Monday, April 5th 2021

AMD Patents Chiplet-based GPU Design With Active Cache Bridge
AMD on April 1st published a new patent application that seems to show the way its chiplet GPU design is moving towards. Before you say it, it's a patent application; there's no possibility for an April Fool's joke on this sort of move. The new patent develops on AMD's previous one, which only featured a passive bridge connecting the different GPU chiplets and their processing resources. If you want to read a slightly deeper dive of sorts on what chiplets are and why they are important for the future of graphics (and computing in general), look to this article here on TPU.
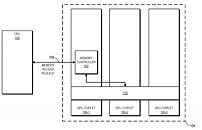
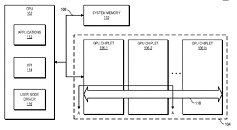
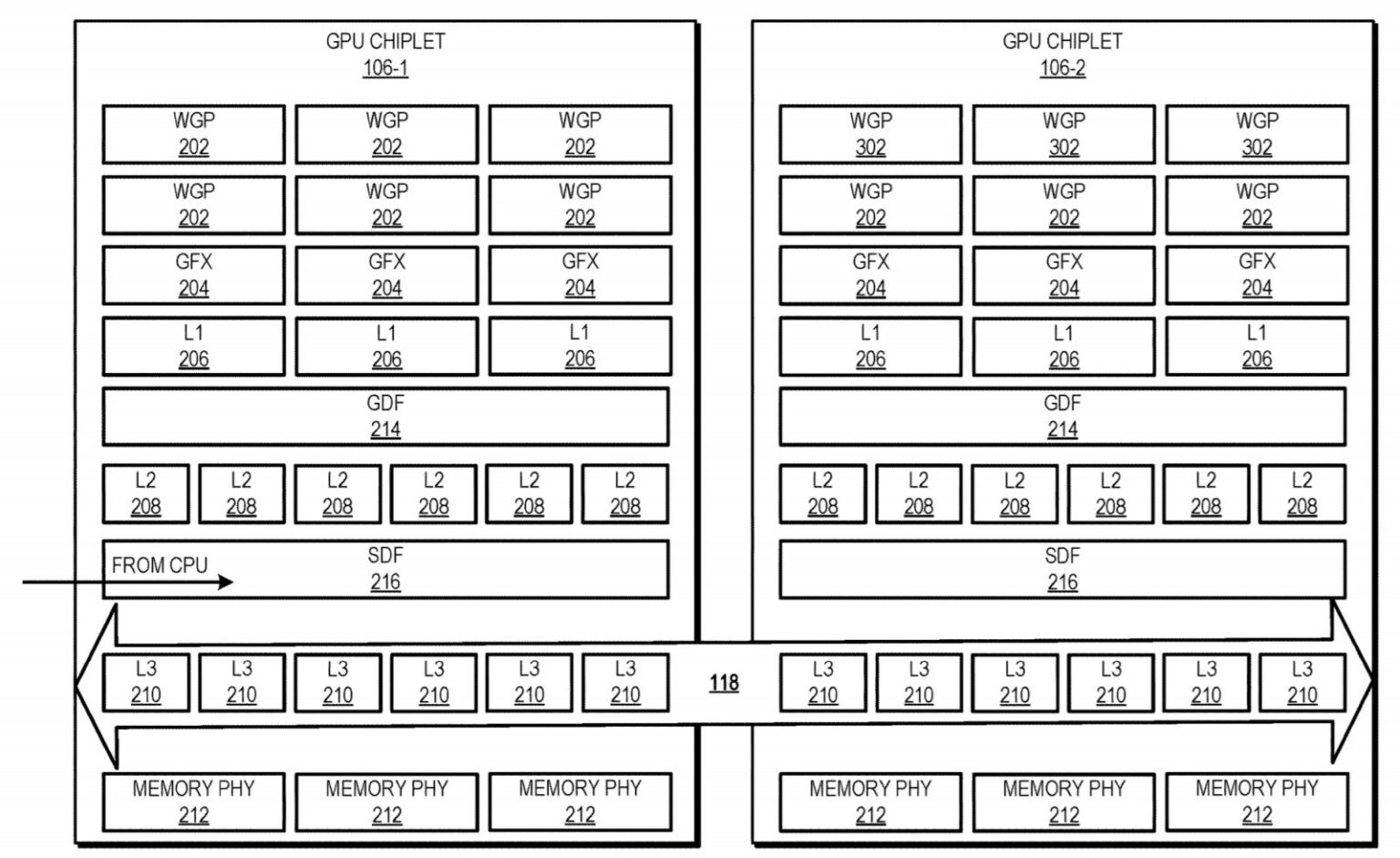
The new design interprets the active bridge connecting the chiplets as a last-level cache - think of it as L3, a unifying highway of data that is readily exposed to all the chiplets (in this patent, a three-chiplet design). It's essentially AMD's RDNA 2 Infinity Cache, though it's not only used as a cache here (and for good effect, if the Infinity Cache design on RDNA 2 and its performance uplift is anything to go by); it also serves as an active interconnect between the GPU chiplets that allow for the exchange and synchronization of information, whenever and however required. This also allows for the registry and cache to be exposed as a unified block for developers, abstracting them from having to program towards a system with a tri-way cache design. There are also of course yield benefits to be taken here, as there are with AMD's Zen chiplet designs, and the ability to scale up performance without any monolithic designs that are heavy in power requirements. The integrated, active cache bridge would also certainly help in reducing latency and maintaining chiplet processing coherency.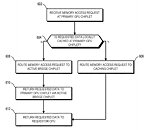

Sources:
Free Patents Online, via Videocardz
The new design interprets the active bridge connecting the chiplets as a last-level cache - think of it as L3, a unifying highway of data that is readily exposed to all the chiplets (in this patent, a three-chiplet design). It's essentially AMD's RDNA 2 Infinity Cache, though it's not only used as a cache here (and for good effect, if the Infinity Cache design on RDNA 2 and its performance uplift is anything to go by); it also serves as an active interconnect between the GPU chiplets that allow for the exchange and synchronization of information, whenever and however required. This also allows for the registry and cache to be exposed as a unified block for developers, abstracting them from having to program towards a system with a tri-way cache design. There are also of course yield benefits to be taken here, as there are with AMD's Zen chiplet designs, and the ability to scale up performance without any monolithic designs that are heavy in power requirements. The integrated, active cache bridge would also certainly help in reducing latency and maintaining chiplet processing coherency.



43 Comments on AMD Patents Chiplet-based GPU Design With Active Cache Bridge
Imagine 4 chiplets with 4Ghz boost speeds, a 2Ghz cache that is massively parallel with compression technology, a couple tiny chiplets for video encode/decode and for low power applications.
Now add on the stacked die tech that has been learned to create a parallel pipeline for pure vector math for Ray tracing stacked on each of the main 4 chiplets that can read and write to caches on the primary die. Ray tracing with the only performance penalty being extra heat and a fraction of the latency.
Bets: 3.5GHz gpus over the horizon, or not?
Gpus, do associate with high frequency because the power cost is already paid for. Remember Hawaii series? AMD never integrated tiled 'buffered' rasterization up until Vega and thus the memory interface never slowed down since it was always running in immediate mode whereas Nvidia can keep tabs at various memory clocks.
It could improve utilization if the shaders request at a higher rate - gpus are throughput oriented, after all...
Demand outstripped supply so far that even though TSMC is running FLAT OUT they still cannot keep up!
They now spending 100 BILLION DOLLATRS over the next three years to build more plants so they can deal with the demand.
Then you have people buying them by the millisecond so fast with their bots that you cannot buy them through normal channels making a bad situation even worse.
But hey they do it because they can make 25 to 50% profit selling on ebay and through the gray market.
AMD made the decision to focus on supplying computer manufacturers and not direct sellers like newegg and amazon.
I just got a 6800xt and 5600x from Dell.
Placed my order, waited a month and here it is! AND I got both for what appears to be MSRP or close to it.
Be sure you are looking at the BIG PICTURE before lambasting people and companies for things that are out of their control.
I'm not well versed enough, but there is no free lunch. SRAM offers much more than its substitutes.
Remember how the Infinity cache is placed around the CUs and not between them as to how you'd expect it to be ? I think it was a deliberate choice to place this huge chunk of cache on the extremities of the chip to reduce heat spots.
All AMD did was force Intel to get off their ass and make reasonable products at a more reasonable price, and even force down the price on their 10th gens, which is always good for everyone. If it weren't for them I wouldn't have a 12 core in my system right now, and would probably have to make do with 6 cores from Intel, on my old 8700.
Now, if they could make Ngreedia do the same, that'd be great... but I'm not having high hopes here. Unlike Intel, NVIDIA has never been sleeping. They are a worthy competitor to AMD. We'll see how this approach works on CDNA first - doubt the next RDNA gen will have this. Maybe the one after.