Monday, April 8th 2019

NVIDIA RTX Logic Increases TPC Area by 22% Compared to Non-RTX Turing
Public perception on NVIDIA's new RTX series of graphics cards was sometimes marred by an impression of wrong resource allocation from NVIDIA. The argument went that NVIDIA had greatly increased chip area by adding RTX functionality (in both its Tensor ad RT cores) that could have been better used for increased performance gains in shader-based, non-raytracing workloads. While the merits of ray tracing oas it stands (in terms of uptake from developers) are certainly worthy of discussion, it seems that NVIDIA didn't dedicate that much more die area to their RTX functionality - at least not to the tone of public perception.
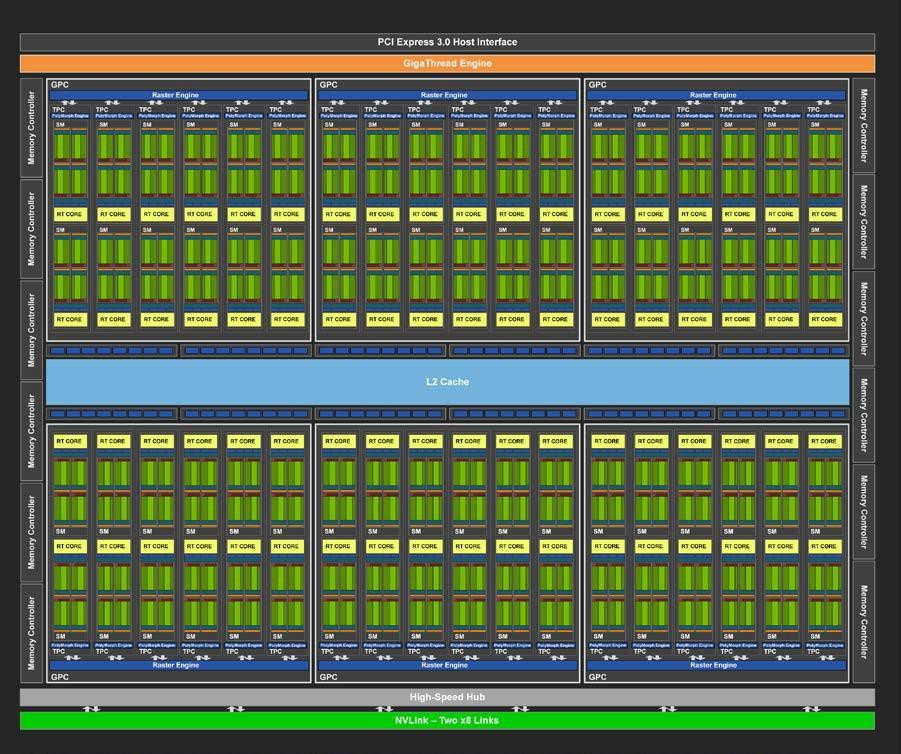
After analyzing full, high-res images of NVIDIA's TU106 and TU116 chips, reddit user @Qesa did some analysis on the TPC structure of NVIDIA's Turing chips, and arrived at the conclusion that the difference between NVIDIA's RTX-capable TU106 compared to their RTX-stripped TU116 amounts to a mere 1.95 mm² of additional logic per TPC - a 22% area increase. Of these, 1.25 mm² are reserved for the Tensor logic (which accelerates both DLSS and de-noising on ray-traced workloads), while only 0.7 mm² are being used for the RT cores.

 According to the math, this means that a TU102 chip used for the RTX 2080 Ti, which in its full configuration, has a 754 mm² area, could have done with a 684 mm² chip instead. It seems that most of the area increase compared to the Pascal architecture actually comes from increased performance (and size) of caches and larger instruction sets on Turing than from RTX functionality. Not accounting to area density achieved from the transition from 16 nm to 12 nm, a TU106 chip powering an RTX 2060 delivers around the same performance as the GP104 chip powering the GTX 1080 (410 mm² on the TU106 against 314 mm² on GP104), whilst carrying only 75% of the SM count (1920 versus 2560 SMs).
According to the math, this means that a TU102 chip used for the RTX 2080 Ti, which in its full configuration, has a 754 mm² area, could have done with a 684 mm² chip instead. It seems that most of the area increase compared to the Pascal architecture actually comes from increased performance (and size) of caches and larger instruction sets on Turing than from RTX functionality. Not accounting to area density achieved from the transition from 16 nm to 12 nm, a TU106 chip powering an RTX 2060 delivers around the same performance as the GP104 chip powering the GTX 1080 (410 mm² on the TU106 against 314 mm² on GP104), whilst carrying only 75% of the SM count (1920 versus 2560 SMs).
Source:
Reddit @ User Qesa
After analyzing full, high-res images of NVIDIA's TU106 and TU116 chips, reddit user @Qesa did some analysis on the TPC structure of NVIDIA's Turing chips, and arrived at the conclusion that the difference between NVIDIA's RTX-capable TU106 compared to their RTX-stripped TU116 amounts to a mere 1.95 mm² of additional logic per TPC - a 22% area increase. Of these, 1.25 mm² are reserved for the Tensor logic (which accelerates both DLSS and de-noising on ray-traced workloads), while only 0.7 mm² are being used for the RT cores.


22 Comments on NVIDIA RTX Logic Increases TPC Area by 22% Compared to Non-RTX Turing
It makes me question whether Turing actually improved on pascal at all. Similar performance for a given footprint. Im guessing where it comes in handy is when you scale it to larger chips where having a lesser number of more powerful cores is more manageable and scales better. Perhaps nvidias architecture also has a core count cap similar to hoe GCN caps at 4096?
And as for tensor cores; they are the most useless things in a gaming card as far as I am concerned.
That simple figure doesn't account for the extra caches to feed them , they're likely to have increased in size to accommodate them, so 25-27% if we throw fp16 hardware too I would think.
Seams odd anyway , I like chip pic's like anyone but,
It's a bit late to be pushing this angle IMHO.
Even more concerning is how much in percentages these things take from the power budget. 12nm didn't bring any notable efficiency gains and Turing only uses slightly more power than their Pascal equivalent does. But we now know RT and Tensor cores uses about a fifth of the silicon, I have a suspicion that when this silicon is in use it doesn't just cause the GPU to use more power but it may actually eat away at the power budget the other parts of the chip would otherwise get performing traditional shading.
Edit: I see now.
With a slight overclock, we could have the performance of 1080ti with the price of a 1080.
All of that was lost because some RTX holy grail "Just Works".
It works so well that after 6 months of launch, nobody can utilize all of the RTX features in a single game.
And DLSS is such a gimmick feature that have to beg The leather jacket himself to fire up his multi-billion AI computer to train for your multi-million AAAAA loot box micro - transaction "game" in the first place.
Thank you Leather Jacket.
Praise the Leather Jacket.
Just like an Intel CPU had almost half of its die size populated by the i-GPU.
Therefore decreasing TPC size by 22% only results a 10% reduction in overall die size.
NVidia have totally screwed up on price/performance and there is no getting away from that.
It would be nice if NVidia could give us some cards that "just work for the price" next time they launch a new architecture.
Epic fail NVidia, it is enough to make Alan Turing eat an apple.
This news article says nothing against the claim that about 17-20% of the die is needed for RTRT with Turing which, given the die schematic still looks plausible to me. All things considered the architecture does not perform much better (per watt) than Pascal in regular loads, its hit or miss in that sense. The real comparison here is die size vs absolute performance on non-RT workloads for Pascal versus Turing. The rest only serves to make matters complicated for no benefit.Makes two (and probably many more). Its a pretty complicated test I think, but I think the best way to get a handle on it, is to put Turing RTX and non-RTX next to Pascal and test at fixed FPS all cards can manage, then measure power consumption. That is with the assumption that we accept Pascal and Turing to have a ballpark equal perf/watt figure; though you could probably apply a formula for any deviation as well; the problem here is that its not linear per game.
You can mitigate that by locking the FPS to a set value, but then you're not stressing the hardware enough :(
- RTX2070 (2304:144:64 and 8GB GDDR6 on 256-bit bus) vs GTX1070Ti (2432:125:64 and 8GB GDDR5 on 256-bit bus) is the closest comparison we can make. And even here, shaders, TMUs and memory type are different and we cannot make an exact correction for it. Memory we could account for roughly but more shaders and less TMUs on GTX is tough.
- RTX2080 (2944:184:64 and 8GB GDDR6 on 256-bit bus) vs GTX1080Ti (3584:224:88 and 11GB GDDR5X on 352-bit bus) is definitely closer in performance at stock but discrepancy in individual resources is larger, mostly due to larger memory controller along with associated ROPs.
The other question is which games/tests to run. Anything that is able to utilize new features in Turing either inherently (some concurrent INT+FP) or with dev support (RPM) will do better and is likely to better justify the additional cost.
Tom's Hardware Germany did try running RTX2080Ti at lower power limits and comparison in Metro Last Light: Redux. It ties to GTX 1080Ti (2GHz and 280W) at around 160W.
www.tomshw.de/2019/04/04/nvidia-geforce-rtx-2080-ti-im-grossen-effizienz-test-von-140-bis-340-watt-igorslab/
However, this is a very flawed comparison as RTX2080Ti has 21% more shaders and TMUs along with 27% more memory bandwidth. This guy overclocked the memory on 2080Ti from 1750MHz to 2150MHz making the memory bandwidth difference 56%. Lowering the power limit lowers the core clock (slightly above 1GHz at 160W) but does not reduce memory bandwidth.
Edit: Actually, in that Tom's Hardware Germany comparison, RTX2080Ti runs at roughly 2GHz at 340W. Considering that it has 21% more shaders than GTX 1080Ti we can roughly calculate the power consumption for comparison - 340W / 1.21 = 280.1W which is very close to GTX1080Ti's 280W number. This means shaders are consuming roughly the same amount of power. At the same time, performance is up 47% in average FPS and 57% in min FPS. Turing does appear to be more efficient even in old games but not by very much.
It would be nice to mark the different functional parts on the infrared photo. I think the RT is still there, in no way RT can be 4%.