Thursday, May 17th 2018

Intel "Cannon Lake" Confirmed to Feature AVX-512 Instruction-Set
Intel updated the ARK information page for its stealthily launched 10 nm production chip, the Core i3-8121U "Cannon Lake," to confirm that the chip supports the new AVX-512 instruction-set. This is the first "mainstream" client-segment processor by the company to feature the extremely advanced instruction-set that, if implemented properly on the software side, can double performance/Watt compared to tasks that can take advantage of AVX2.
The instruction-set made its debut with the Xeon Phi "Knights Landing" HPC processor, and made its client-segment debut with the Core X "Skylake X" HEDT processors. It remains to be seen if the implementation of AVX-512 on "Cannon Lake" is complete, or if some instructions found on HPC processors such as the Xeon Phi are omitted due to irrelevance to the client platform.
The instruction-set made its debut with the Xeon Phi "Knights Landing" HPC processor, and made its client-segment debut with the Core X "Skylake X" HEDT processors. It remains to be seen if the implementation of AVX-512 on "Cannon Lake" is complete, or if some instructions found on HPC processors such as the Xeon Phi are omitted due to irrelevance to the client platform.
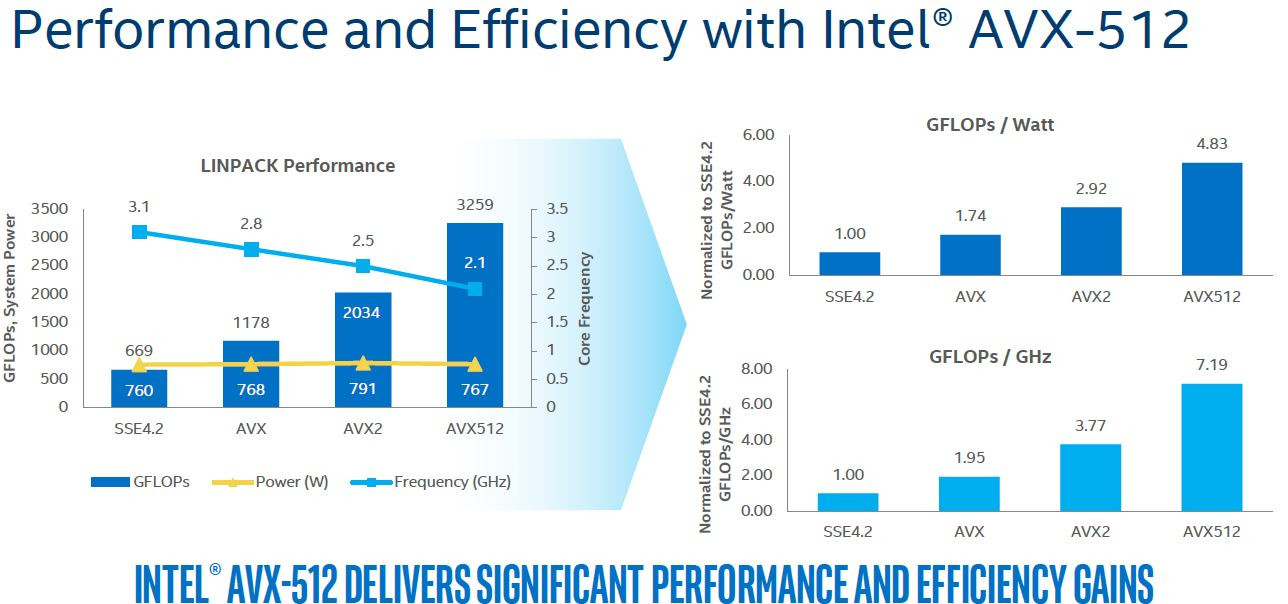
16 Comments on Intel "Cannon Lake" Confirmed to Feature AVX-512 Instruction-Set
Now we just have to wait for productive software to start utilizing this…
it not using lots of power, it not clocking down.
Unless you have a batch job avx is a total waste of time and performance loss, even at a batch job the improvements are lacking.
25% ipc boost, this is what everyone see, OH WOW 25% FASTER!!!
People go like: Hey, Software company\dude; why don't you have the new much faster AVX stuff implemented?
or, AVX is revolutionary so you need to buy skylake-s, ryzen sucks cause it doesn't have avx-512 blabla.
well, 25% sounds great does it?, well 25% ipc that is and 15% lower clocks due to power consumption thus a lot of the improvements are still there.
but even at 15% lower clocks the power consumption is still above what a normal nice workload using sse instruction sets.
click this link to read about the major issues with AVX and why people who bought into the 25% promised performance may be getting an "oh.. right" moment
avx info from a dev
Not saying AVX cannot be great and be used but currently it's a bit of a problem, and where you might find AVX great we have cuda, opencl with gpu acceleration doing most of the work so it's not too important in my eyes.
The major issue is getting vrm circuit ready for massive avx use...
It does not matter at all for your games or your browser running Facebook, but it makes a huge difference for work.Then you lack a basic understanding of how AVX works.
CUDA and OpenCL are great whenever you have a large chunk of data which can be processed by the GPU without being transferred back and forth very frequently. Switching between normal CPU registers and AVX registers are very cheap, and nearly "free" compared to transferring data between CPU cores or to a GPU.
I noticed that for the last couple of years Intel has trouble figuring out what features they should put in their products. They went from locking down AVX instructions of their lower end CPUs to now turning everything into a Xeon Phi.
Compute should run on a GPU , that's what they are designed for from the ground up and they do have a mostly useless poorly designed slab of silicon on almost all their CPUs to do that. Of course Intel doesn't like that so they keep shoving wider and wider SIMD extensions that come with convoluted trade-offs since you can't a have a high clocked CPU with many cores and very wide SIMD instructions at the same time. Too many design tensions.
the point was that avx is meant to replace sse for tasks running for minutes, at that point a gpu might as well be used.
also Smaller tasks using heavy avx is worthless.
AVX heavy is still beneficial when no gpu is present to do said work, but even at that point the avx improvements have been lost to lower clock speeds and the tounted 25% ipc is ipc and not effeciency nor speed which was my points against avx being our saviour.
I won't write off avx being an failure just that it does see some major hurdles and issues to gain more traction and is generally misunderstood by many because many do say that 25% ipc and it's a game changer while it's not, it has it's nichè's but that's about it.
I don't know where you got your "touted 25% IPC" figue. Do you even know what IPC means? People commonly throw around "IPC measurements" for various benchmarks which doesn't measure IPC at all. IPC means Instructions Per Clock, while vector operations such as SSE and AVX exploits data level parallelism, it doesn't increase the instructions per clock at all, but it does increase the computational throughput.
AVX doesn't even give "25%" performance increase, AVX2 offers an 8× increase over ALUs/FPUs for 32-bit operations, AVX-512 offers 16× for 32-bit operations. The performance gains of AVX depends on the application, ranging from ~30-50% and up to >10×, all depending on how computational intensive the application may be, and also how many AVX units the CPU features (e.g. Skylake-X have dual AVX-512 FMA units per core).
Edit: Gains in AVX can be even greater with FMA, which combines calculations like a + b × c into a single operation. Normally a CPU would calculate the a + b, then wait 14-19 clocks and do the multiplication. Doing this in a single operation saves a huge amount of otherwise wasted CPU cycles.
As mentioned, AVX is used in most heavy workloads, including video encoding, graphical editing, 3D modeling and CAD. Examples include Blender and FFMPEG.
AVX may also be used in libraries used by many applications, giving a smaller but still appreciated performance boost. Look at this benchmark of Ubuntu vs. Intel Clear Linux, which is recompiled with some AVX optimizations on libraries such as glibc etc. These benchmarks compare the competing 16 core Threadripper 1950x vs. the 10 core i9 7900X, and even though this is a Linux distribution made by Intel, it clearly displays examples where the 16-core Threadripper jumps from lagging behind the 10-core i9 to taking the lead. AVX is amazing and it should excite even AMD fans, if you still don't get it, you should get educated on this matter. When Zen eventually gets AVX-512 too, it will scale incredible well in some future applications.
These instructions seem to be very power efficient for the amount of performance they bring.
blog.cloudflare.com/on-the-dangers-of-intels-frequency-scaling/
This application specific hardware is essentially a whole algorithm implemented in hardware, and that's fine when you design a piece of hardware for a dedicated use case. But this hardware can't be upgraded in software to support new algorithms/codecs/standards. This might not be a big deal for a cell phone you toss away every other year anyway, but is annoying for hardware which is meant to last, both in the consumer or professional space. Intel have offered acceleration for AES-256, SHA-1 and various video codecs since Sandy Bridge, and have since then extended that to include "dead" formats like JPEG(!). The problem with this is an ever-increasing amount of die space and power consumed by dedicated accelerators, which all eventually become less relevant. This die space could have been spent on general ALUs, FPUs and vector/SIMD units, which can accelerate anything.
Regarding the complaint of frequency scaling with AVX. Even though AVX may operate at lower clocks than non-AVX instructions, they outperform any ALU/FPU operations by a factor of 10-20× or more, and is superior in terms of energy efficiency. The only thing beating SIMD in efficiency is application specific hardware, but then again this is application specific, making it useless for anything else. CPUs today have hit a frequency wall, and the amount of voltage needed to operate at ~5 GHz vs. ~4 GHz is extreme. There is no way we can continue to scale like this, and the aggressive boost from both Intel and AMD is already pushing it too far. The only way forward is increasing and balancing single ALUs/FPUs and SIMD units. A CPU with more actual throughput at lower clocks is still faster than one trying to push a little higher clocks.