Tuesday, October 23rd 2018

Intel Increases L1D and L2 Cache Sizes with "Ice Lake"
Intel's next major CPU microarchitecture being designed for the 10 nm silicon fabrication process, codenamed "Ice Lake," could introduce the first major core redesign in over three years. Keen observers of Geekbench database submissions of dual-core "Ice Lake" processor engineering samples noticed something curious - Intel has increased its L1 and L2 cache sizes from previous generations.
The L1 data cache has been enlarged to 48 KB from 32 KB of current-generation "Coffee Lake," and more interestingly, the L2 cache has been doubled in size to 512 KB, from 256 KB. The L1 instruction cache is still 32 KB in size, while the shared L3 cache for this dual-core chip is 4 MB. The "Ice Lake" chip in question is still a "mainstream" rendition of the microarchitecture, and not an enterprise version, which has had a "re-balanced" cache hierarchy since "Skylake-X," which combined large 1 MB L2 caches with relatively smaller shared L3 caches.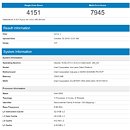
Source:
Geekbench Database
The L1 data cache has been enlarged to 48 KB from 32 KB of current-generation "Coffee Lake," and more interestingly, the L2 cache has been doubled in size to 512 KB, from 256 KB. The L1 instruction cache is still 32 KB in size, while the shared L3 cache for this dual-core chip is 4 MB. The "Ice Lake" chip in question is still a "mainstream" rendition of the microarchitecture, and not an enterprise version, which has had a "re-balanced" cache hierarchy since "Skylake-X," which combined large 1 MB L2 caches with relatively smaller shared L3 caches.
12 Comments on Intel Increases L1D and L2 Cache Sizes with "Ice Lake"
Programs that can fit in smaller cache should execute faster on older tech, if latency on bigger cache is higher.
Also, last L1 bump on "consumer grade" platform was with Conroe (from Netburst) and we have 256kB L2 since Nehalem (first gen Core I series).
Intel never released a large L3 caches per core on LGA11xx platforms (always 2MB/core max.).
(based on info around the web, may not be 100% accurate)
One thing I consider interesting is that Intel seem to prioritize L1 data cache while AMD prioritizes L1 instruction cache.What?
The L3 cache on Skylake-X works differently. Prior generations had an inclusive L3 cache, meaning L2 will be duplicated in L3, so effectively the L3 cache size of older generations is 1.75 MB. Skylake-X also quadrupled the L2 cache, leading to an effective increase in cache per core, but more importantly, a more efficient cache.Cache have always been more complex than just "more is better".
I believe even the old 80486 supported something like 512 kB of off-chip L2 cache.
For cache it comes down to latency, throughput and die space. Fewer banks may give higher cache efficiency, but lower bandwidth and higher complexity. More banks is simpler, gives higher bandwidth, but sacrifices cache efficiency. Latency is even tougher, it depends on the implementation.
browser.geekbench.com/v4/cpu/compare/9473563?baseline=10445533
I can't say Ice Lake is impressive - there are some gains but overall it's a minimal advantage.
And by the way, Ryzen uses victim cache too, similar to SKL-SP.
When ever a higher priority cache/memory is not enough, the system will use the next available, so if L1d is not enough, the next step is L2, when that is full then L3 comes (if available), and when there's L4 cache it will be the next level also, if not RAM will be used and so on.
Do you remember why the system becomes very slow when you have heavy applications and low RAM ? so upgrading RAM sped up your system noticeably then ? or when you finally upgraded to SSD and saw a huge jump in responsiveness and speed ? This what happens if the higher level cache/memory becomes too low and the system is forced to go for the next "slower" one.
When Intel first released Celeron, they experimented with L2 cache less one to make it cost less, it did cost less to make. But it performed horribly. They quickly scrapped that and the next update came with L2.
So why not having more and more of cache ? there's several things to consider:-
1- Cache are expensive: They require a lot of die area and consume power.
2- More cache brings latency: The larger the cache is the more time it takes to actually look for the data you need, and latency is crucial here.
3- Performance gain with more cache is not linear.
4- Architecture favouring: Duo to the second and third points, and how the architecture actually handles the data and cache hierarchy is working, there will be an optimal cache size for each level that brings the most performance at best power/cost. Adding more might rise the power/cost too much for little performance boost or might actually bring performance down a little for some latency critical applications.
To be precise, L1 is still a cache, the actual data being processed are in registers.
Even some introductory books in CS describe the cache hierarchy incorrectly. L1…L3 is just a streaming buffer, it contains code and data that is likely to be used or have been recently used. Many mistakenly think that the most important stuff is stored in L1, then L2 and so on. These caches are overwritten thousands of times per second, no data ever stays there for long. And it's not like your running program can fit in there, or your most important variables in code.
Modern CPUs do aggressive prefetching, which means it preloads data you might need. Each bank in the cache is a usually a Least Recently Used(LRU) queue, which means that any time one cache line is written, the oldest one is discarded. So caching things that are not needed may actually replace useful data. Depending on workload, the cache may at times be mostly wasted, but it's of course still better than no cache.SSDs does wonders for file operations, but only affects responsiveness when the OS is swapping heavily, and by that point the system is too sluggish anyway. There is a lot of placebo tied to the benefits of SSDs. Don't get me wrong, SSDs are good, but they don't make code faster.