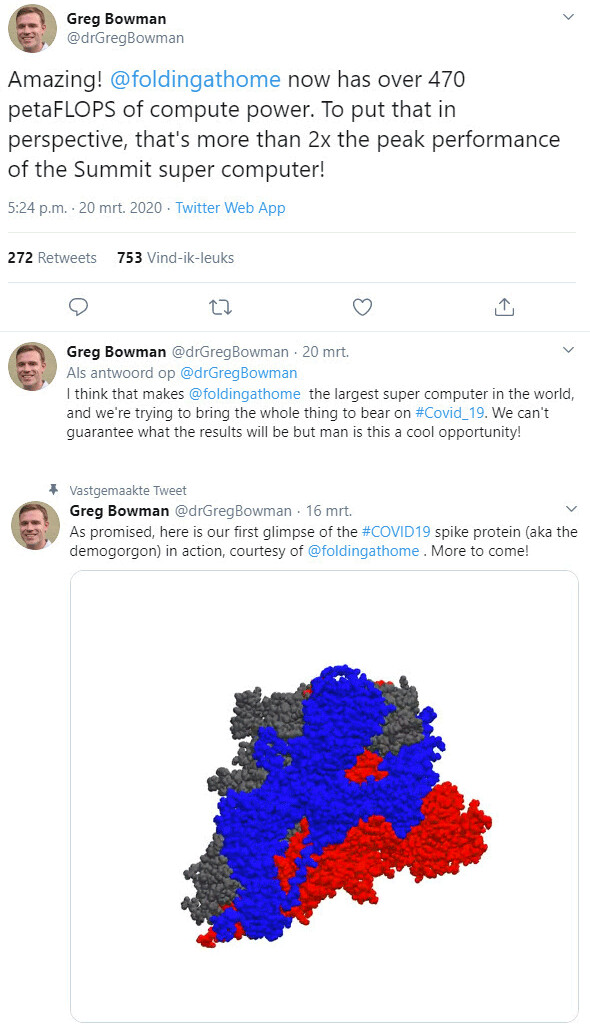
AMD Radeon RX 9070 GRE Spotted in GPU-Z v2.65.1 Support List
Earlier in the month, keen observers of Team Red activities were taken aback by whispers of a mysterious Radeon RX 9070 GRE GPU. Up until then, many assumed that AMD's engineering team was readying Radeon RX 9060 Series cards for launch in Q2'25. A source in China claimed that the next wave of RDNA 4 would arrive in the shape of a not-yet-official "Great Radeon Edition" (GRE) design; allegedly derived from Team Red's Navi 48 GPU die. Certain groups of skeptics have questioned the validity of this leak; many believe that the speculated Radeon RX 9060 XT model will launch ahead of a rumored GRE sibling.
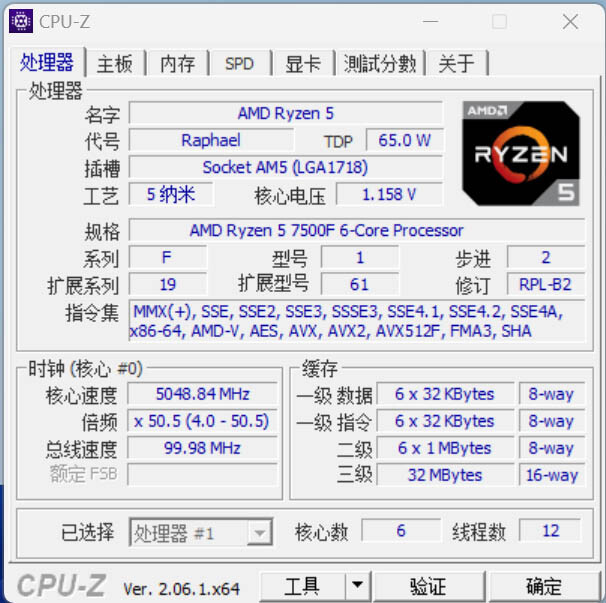
Late last week, TechPowerUp's GPU-Z utility was updated to version 2.65.0 form—supported hardware lists were populated with several new additions. As highlighted by VideoCardz, the presence of Radeon RX 9070 GRE and NVIDIA GeForce RTX 5060 Ti 16 GB GPUs points to potential imminent releases. In the case of Team Green, lower end "Blackwell" graphics cards are launching this week—as disclosed by insiders. AMD's Radeon RX 9070 GRE 12 GB card is expected to release as a Chinese market exclusive; possibly as a substitute for "difficult to acquire" Radeon RX 9070 16 GB (non-XT) AIB products.

Late last week, TechPowerUp's GPU-Z utility was updated to version 2.65.0 form—supported hardware lists were populated with several new additions. As highlighted by VideoCardz, the presence of Radeon RX 9070 GRE and NVIDIA GeForce RTX 5060 Ti 16 GB GPUs points to potential imminent releases. In the case of Team Green, lower end "Blackwell" graphics cards are launching this week—as disclosed by insiders. AMD's Radeon RX 9070 GRE 12 GB card is expected to release as a Chinese market exclusive; possibly as a substitute for "difficult to acquire" Radeon RX 9070 16 GB (non-XT) AIB products.