD's FX 8350 (both at around 60 ns).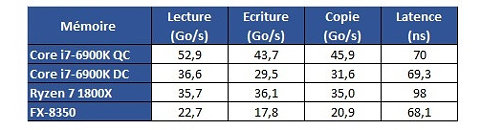 Update: The lack of information regarding the test system could have elicited some gray areas in the interpretation of the results. Hardware.fr tests, and below results, were obtained by setting the 8-core chips at 3 GHz, with SMT and HT deactivated. Memory for the Ryzen and Intel platforms was DDR4-2400 with 15-15-15-35 timings, and memory for the AMD FX platform was DDR3-1600 operating at 9-9-9-24 timings. Both memory configurations were set at 4x 4 GB, totaling 16 GB of memory.
Update: The lack of information regarding the test system could have elicited some gray areas in the interpretation of the results. Hardware.fr tests, and below results, were obtained by setting the 8-core chips at 3 GHz, with SMT and HT deactivated. Memory for the Ryzen and Intel platforms was DDR4-2400 with 15-15-15-35 timings, and memory for the AMD FX platform was DDR3-1600 operating at 9-9-9-24 timings. Both memory configurations were set at 4x 4 GB, totaling 16 GB of memory.
From some more testing results, we see that Intel's L1 cache is still leagues ahead from AMD's implementation; that AMD's L2 is overall faster than Intel's, though it does incur on a roughly 2 ns latency penalty; and that AMD's L3 memory is very much behind Intel's in all metrics but L3 cache copies, with latency being almost 3x greater than on Intel's 6900K.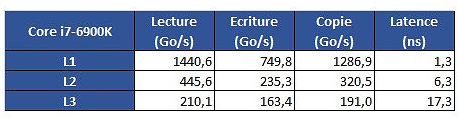
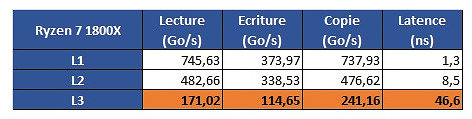
 The problem is revealed through an increasing work size. In the case of the 6900K, which has a 32 KB L1 cache, performance is greatest until that workload size. Higher-sized workloads that don't fit on the L1 cache then "spill" towards the 6900K's 256 KB L2 cache; workloads higher than 256 KB and lower than 16 MB are then submitted to the 6900 K's 20 MB L3 cache, with any workloads larger than 16 MB then forcing the processor to access the main system memory, with increasing latency in access times until it reaches the RAM's ~70 ns access times.
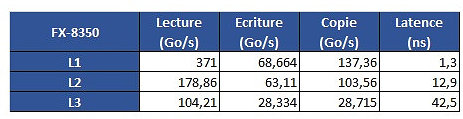
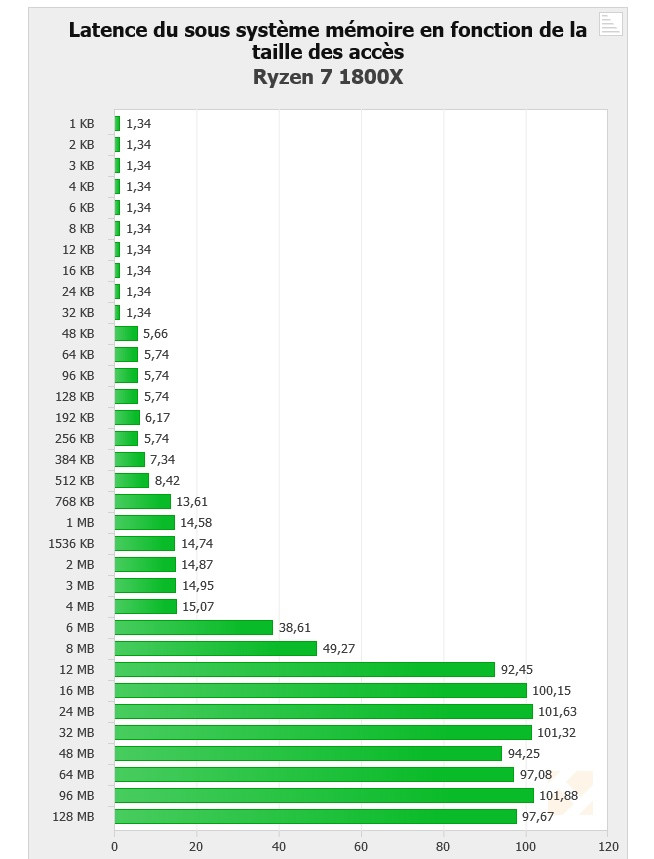
The problem is revealed through an increasing work size. In the case of the 6900K, which has a 32 KB L1 cache, performance is greatest until that workload size. Higher-sized workloads that don't fit on the L1 cache then "spill" towards the 6900K's 256 KB L2 cache; workloads higher than 256 KB and lower than 16 MB are then submitted to the 6900 K's 20 MB L3 cache, with any workloads larger than 16 MB then forcing the processor to access the main system memory, with increasing latency in access times until it reaches the RAM's ~70 ns access times. However, on AMD's Ryzen 1800X, latency times are a wholly different beast. Everything is fine in the L1 and L2 caches (32 KB and 512 KB, respectively). However, when moving towards the 1800X's 16 MB L3 cache, the behavior is completely different. Up to 4 MB cache utilization, we see an expected increase in latency; however, latency goes through the roof way before the chip's 16 MB of L3 cache is completely filled. This clearly derives from AMD's Ryzen modularity, with each CCX complex (made up of 4 cores and 8 MB L3 cache, besides all the other duplicated logic) being able to access only 8 MB of L3 cache at any point in time.
However, on AMD's Ryzen 1800X, latency times are a wholly different beast. Everything is fine in the L1 and L2 caches (32 KB and 512 KB, respectively). However, when moving towards the 1800X's 16 MB L3 cache, the behavior is completely different. Up to 4 MB cache utilization, we see an expected increase in latency; however, latency goes through the roof way before the chip's 16 MB of L3 cache is completely filled. This clearly derives from AMD's Ryzen modularity, with each CCX complex (made up of 4 cores and 8 MB L3 cache, besides all the other duplicated logic) being able to access only 8 MB of L3 cache at any point in time. The difference in access speeds between 4 MB and 8 MB workloads can be explained through AMD's own admission that Ryzen's core design incurs in different access times depending on which parts of the L3 cache are accessed by the CCX. The fact that this memory is "mostly exclusive" - which means that other information may be stored on it that's not of immediate use to the task at hand - can be responsible for some memory accesses on its own. Since the L3 cache is essentially a victim cache, meaning that it is filled with the information that isn't able to fit onto the chips' L1 or L2 cache levels, this would mean that each CCX can only access up to 8 MB of L3 cache if any given workload uses no more than 4 cores from a given CCX. However, even if we were to distribute workload in-between two different cores from each CCX, so as to be able to access the entirety of the 1800X's 16 MB cache... we'd still be somewhat constrained by the inter-CCX bandwidth achieved by AMD's Data Fabric interconnect... 22 GB/s, which is much lower than the L3 cache's 175 GB/s - and even lower than RAM bandwidth. That the Data Fabric interconnect also has to carry data from AMD's IO Hub PCIe lanes also potentially interferes with the (already meagre) available bandwidth
The difference in access speeds between 4 MB and 8 MB workloads can be explained through AMD's own admission that Ryzen's core design incurs in different access times depending on which parts of the L3 cache are accessed by the CCX. The fact that this memory is "mostly exclusive" - which means that other information may be stored on it that's not of immediate use to the task at hand - can be responsible for some memory accesses on its own. Since the L3 cache is essentially a victim cache, meaning that it is filled with the information that isn't able to fit onto the chips' L1 or L2 cache levels, this would mean that each CCX can only access up to 8 MB of L3 cache if any given workload uses no more than 4 cores from a given CCX. However, even if we were to distribute workload in-between two different cores from each CCX, so as to be able to access the entirety of the 1800X's 16 MB cache... we'd still be somewhat constrained by the inter-CCX bandwidth achieved by AMD's Data Fabric interconnect... 22 GB/s, which is much lower than the L3 cache's 175 GB/s - and even lower than RAM bandwidth. That the Data Fabric interconnect also has to carry data from AMD's IO Hub PCIe lanes also potentially interferes with the (already meagre) available bandwidth
AMD's Zen architecture is surely an interesting beast, and these kinds of results really go to show the amount of work, of give-and-take design that AMD had to go through in order to achieve a cost-effective, scalable, and at the same time performant architecture through its CCX modules. However, this kind of behavior may even go so far as to give us some answers with regards to Ryzen's lower than expected gaming performance, since games are well-known to be sensitive to a processor's cache performance profile.
Source:
Hardware.fr
Hardware.fr has done a pretty good job in exploring Ryzen's cache and memory subsystem deficiencies through the use of AIDA 64, in what would otherwise be an exceptional processor design. Namely, the fact that there seems to be some problem with Ryzen's L3 cache and memory subsystem implementation. Paired with the same memory configuration and at the same 3 GHz clocks, for instance, Ryzen's memory tests show memory latency results that are up to 30 ns higher (at 90 ns) than the average latency found on Intel's i7 6900K or even AMD's FX 8350 (both at around 60 ns).
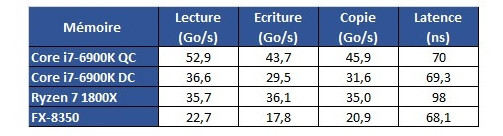
From some more testing results, we see that Intel's L1 cache is still leagues ahead from AMD's implementation; that AMD's L2 is overall faster than Intel's, though it does incur on a roughly 2 ns latency penalty; and that AMD's L3 memory is very much behind Intel's in all metrics but L3 cache copies, with latency being almost 3x greater than on Intel's 6900K.
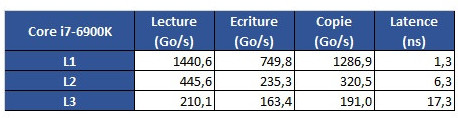
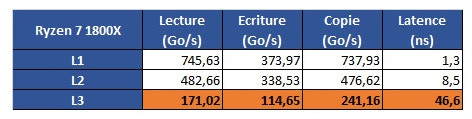
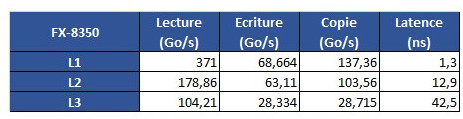
AMD's Zen architecture is surely an interesting beast, and these kinds of results really go to show the amount of work, of give-and-take design that AMD had to go through in order to achieve a cost-effective, scalable, and at the same time performant architecture through its CCX modules. However, this kind of behavior may even go so far as to give us some answers with regards to Ryzen's lower than expected gaming performance, since games are well-known to be sensitive to a processor's cache performance profile.
120 Comments on AMD's Ryzen Cache Analyzed - Improvements; Improveable; CCX Compromises
As I understand it**
Now the issue seems to be that as tasks are migrating from core to core is causing a lost in data access. If a task was on core 1 CCX 1 and got picked up by core 7 on CCX 2, all of the data related to that task in the L3 cache is gone. At that point the chip can either copy over the data from the L3 cache on CCX1 through the data fabric (22 GB/s shared with the memory controller) or let it get created naturally as the task starts from scratch with code paths in the L1 and L2 and finally the L3 when needed. Now multiple that happening 1000 fold because a game doesn't care what core is handling the math. This is what potentially is causing the drop in performance for some games.
What they have to do is either limit which logical cores can pick up a task or rework how the CPU handles these kinds of data shifts. Fixing the data fabric bandwidth, unifying the L3 cache into a true single 16 MB cache, of fixing the latency issue with memory would need to be fixed in future generations of the chip.
Archtectural and design completly diffrance in ryzen cpu and intel
There are many reson like
L3 cash in 6900 is 1 unit but L3 cash is 16 unit (1 for each block)
Lastly, why would AMD make their cache non-contiguous when that would create extra overhead and slow down the read and write speed as it would have to wait for data lines to be cleared (grounded or terminated to make sure no residual voltage created a false bit) between each segment being read or written to? Cache works on the same physics as all other memory systems.
Nothing better than getting up on a Sunday and keep talking about Ryzen, and if we already know that the platform is plagued with problems with RAM, because manufacturers have released their motherboards with BIOS beta, they are causing numerous problems with memory RAM, we now know that these problems greatly affect CPU performance.
These problems, present in all assemblers, such as MSI, Gigabyte, ASRock or Asus, has to do with RAM, which has problems working at its maximum speed, so depending on the motherboard may only work at 1866 MHz or 2400 MHz (as in our case) instead of the 3400 MHz that reaches the memory, and it is when we know that the memory influences much in the final performance, being able to see as in the software of benchmarking Geekbench, in the mononuclear test , Moving from a memory of 2133 MHz @ 3466 MHz implies no less than 10 percent extra performance.
In games, the same thing happens. With The Witcher 3, along with a GeForce GTX 1080 graphics, Full HD resolution and maximum graphics quality (with Hairworks off), we can see how the game reaches 92.5 FPS with a RAM DDR4 @ 2133 MHz , While if this memory is 3200 MHz we see how we get a gain of 14.9 FPS that makes us reach 107.4 FPS.
In this way, the first Ryzen reviews all score the same when using the same boards or memory modules, so it will not be until the motherboard manufacturers solve the problems when we can see the actual performance of the CPUs, Unlike Intel, the speed of memory does imply large differences in performance.
thnx google translate xd
Source:
www.eteknix.com/memory-speed-large-impact-ryzen-performance/
elchapuzasinformatico.com/2017/03/la-velocidad-la-ram-fuerte-impacto-rendimiento-amd-ryzen/ ..
1) Data lines (physical traces or wires allowing data to send or receive) and how many there are, and we have no idea as the architecture is not detailed to the public.
2) Clock rate (How fast the data is accessed) again we don't know the specifics, but through extrapolating data and using exploratory data sets we can gain some insight.
3) Latency (how many clock cycles between a request to read and the actual data showing up on the data lines) and we can figure this out if we know other things about the processor or by allowing a program to run and copy differing data sizes into a core or cache and then asking it to be read back and counting the number of clock cycles between.
What we don't have access to yet is a few key components and some software control that may allow us to force data into one cache, and allow us to copy between caches to determine the extra latency introduced by the transfer.
1 or 16 does NOT matter.
So you ask AMD for a octa core processor and we have now a dual quad core .
The design problem with 2 CCX interconnected trough an internal bus is a crime for gaming, maybe 10 years ago was a clear innovation.
Anyway this design can't be fixed by a BIOS update, even with more accurate values from AIDA64 beta and lower latency , the gaming on 8 core Ryzen will have to suffer. Games can be patched to use the main thread on one CCX and AI and others on second CCX, but that won't fix 100% the gaming experience.
Rysen 4 core probably will not suffer from the same issue, even if I read well the graph, the problem exist over 4M L3 also , but 4 core ryzen will be the best option for budget gamers.
This is the reason for which higher memory frequency will provide much better results as the bandwidth for inter-module communication increases with frequency. From 2133 to 3200 the bandwidth for internal communication increases from 34GB/s to 51GB/s, and that's why the witcher 3 benchmark posted above scales so well, not necessarily due to faster memory, which by itself has little impact as we saw numerous times, but because the communication between modules increases drastically with better memory frequency.
I'm waiting with more interes the R5 1400x. The the 1600x (6 core) will probably be plagued by the same issue.
I hope AMD give customers a generous trade-in program if such a revision is released. This will significantly boost confidence in the brand and make customers feel well looked after.
Thread handling is the job of the OS primarily unless the executables are updated to handle their own, and most just look to see how many threads to spawn based on cores and no further. But like Bulldozer if the OS assigns threads based on the CCX architecture there will be little or no penalty as the thread won't move unless it can benefit from the move.
* CCX0 C1 --> CCX4 C2 move costs 46 cycles of wait time for example, but CCX0 C0 to CCX1 C1 only costs 22 cycles. How many wasted cycles between every CCX and every core in every CCX. Does the penalty increase or remain the same depending on other CCX/cores being busy?
More information is needed before we can make broad statements, a better and more efficient thread handling/dispatching algorithm may increase the performance a lot.
forums.anandtech.com/threads/ryzen-strictly-technical.2500572/page-2#post-38770630
After confirming that there was a problem with L3 cache, they ran a custom-made program which was intended to perform cache usage incrementally higher and test latency. They clearly stated that the creator of the program did not checked it before using it on Ryzen, just to be clear.
The result in ns shown in green are the results of this custom-made test.
Sum up : as soon as a thread is moved from a core to another, it's cache is immediately pushed into this high latency cache, creating a huge drop in performance. The CCX architecture is not helping, neither bandwidth between them.
Since then, they try to isolate this behavior to prove Ryzen sensibility to core parking(which is not yet still proven or "that simple"). Not an easy task it seems, because of Windows 10 scheduler. And still, many manufacturers are not yet ready, and come to mess around with not suitable drivers and patches... Kinda annoying :/
Sorry for my poor English, and HFR team, just whip me if I'm saying some crappy things. I'm still (and you too as I understood), not quite sure what is the real underlying problem in the end ;)
forum.hardware.fr/hfr/Hardware/hfr/dossier-1800x-retour-sujet_1017196_20.htm#t10089095
They looked into it at Hardware.fr and said that the guy is not saying the truth, and that Core0/1/2/3 are sharing 8Mb and Core4/5/6/7 are sharing another 8Mb.
www.hardware.fr/articles/956-1/amd-ryzen-7-1800x-test-retour-amd.html ==> Page 80 if you speak french
This line : "****---- Unified Cache 1, Level 3, 8 MB, Assoc 16" Says : Core 0/1/2/3 share 8MB of L3
Or here "**------ Unified Cache 0, Level 2, 512 KB, Assoc 8" Says : Core 0/1 share 512KB of L2
and so on.
So it's some crappy analyze here, and they are pretty technical guys so they won't affirm it's crap unless it really is.
The fact is that on Windows 10, Core Parking is OFF in balanced mode with an Intel CPU (BDW-E, SKL for example), and ON on Ryzen. So you have to switch it off manually in order to compare apple to apple.
I was talking to someone else at that time who was comparing that value (98ns) to Aida64 stock values, which was not ok because of the clock being different ;).Yeah we've been working non-stop on Ryzen post launch, trying to figure out the issues we were seeing, time is way too short and sleep levels way too low :)Yeah again, to be 100% clear, we double checked with FinalWire what was accurate and wasn't according to them, our deep dive is exactly about trying to work around why some of the values reported aren't accurate, and go from there. It's by starting to track this down that we got to the CCX interconnect bandwidth limitation, the way split caches are handled in single thread etc etc.
Thanks for fixing your summary !
G.
Long story short, some Windows 10 Anniversary Update scheduler settings aren't set the same way for Ryzen and Intel CPUs. We tested that and updated our article accordingly.Actually the Witcher 3 "bench" is from a MSI/Intel advert (if I remember correctly).
But your overall point is exactly correct : data fabric clock is set with memory (so DDR4-2400 = 1200 MHz clock for that bus), so if you are limited there, you'll see a componding effect by pushing memory higher.