Monday, September 19th 2022

AMD Ryzen 9 7900X CPU-Z Benched, Falls Short of Core i7-12700K in ST, Probably Due to Temperature Throttling
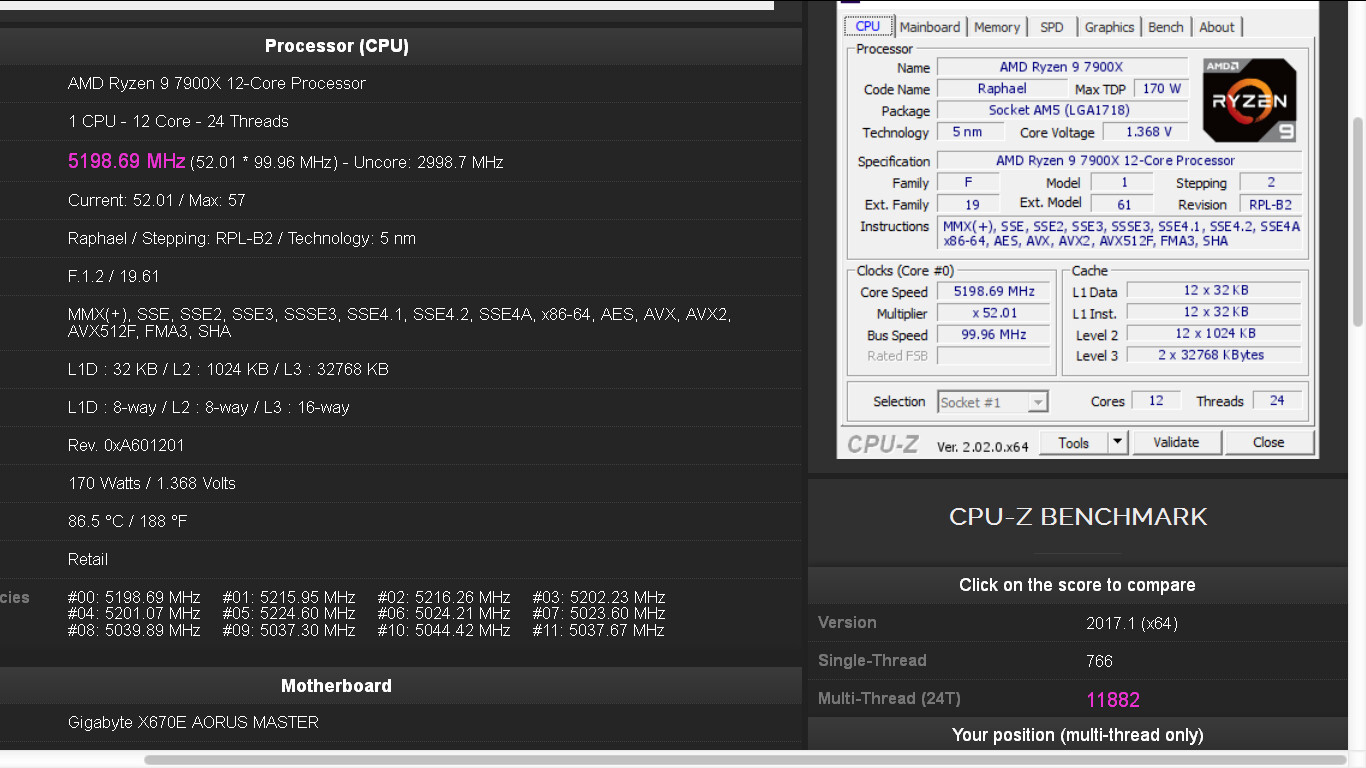
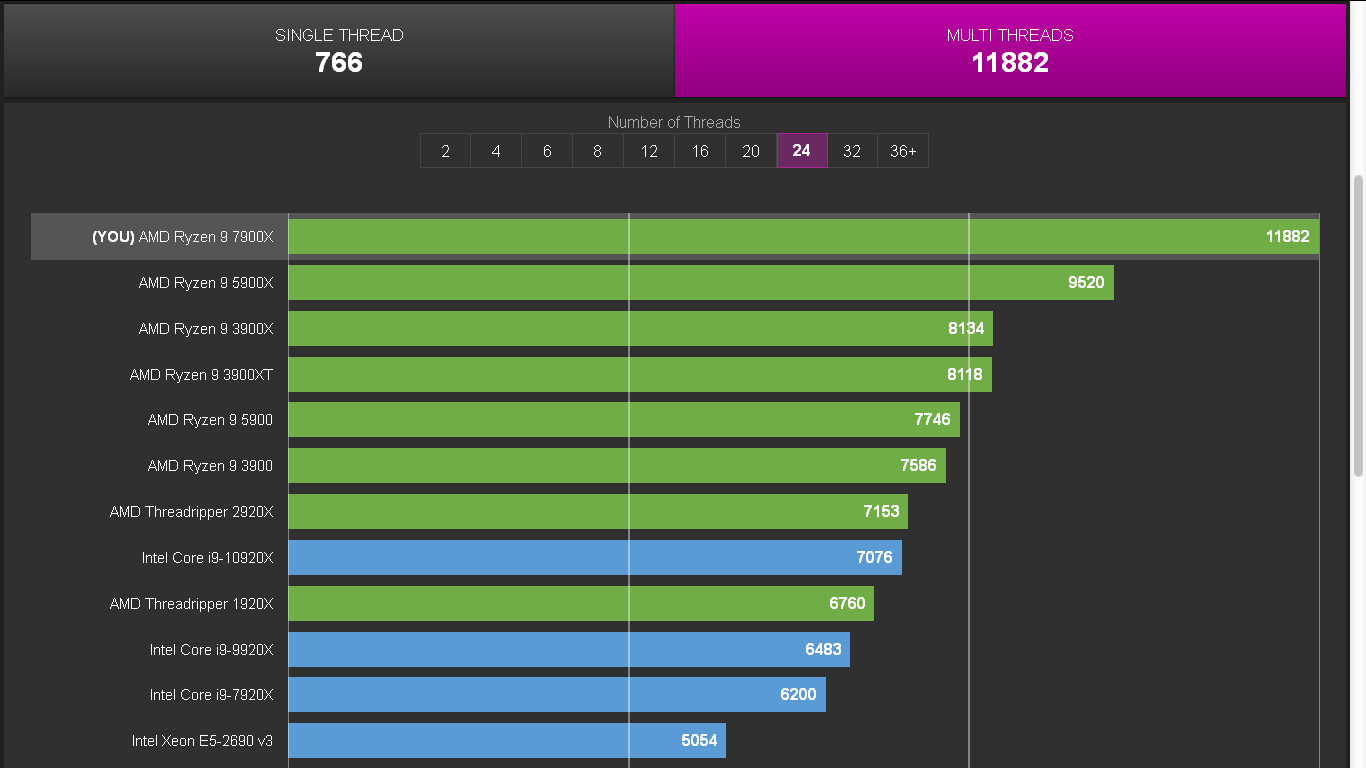
An AMD Ryzen 9 7900X 12-core/24-thread processor sample was put through CPU-Z Bench, the internal benchmark of the app. The chip boosted up to 5.20 GHz in the test, and ran at temperatures as high as 86°C, as reported by CPU-Z. It scored 766 points in the single-threaded test, and 11882 points in the multi-threaded one. The single-threaded numbers in particular are interesting. 766 points would put the 7900X behind the Core i7-12700K and its "Golden Cove" P-core by around 3%. In the multi-threaded test, however, the 7900X, with its 11822 points, is in the league of the next-generation Core i7-13700K (8P+8E) processor, which was recently spotted scoring 11877 points with a 6.20 GHz overclock. The 7900X will hence be pushed as a superior alternative to the i7-13700K for productivity and creator tasks, whereas its single-threaded score ensures that it falls behind the i7-13700K in gaming by a fair bit.



Sources:
Elchapuzas Informatico, TUM_APISAK (Twitter)


123 Comments on AMD Ryzen 9 7900X CPU-Z Benched, Falls Short of Core i7-12700K in ST, Probably Due to Temperature Throttling
I agree that AMD needs to focus on increasing IPC as increasing clocks is not a winning strategy for servers. However, servers don't need the highest single thread performance; overall throughput with acceptable single thread performance is the need there. Increasing core counts is the primary lever for this, and as interconnect power is already too high, they may opt for increasing the number of cores per CCD in the non Zen 4c cores as well.
A lot of uses don't really need floating point math, or frankly don't need much compute at all. This is one of the problems with looking at something like SPEC for servers. SPEC is good for measuring HPC application performance, but what percent of servers are spending any significant time doing that? My guess is something well below 5%.
Many implementations will use a DB2 database from a mainframe to serve up the data, and use an HPC compute platform to analyze that data, and then send results back. You use the right tool for the right task.
AMD's real power in the server space is concentrated on high core counts in small spaces with low heat density. Selling these cores off for cheap with low maintenance cost is in the area of cloud providers and web sites, neither of which really needs high IPC on any single thread. That is really where AMD excels, when you need to handle 10,000 people hitting your web page and you just need a bunch of cores to prevent context switch thrashing, but they don't need to be fast cores. I would call it 'front end' applications.
Back-end applications, the core density becomes a minor expense, and IPC matters. This is because of licensing costs. I'd rather have 48 very fast cores on a DB server than 96 slow ones, because every core I put on that database license costs me about $12,000. Do the math.
When you get into this area, for example benchmarking using TPC, nobody cares what CPU you are using. You're benchmarking a system, not a chip.
"Submission of a TPC-C result also requires the disclosure of the detailed pricing of the tested configuration, including hardware and software maintenance with 7/24 coverage over a three-year period. The priced system has to include not only the system itself, but also sufficient storage to hold the data generated by running the system at the quoted tpmC rate over a period of 60 days. "
en.wikipedia.org/wiki/TPC-C
Compute takes a big back seat to that 95% of the time. HPC is fun to talk about, but for example in TPC-C which basically simulates a complete supply chain from order entry to warehouse and inventory operations, it's going to care a whole lot more about how quickly you can move data than how quickly you can analyze it. A lot of that performance goes past just any single CPU core, and starts to look at how well you can scale up to for example 100 cpus and 4000 cores and still be able to move data around quickly.
Data analysis - which falls into the HPC arena where "IPC" according to something like SPEC - has grown in size, a lot, but the core is still all those mundane entering data, reporting on it, updating it, backing it up, serving it up to front end apps type of operations.
The SPEC measurements were done at a set clock speed, yes, that's how you measure Instructions Per Clock.
Cpu-Z wasn't.
It's already 2023, we need more than just 8 cores.
They could have offered a larger die with more cores, lower clocks but overall higher performance.
Secondly ADL succeeded 11th gen which had the same high clock speeds. AMD gets both IPC and massive clock speed improvements with Zen4. The jump from Zen3 to Zen4 will be quite large. I'm looking forward to making a Zen generation comparison chart.
CPU-Z is not running at a specific clock speed though, it's not a measure of IPC.
So if you take the combination of IPC measured by SPEC at a fixed clock, then throw in CPU-Z results, you start to get a picture.
Raptor Lake has higher IPC, Raptor Lake clocks higher, Raptor Lake wins on CPU-Z.
Is more needed? Of course, that's why I said earlier that what remains is how fast and efficient the cache and main memory are.
But for round one of IPC and raw Mhz to make use of that IPC, Raptor Lake appears to be winning.
Maybe try to pretend AMD is Intel and Intel is AMD for a minute and you can uncloud your bias enough to comprehend the obvious that is right in front of you.