Tuesday, August 18th 2020

Microsoft Details Xbox Series X SoC, Drops More Details on RDNA2 Architecture and Zen 2 CPU Enhancements
Microsoft in its Hot Chips 32 presentation detailed the SoC at the heart of the upcoming Xbox Series X entertainment system. The chip mostly uses AMD IP blocks, and is built on TSMC N7e (enhanced 7 nm) process. It is a 360.4 mm² die with a transistor count of 15.3 billion. Microsoft spoke about the nuts and bolts of the SoC, including its largest component - the GPU based on AMD's new RDNA2 graphics architecture. The GPU takes up much of the chip's die area, and has a raw SIMD throughput of 12 TFLOP/s. It meets DirectX 12 Ultimate logo requirements, supporting hardware-accelerated ray-tracing.
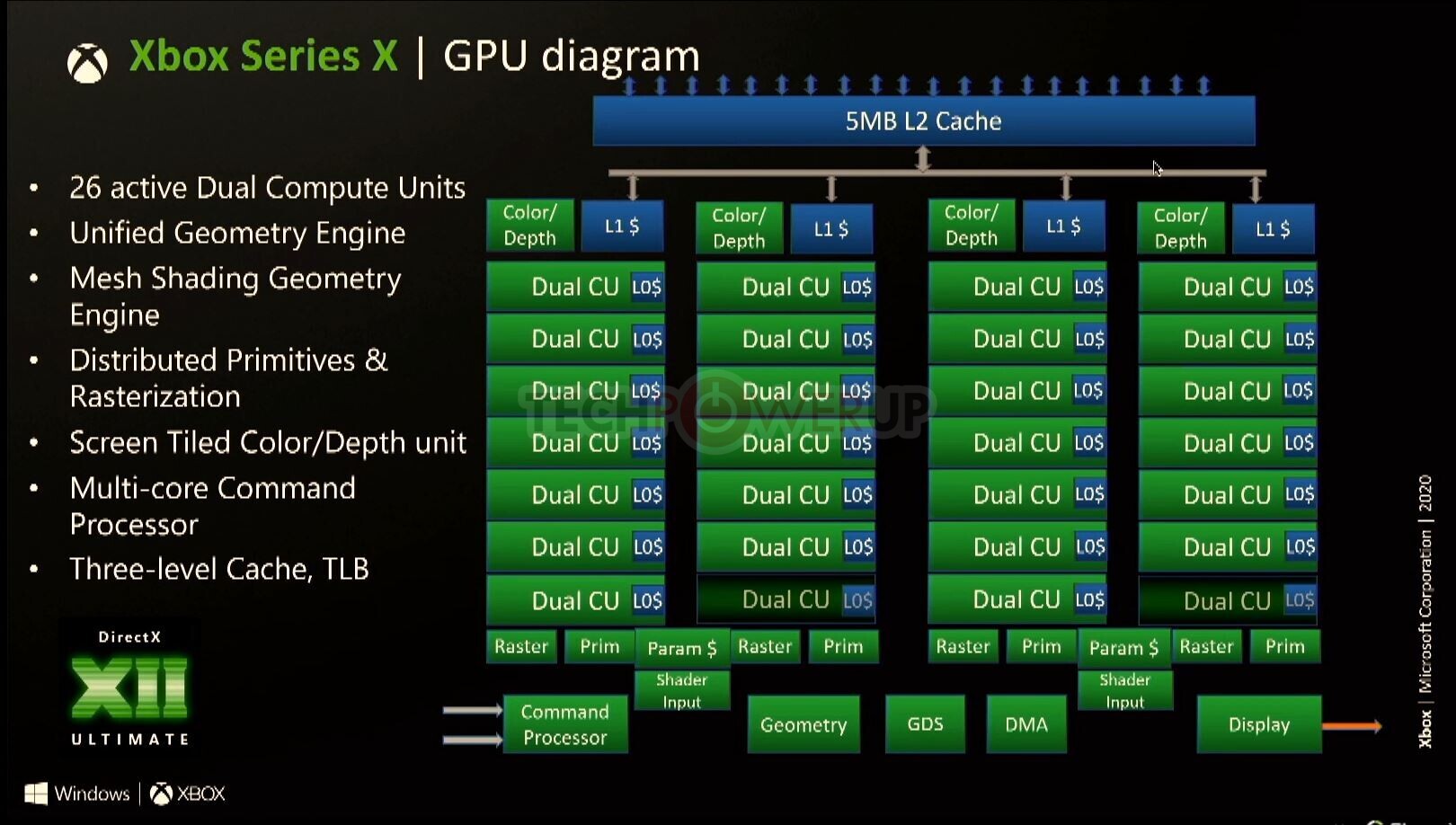
The RDNA2 GPU powering the Xbox Series X SoC features 52 compute units spread across 26 RDNA2 dual compute units. The silicon itself physically features two additional dual CUs (taking the total physical CU count to 56), but are disabled (possibly harvesting headroom). We've detailed first-generation RDNA architecture in the "architecture" pages of our first AMD Radeon RX 5000-series "Navi" graphics card reviews, which explains much of the SIMD-level innovations from AMD that help it drive a massive SIMD IPC gain over the previous-generation GCN architecture. This hierarchy is largely carried over to RDNA2, but with the addition of a few SIMD-level components.


 The RDNA2 SIMD (dual compute unit), as detailed by Microsoft in its Xbox Series X SoC presentation, appears similar to that of the original RDNA, with four SIMD32 ALU clusters sharing instruction- and scalar caches. A major difference here is the addition of Intersection Engine components on a per-CU basis (two per dual CU), which Microsoft labels out as "ray-tracing accelerators." The Intersection Engine is a component that's functionally similar to the RT cores found in NVIDIA "Turing" GPUs - its job is to calculate the point of intersection between a ray and a triangle, which makes up BVH - a vital component of hardware ray-tracing. Each RDNA2 dual CU features a total of 128 stream processors.
The RDNA2 SIMD (dual compute unit), as detailed by Microsoft in its Xbox Series X SoC presentation, appears similar to that of the original RDNA, with four SIMD32 ALU clusters sharing instruction- and scalar caches. A major difference here is the addition of Intersection Engine components on a per-CU basis (two per dual CU), which Microsoft labels out as "ray-tracing accelerators." The Intersection Engine is a component that's functionally similar to the RT cores found in NVIDIA "Turing" GPUs - its job is to calculate the point of intersection between a ray and a triangle, which makes up BVH - a vital component of hardware ray-tracing. Each RDNA2 dual CU features a total of 128 stream processors.


 As implemented on the Microsoft SoC, the RDNA2 GPU features a unified geometry engine, hardware support for Mesh Shaders (the other major component of D3D12 Ultimate feature set), a multi-core command processor, multiple Prim and Raster units, and screen tiled color/depth unit. The GPU features a dedicated 3-level cache hierarchy, with L0 caches, shared L1 cache per shader engine, and a shared 5 MB L3 cache.
As implemented on the Microsoft SoC, the RDNA2 GPU features a unified geometry engine, hardware support for Mesh Shaders (the other major component of D3D12 Ultimate feature set), a multi-core command processor, multiple Prim and Raster units, and screen tiled color/depth unit. The GPU features a dedicated 3-level cache hierarchy, with L0 caches, shared L1 cache per shader engine, and a shared 5 MB L3 cache.
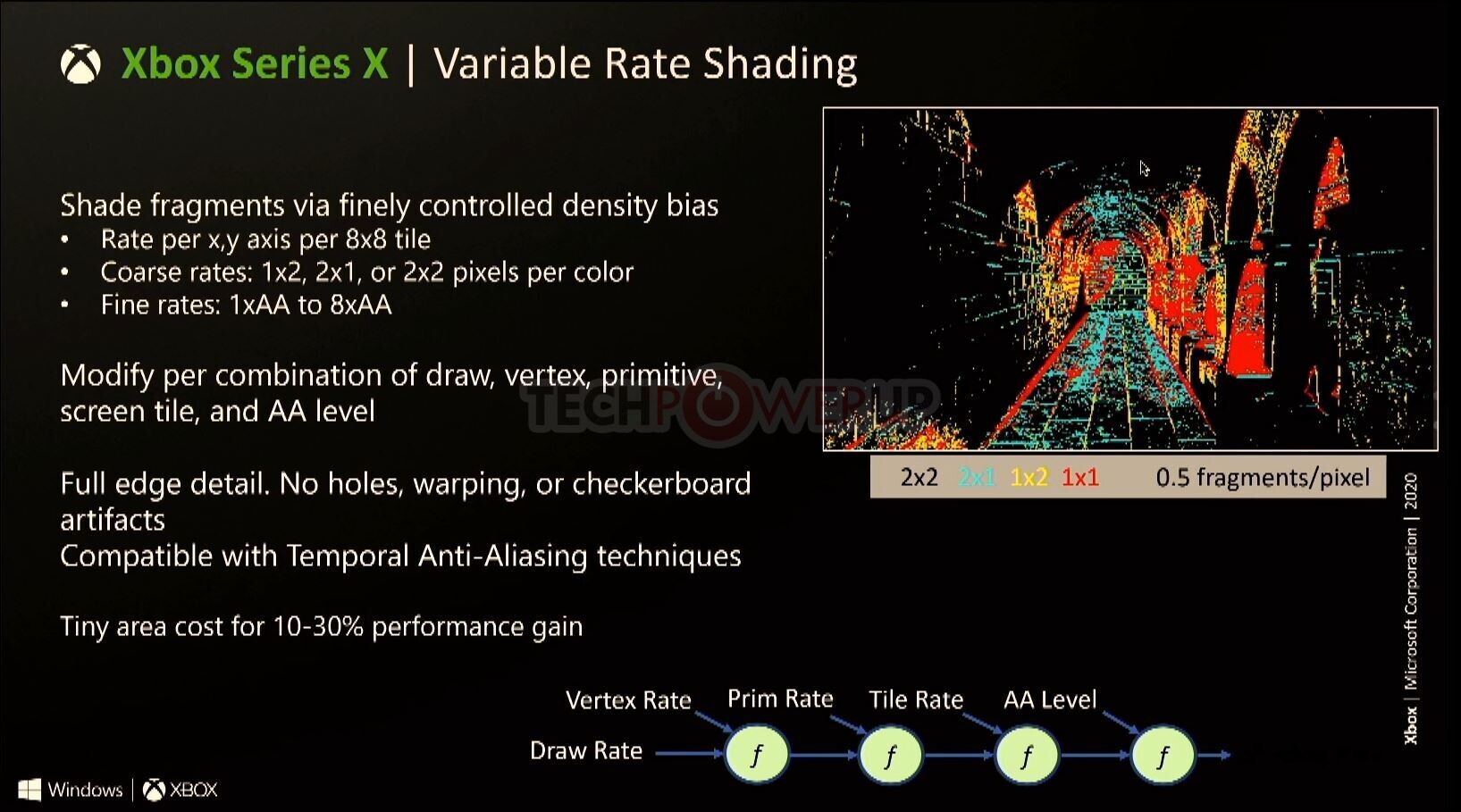
 Besides ray-tracing and mesh shaders, the GPU supports the two other components that make up the D3D12U feature-set, including Variable Rate Shading (VRS), and Sampler Feedback Streaming, and an Xbox-exclusive Custom Residency Map Filtering. The Display- and Media-controllers are significantly modernized over the previous-generation Xbox One, with support for HDMI 2.0b, and hardware decode for modern media formats.
Besides ray-tracing and mesh shaders, the GPU supports the two other components that make up the D3D12U feature-set, including Variable Rate Shading (VRS), and Sampler Feedback Streaming, and an Xbox-exclusive Custom Residency Map Filtering. The Display- and Media-controllers are significantly modernized over the previous-generation Xbox One, with support for HDMI 2.0b, and hardware decode for modern media formats.
As for the CPU, as is already known, the Xbox Series X SoC features 8 CPU cores based on the AMD "Zen 2" microarchitecture. It turns out, that these cores are spread across two CCXs that largely resemble those on AMD's "Renoir" APU, configured with 4 MB of shared L3 cache per CCX. With SMT off, these cores run at a frequency of up to 3.80 GHz, and up to 3.60 GHz with SMT on. The CPU core ISA is largely identical to that of the "Zen 2" cores on AMD Ryzen processors, with the addition of the SPLEAP extension (security privilege level execution and attack protection), which works to prevent privilege escalation attacks. This is a Microsoft-developed hardware component that was present in the "Jaguar" cores that powered the Xbox One SoC, but were ported to "Zen 2." The SoC uses a 320-bit GDDR6 memory interface, with partitioned GDDR6 being used both as video memory and system memory.
The RDNA2 GPU powering the Xbox Series X SoC features 52 compute units spread across 26 RDNA2 dual compute units. The silicon itself physically features two additional dual CUs (taking the total physical CU count to 56), but are disabled (possibly harvesting headroom). We've detailed first-generation RDNA architecture in the "architecture" pages of our first AMD Radeon RX 5000-series "Navi" graphics card reviews, which explains much of the SIMD-level innovations from AMD that help it drive a massive SIMD IPC gain over the previous-generation GCN architecture. This hierarchy is largely carried over to RDNA2, but with the addition of a few SIMD-level components.


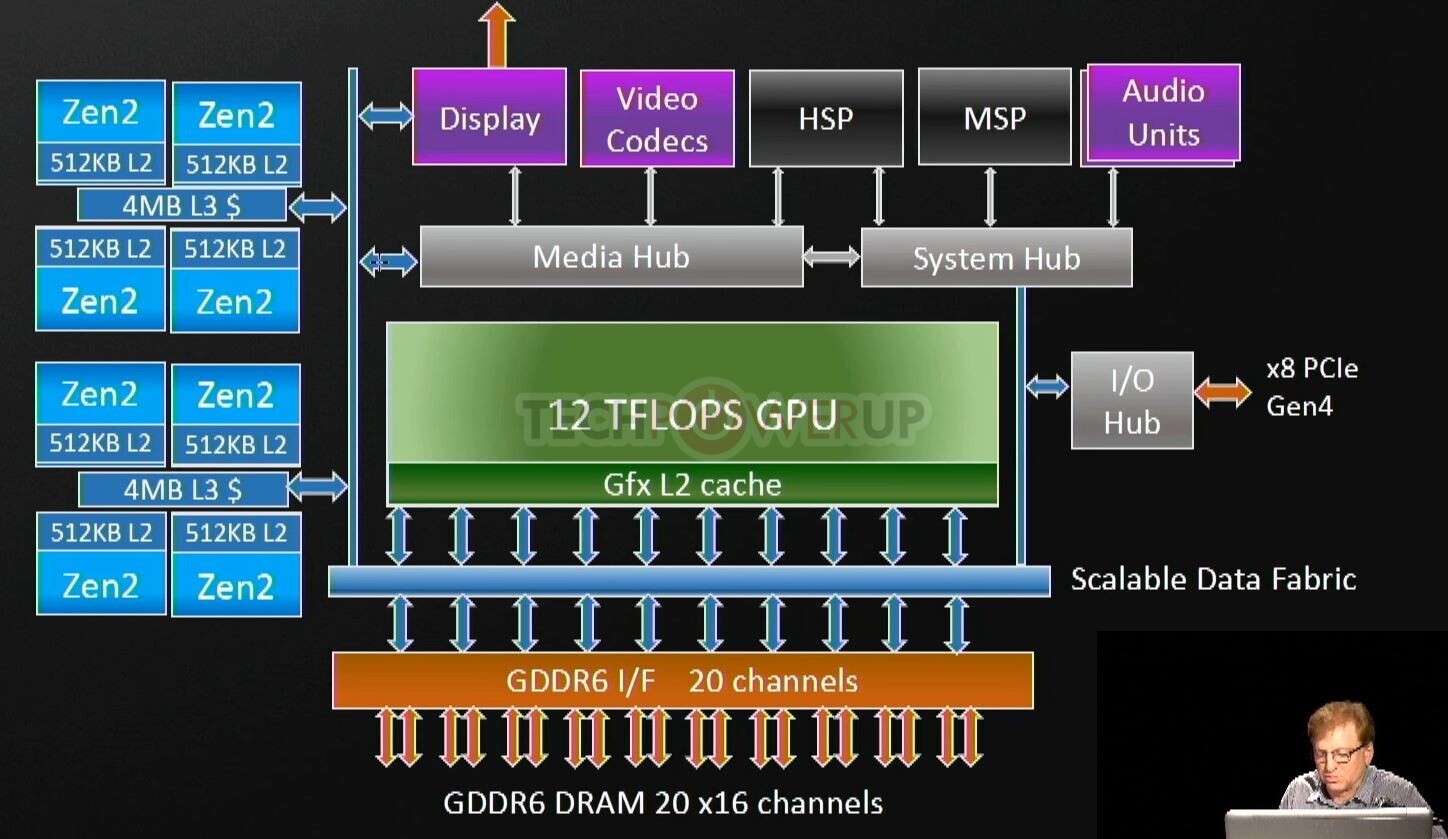





As for the CPU, as is already known, the Xbox Series X SoC features 8 CPU cores based on the AMD "Zen 2" microarchitecture. It turns out, that these cores are spread across two CCXs that largely resemble those on AMD's "Renoir" APU, configured with 4 MB of shared L3 cache per CCX. With SMT off, these cores run at a frequency of up to 3.80 GHz, and up to 3.60 GHz with SMT on. The CPU core ISA is largely identical to that of the "Zen 2" cores on AMD Ryzen processors, with the addition of the SPLEAP extension (security privilege level execution and attack protection), which works to prevent privilege escalation attacks. This is a Microsoft-developed hardware component that was present in the "Jaguar" cores that powered the Xbox One SoC, but were ported to "Zen 2." The SoC uses a 320-bit GDDR6 memory interface, with partitioned GDDR6 being used both as video memory and system memory.
38 Comments on Microsoft Details Xbox Series X SoC, Drops More Details on RDNA2 Architecture and Zen 2 CPU Enhancements
Thank you based AMD.
Now bring it somewhere outside of this console, but silently. Nobody needs to know about this. :)
First they don't want to cannibalize their own discrete gfx cards.
Also HBM memory must get cheaper to make this happen since they need super fast memory on a substrate with the APU.
Each CU is smaller than rdna1.
it has improved IPC.
so it's a lot of changes, but the cu's on rdna1 was no worse than turing in terms of ipc.
It's a shame that it's taken 14 years to get here, and it's also a shame that it's console-exclusive.
Mainstream PCs stuck on DDR4 rather than using GDDR6 is dumb, especially given how many consumers now use laptops with fully-soldered BGA everything.
Yea, there's a possibility RDNA2 might has some DLSS-like upscaling feature.
Why isn't anyone questioning these numbers ? The 2080 ti makes 10Grays/s, so the Xbox chip(cut down) is 9~38x faster in RT ? What about Big Navi ? Will it be 20x~50x faster in RT ?
With what microsoft has released so far it does not look very strong. Rasterization performance by itself is not even gonna be able to push a consistent 4k60fps, and you think a first gen RT hardware from AMD can handle RTRT at 4k60fps? Not gonna happen.
Its clear that the benchmarks between NVidia and AMD aren't compatible at all. Ultimately, we'll just have to wait until a standard raytrace scene is made (like IceMark or something) and run it on both systems.They're clearly relying upon variable-rate shading to get the job done.
By cutting down to 2x1, 1x2, and 2x2 regions, you're basically rendering "some" locations at 1080p instead of 4k. If a large enough region is declared 2x2, you get closer to 1080p-like performance. They key is having artists indicate which meshes should be shaded at 2x2 (Effectively 1080p), and which sections should be shaded at 1x1 (effectively 4k), and inbetween (2x1 and 1x2: depending if an area has horizontal patterns or vertical patterns to preserve).
A lot of backgrounds get field-of-depth blurred anyway (fog effects and whatnot). Those areas can probably be rendered at 2x2 without anyone noticing, especially because it'd go through a blur-filter anyway. Some areas of low-geometry (ie: Skymap) might be rendered at 1x1 without much performance loss.
I mean, look at the example variable-rate image:
Nearly the entire freaking scene is black (2x2), which means its effectively a 1080p level of rendering. Only a very small area is 1x1 (aka: actually 4k).
No more staircase effect, no need for multisampling.
I accept there will always be a few segments where APUs aren't suitable, things like very specialist server and AI stuff as the ratios of CPU vs GPU vs memory is very different or the ultra high end enthusiast market where cost is not a factor and it’s all about highest performance at any wattage but for the most part APUs are the future of all other segments. They already have low cost builds sown up and we should be seeing low end turning into mid range then hopefully moving to high end.
In the next few years both AMD and Intel will have the ability to build APUs with massive CPU performance, massive GPU performance and enough HBM3 stacked system memory to be used as the unified system memory for both CPU and GPU, and so getting rid of the slow and energy expensive off chip DDR memory. This has to be where these companies are heading long term isn't it???
So lets say in 2022 when 5nm is very mature (3nm should be here by then too) then AMD could build an APU with 16 CPU cores, 120CU and 32GB HBM3. I know this sounds crazily expensive to achieve right now but when you actually sit down and look at the costs it's honestly the better value route for performance.
The cost of separately putting a system like this together in 2022 would be roughly as follows:
CPU (16 Cores Zen 4) = $500
GPU (120CU RDNA 3.0 with 16GB GDDR6) = $1200
RAM (32GB DDR5) = $400
Total = $2100
So the first question is, would AMD be happy to sell this APU for less than $2100? I would say yes very happy considering the XSX chip is roughly half this chip and they sell that for probably less than ~$100 each to Microsoft! Now ok, that is in massive quantities and the HBM memory will add a lot to the costs but not too get it close to $2100 and so it would still be a huge margin product for anyone who makes it.
The XSX is only 360mm^2, moving to 5nm+ increases the density by 80% so even though I am suggesting doubling pretty much everything the HBM reduces the bus size coupled with 5nm it wouldn't be a crazily big chip, certainly no bigger than 600mm^2, which is big but still very doable. It would actually be around the same size and design as AMD's Fiji chip which had a launch price of just $649 back in 2015.
With densities and efficiencies afforded by the advanced 19 layer EUV process on TSMC's 5nm node plus Zen 4's power efficiencies plus RDNA 3.0 being 50% more power efficient than RDNA 2.0 which is 50% more efficient than RDNA 1.0, I truly believe this seemingly fanciful list of specifications for an APU is actually easily do-able if there is a will to make it.
Granted, clocks might have to be tamed a little to keep temperatures under control as transistor density will be very high but I would think the massive bandwidth and ultra low latencies of having HBM as the on die system memory would go a long way to making up for lower clocks.
Maybe the CU count won't be the most important thing to focus on in the future, maybe it will be all down to the number of accelerators they can include on a self-contained, purpose built, giant, higher performance APU with ultra low latency insanely wide bandwidth memory that will actually be the key differentiator allowing for things not possibly on a non-APU system.
I'm not saying this is a perfect fit for all use cases but it would amazingly powerful for a lot of gamers, workstations, programmers, high-res professional image editing, 3D rendering, etc, etc.
These types of chip would be perfect for something like the MS Surface equivalent of the Apple Mac Pro in 2022 .
Intel and AMD and currently locked in a fierce battle for CPU supremacy, Intel is also doing what it can to start a battle in the GPU space too and possibly Nvidia will join the APU fight if it does buy ARM but ultimately the victor will be the company that truly nails APUs at the majority of performance segments first.
For whatever reason we have yet to see a powerful APU come to the desktop, it's only low cost, low power stuff but even though AMD seems to be doing all the ground work to set this up maybe it will be Intel that brings something truly special first? Intel looks to be playing around with big.LITTLE CPU cores which lends itself to APU designs from a thermal management standpoint. Plus Intel are doing their utmost to build a decent scaleable graphics architecture with it's Xe range. But the biggest indicator of Intel's intentions is their work on Foveros which shows they understand the future needs all in one APUs with system memory on the die but again it's just down to which company beings a finished product to market first.
I guess it's just 'watch this space' for who does it first but this is certainly the future of computing, imo. What is very interesting is ARM based chips are way ahead of x86 when it comes to all in one chip design, just look at the likes of Fujitsu's A64FX, this is an incredible chip. So x86 has to be careful to not be caught napping. If Intel or AMD don't make a super high end APU soon then Apple will very quickly show what is possible using ARM or even their own design using the RISC V architecture to completely relinquish their dependence on everyone for their chips, especially if Nvidia buys ARM. Amazon are kind of making APUs, Huawei do, Google do, Nvidia too, ok all these are very different types of chips to what I am talking about above but what I'm saying is they all have the experience of designing very high performance, complex chips and with Windows already supporting ARM and emulators working pretty well now then a move away from x86 could happen very quickly if one of these massive players nails a super powerful APU with key accelerators for the PC market.
One thing is for sure, we have an amazing few years ahead of us.
Honestly, RT performance is 100% smoke and mirrors right now, and has been since Jensen yelled 10 Gigarays on stage. It could be anything. The output of whatever number of rays could be anything. This is not like FPS, but it has a very symbiotic relationship with it. Realistically what you want from your RT performance is one simple thing: look better while not dragging your FPS into the ground. Its the balancing trick early implentations failed so hard at.
Regardless, hats off to AMD for this design, it looks neat, it looks feature complete. And that's a rhyme.Console peasants won't see it. It sounds not nice, but its true. If you tell them its truly 4K, its truly so.
Inb4 the countless discussion on the subject on TPU, just you wait :)