Sunday, July 20th 2025

NVIDIA Brings Reasoning Models to Consumers Ranging from 1.5B to 32B Parameters
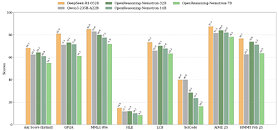
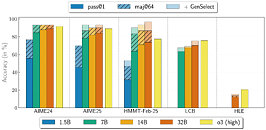
Today, NVIDIA unveiled OpenReasoning-Nemotron, a quartet of distilled reasoning models with 1.5B, 7B, 14B, and 32B parameters, all derived from the 671B-parameter DeepSeek R1 0528. By compressing that massive teacher into four leaner Qwen‑2.5-based students, NVIDIA is making advanced reasoning experiments accessible even on standard gaming rigs, without the need to worry about hefty GPU bills and cloud usage. The key is not some elaborate trick but raw data. Using the NeMo Skills pipeline, NVIDIA generated five million math, science, and code solutions, and then fine-tuned each one purely with supervised learning. Already, the 32B model hits an 89.2 on AIME24 and 73.8 on the HMMT February contest, while even the 1.5B variant manages a solid 55.5 and 31.5.
NVIDIA envisions these models serving as a powerful research toolkit. All four checkpoints will be available for download on Hugging Face, providing a strong baseline for exploring reinforcement-learning-driven reasoning or customizing the models for specific tasks. With GenSelect mode (which takes multiple passes for each question), you can spawn multiple parallel generations and pick the best answer, pushing the 32B model to outstanding performance that rivals or even exceeds OpenAI's o3‑high performance on several math and coding benchmarks. Since NVIDIA trained these models with supervised fine-tuning only, without reinforcement learning, the community has clean, state-of-the-art starting points for future RL experiments. For gamers and at-home enthusiasts, we get a model that can be very close to the state-of-the-art, entirely locally, if you have a more powerful gaming GPU.
Source:
NVIDIA
NVIDIA envisions these models serving as a powerful research toolkit. All four checkpoints will be available for download on Hugging Face, providing a strong baseline for exploring reinforcement-learning-driven reasoning or customizing the models for specific tasks. With GenSelect mode (which takes multiple passes for each question), you can spawn multiple parallel generations and pick the best answer, pushing the 32B model to outstanding performance that rivals or even exceeds OpenAI's o3‑high performance on several math and coding benchmarks. Since NVIDIA trained these models with supervised fine-tuning only, without reinforcement learning, the community has clean, state-of-the-art starting points for future RL experiments. For gamers and at-home enthusiasts, we get a model that can be very close to the state-of-the-art, entirely locally, if you have a more powerful gaming GPU.



5 Comments on NVIDIA Brings Reasoning Models to Consumers Ranging from 1.5B to 32B Parameters
:D
actually it's better that they end.
(Also quoted by Professor Moriarty in the ST: TNG episode "Elementary, Dear Data")
Coming to a theater near you REAL soon, are you ready ?