Tuesday, July 25th 2023

Intel Previews AVX10 ISA, Next-Gen E-Cores to get AVX-512 Capabilities
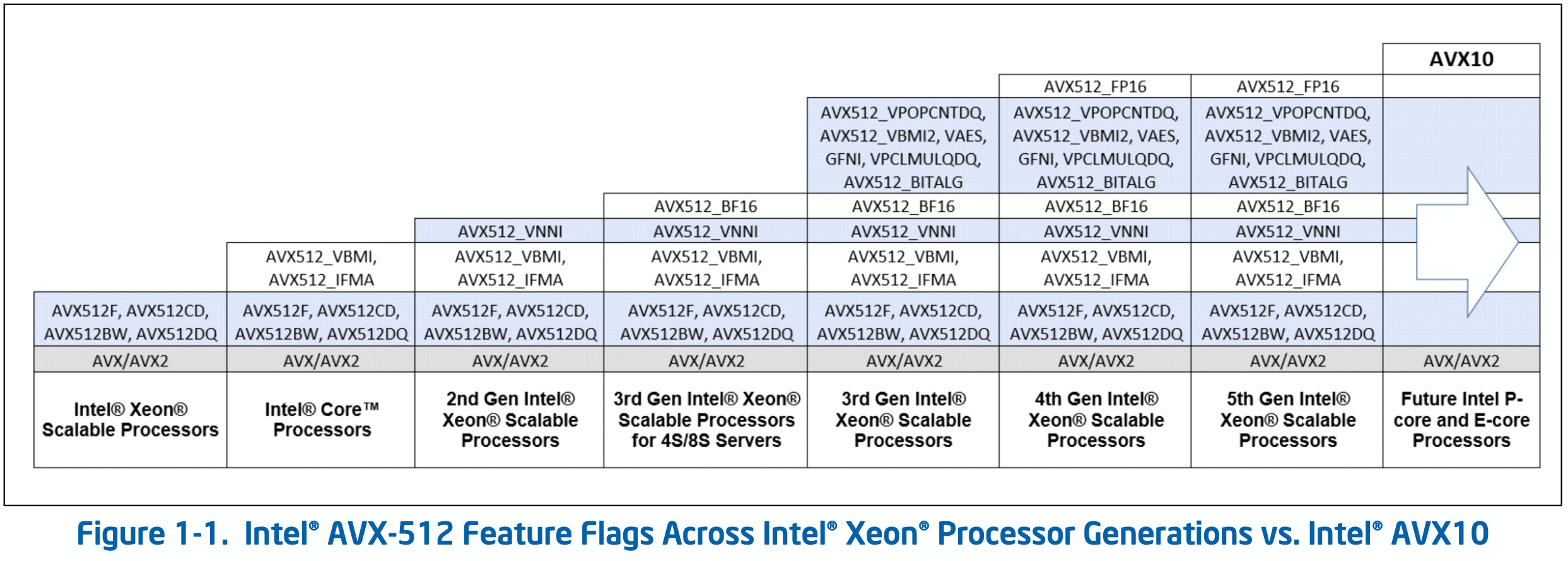
Intel has published a preview article covering its new AVX10 ISA (Instruction Set Architecture)—the announcement reveals that both P-Cores & E-Cores (on next-gen processors) will be getting support for AVX-512. Team Blue stated: "Intel AVX10 represents a major shift to supporting a high-performance vector ISA across future Intel processors. It allows the developer to maintain a single code-path that achieves high performance across all Intel platforms with the minimum of overhead checking for feature support. Future development of the Intel AVX10 ISA will continue to provide a rich, flexible, and consistent environment that optimally supports both Server and Client products."
Due to technical issues (E-core related), Intel decided to disable AVX-512 for Alder Lake and Raptor Lake client-oriented CPU lineups. AMD has recently adopted the fairly new instruction set for its Ryzen 7040 mobile series, so it is no wonder that Team Blue is attempting to reintroduce it in the near future—AVX-512 was last seen working properly on Rocket and Tiger Lake chips. AVX10 implementation is expected to debut with Granite Rapids (according to Longhorn), and VideoCardz reckons that Intel will get advanced instructions for Efficiency cores working with its Clearwater Forest CPU architecture.


Sources:
Intel Article, Tom's Hardware, VideoCardz, Phoronix, Wccftech
Due to technical issues (E-core related), Intel decided to disable AVX-512 for Alder Lake and Raptor Lake client-oriented CPU lineups. AMD has recently adopted the fairly new instruction set for its Ryzen 7040 mobile series, so it is no wonder that Team Blue is attempting to reintroduce it in the near future—AVX-512 was last seen working properly on Rocket and Tiger Lake chips. AVX10 implementation is expected to debut with Granite Rapids (according to Longhorn), and VideoCardz reckons that Intel will get advanced instructions for Efficiency cores working with its Clearwater Forest CPU architecture.


17 Comments on Intel Previews AVX10 ISA, Next-Gen E-Cores to get AVX-512 Capabilities
If MTL goes particularly poorly it will never make it to desktop (see also: Cannon Lake, Ice Lake) and that would set these projections back even further. Considering the only possible MTL benchmarks spotted in the wild have been for mobile parts I'm strongly suspecting this is the case, and Intel will just refresh gen13 on desktop and call it gen14, and these "gen14" desktop chips will desperately cram even more cores into an architecture that is long overdue for replacement. So if you thought Intel's CPU power consumption was bad before, hoo boy.
Also looks like its AVX 10.2 specifically that they will (re)add to consumer chips.
------------
All in all, this AVX10 and APX all looks like a good plan. But heck, AVX512 was a good plan and good idea overall IMO, just Intel screwed it up royally and somehow AMD's Zen4 implementation is superior.Just because the ISA is 512-bit doesn't mean that you have to lay out the fundamental circuit as 512-bit. AMD's 256-bit wide vector cores are executing AVX512 perfectly fine with high performance benefits.
In another example: AMD GCN is 2048-bit ultra-wide 64x32-bit GPU ISA, but was physically implemented with only 16x ALUs (aka; 512-bit wide physical implementation that executed 2048-bit code across 4-clock cycles). Etc. etc.
----------
My expectation is that this APX / AVX10 whatever stuff is good Intel Engineering, and that Intel's horrible management / business side hasn't figured out how to screw it up yet. But in practice, they will screw up this plan somehow.