Tuesday, March 21st 2023

Apple A17 Bionic SoC Performance Targets Could be Lowered
Apple's engineering team is rumored to be adjusting performance targets set for its next generation mobile SoC - the A17 Bionic - due to issues at the TSMC foundry. The cutting edge 3 nm process is proving difficult to handle, according to industry tipsters on Twitter. The leaks point to the A17 Bionic's overall performance goals being lowered by 20%, mainly due to the TSMC N3B node not meeting production targets. The factory is apparently lowering its yield and execution targets due to ongoing problems with FinFET limitations.
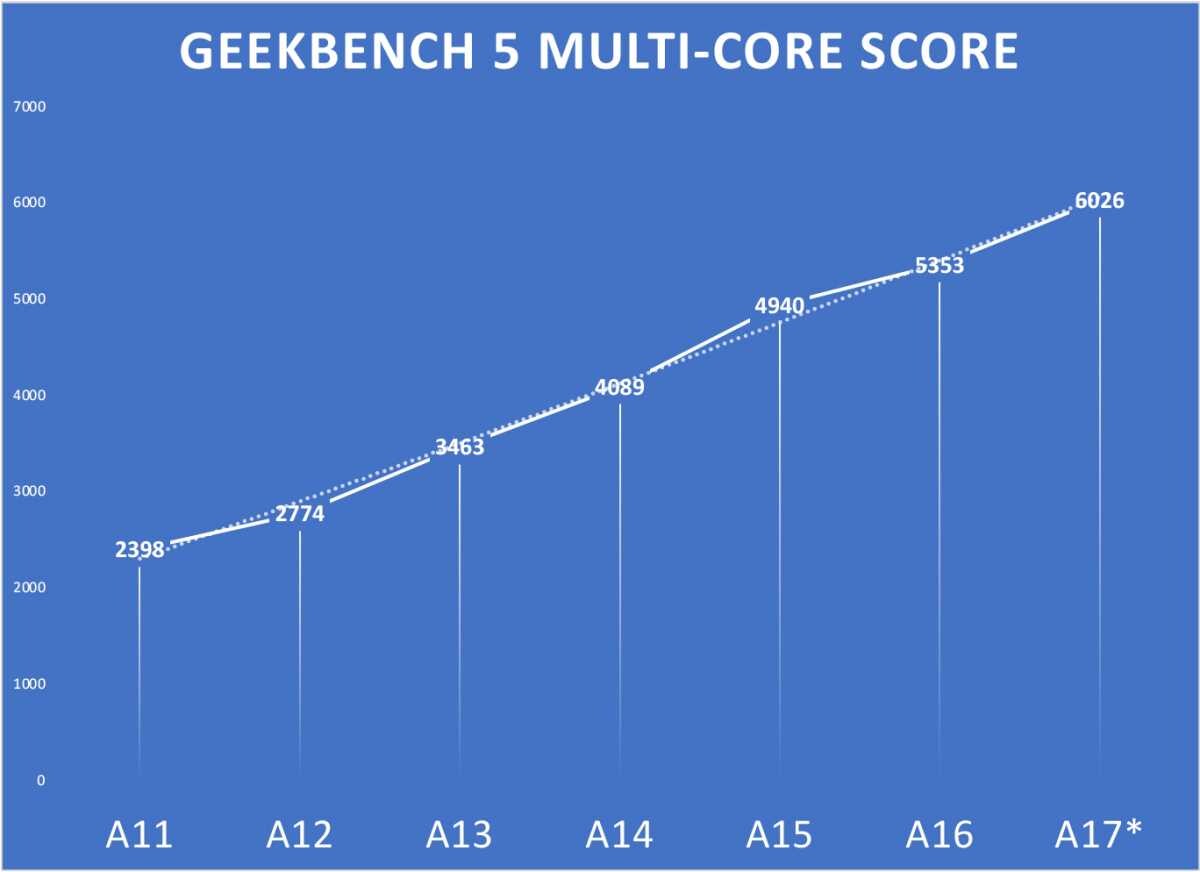
The leakers have recently revealed more up-to-date A17 Bionic's Geekbench 6 scores, with single thread performance at 3019, and multi-thread at 7860. Various publications have been hyping the mobile SoC's single thread performance as matching that of desktop CPUs from Intel and AMD, more specifically 13th-gen Core i7 and 'high-end' Ryzen models. Naturally the A17 Bionic cannot compete with these CPUs in terms of multi-thread performance.

 Apple has an excellent reputation for its chip designs, and a good portion of their customer base are not too concerned with hardware specifications, so the rumors of slightly lowered performance expectations for next's years flagship devices could be less of a headache for the engineering team. The current generation A16 Bionic outperforms Qualcomm's latest Snapdragon 8 Gen 2 in terms of pure processing power, and only lags slightly behind with its GPU's capabilities.
Apple has an excellent reputation for its chip designs, and a good portion of their customer base are not too concerned with hardware specifications, so the rumors of slightly lowered performance expectations for next's years flagship devices could be less of a headache for the engineering team. The current generation A16 Bionic outperforms Qualcomm's latest Snapdragon 8 Gen 2 in terms of pure processing power, and only lags slightly behind with its GPU's capabilities.



Sources:
MacWorld, Revegnus Twitter
The leakers have recently revealed more up-to-date A17 Bionic's Geekbench 6 scores, with single thread performance at 3019, and multi-thread at 7860. Various publications have been hyping the mobile SoC's single thread performance as matching that of desktop CPUs from Intel and AMD, more specifically 13th-gen Core i7 and 'high-end' Ryzen models. Naturally the A17 Bionic cannot compete with these CPUs in terms of multi-thread performance.






33 Comments on Apple A17 Bionic SoC Performance Targets Could be Lowered
Conversely, Apple is not accustomed to making large CPUs. The M1 Ultra is not suitable for video editing workstations due to its lack of PCIe expandability. Even Final Cut Pro X users were complained to Mac Studio and seriously considering switching to DaVinci Resolve.
I built the following x86 system (for linux) for memory hungry applications and the cost difference is stark compared to a Mac Studio with similar performance. even if a GPU was needed it would still be around $3000 with an RTX4070Ti. In terms of power efficiency, the 13900K and 7950X are also practical enough to be comparable to the M1 Ultra, even when reduced to PL2, which is equivalent to Eco mode. In fact, my system runs quietly even with air cooling.
$2000 ~ 13900K - 192 GB - 2TB SSD
$6200 ~ M1 Ultra - 128 GB - 2TB SSD
If the yield of N3B is low, M3 and M3 Max may come out later than expected.
I think the x86 camp will also strike back with the Lunar lake / Strix Point generation. Even in a relatively modest scenario, I think Arrow lake/Lunar lake will outperform M3 and achieve better power efficiency, and in an ambitious scenario, I think Lunar lake 2+8 or 1+4 can compete with A17 in both performance and efficiency, with a planned foray into smartphones.
Buying an SE and using it until 2gens later is the best deal I know of for a smartphone, and from a company whose business model isn’t data mining is nice.
But yeah, 500$ for 7 years is pretty good
Apple most certainly isn’t saintly, but when the alternative is literally Google, what more needs to be said.
None of this uses "accelerators". Y'all attach way too much to the Apple brand and your personal reaction to it.
//It's as if you missed all the charts in the article. Apple makes plenty of errors, but y'all critique them on the wildest things.
CPU perf / W cadence (via IPC or clocks) is one of the only undeniably hard-to-reproduce traits of Apple's CPU architects.
//
@Redwoodz: you think Apple doesn't design CPUs? And it's Arm's due? Just completely backwards. Apple uses Arm's ARMv8 ISA, just like AMD uses Intel's x86 ISA. Apple and AMD, even using someone else's ISA, actually do develop 100% in-house CPU microarchitectures.
//
Apple has just barely above average nT perf / W, but HWUB found Intel has dominant 1T perf / W. Intel & AMD simply have narrower designs; they'll never consume <10W at their sky-high 5+ GHz clocks.
In IPC, Apple is unmatched. The big problem is that Apple has just had basically zero progress for two generations now (A15, A16). Some might argue Apple always releases new CPUs, but so does Intel. AMD might take an 18 to 24 month break, but Intel won't.
//
Notebookcheck found the same: 1T perf/W is still dominant, though M2 is somewhat less efficient than M1. But still in a different zipcode than whatever AMD & Intel are draining their power in.
//
M2 was bitten by the same CPU ossification as A15; basically zero IPC uplift. However, M2 has a ~15% GPU perf uplift with an ~11% GPU perf/W uplift. The CPU side is disappointing in a vacuum, but I'm more disappointed that AMD & Intel can't replicate this yet in their latest designs (still waiting on Phoenix reviews…AMD, April is basically done, hurry up).
That is simply not true. In terms of cpu power a16 bionic is about 20 percent faster.
In terms of gpu power a16 bionic is 20 percent slower.
In terms of npu power we cant really know because of the lame tradition, apple pioneered (pun intended) to hide its theoretical performance numbers. But from what is available now on the web it seems a16 bionic also lags behind snapdragon 8 gen 2 in this regard.
Comparison between a16 and sd 8 gen 2 is the first fair comparison between android chips and apple silicon for a long time because they both use the same lithography. Overall they are both very capable chips at the same level of computing power and the differences in cpu or gpu are only design choices.
There is nothing particularly "magical" in the apple or quallcom "architecture". Engineers from both teams know their job and will perform about equally given the same substrate.
Now regarding the comparison between the apple a16( and upcoming a17) and Intel desktop processors, do we need to stress that it is invalid? It cant get more invalid than this. The latest Intel chips are made on a much inferior lithography and they compensate with higher power consumption for that. Intel's current lithography is for all intents and purposes about equivalent to TSMC's 7nm. It is not even close to TSMC's 5nm and it is lightyears behind even a bad implementation of a 3nm node by TSMC.
To be fair Intel's lithography is homemade while Apple and Quallcom just buy TSMC's enginnering prowess because they cant build anything themselves . And to be even more fair at the core level no-one would be able to boast and shout and gesture if it were not for ASML and maybe some other company that i dont know that provide the lithography machines. If it were not for the expertise of the dutch who keep the flag of the techinological progress you would not get any new cool phone apple and android fanboys.
You can have made comparisons for years now.
Snapdragon 8+ Gen1 = TSMC N5 class (May 2022)
Apple A15 = TSMC N5 class (Sept 2021)
or
Snapdragon 865 = TSMC N7 class (Dec 2019)
Apple A13 = TSMC N7 class (Sept 2019)
or
Snapdragon 855 = TSMC N7 class (Dec 2018)
Apple A12 = TSMC N7 class (Sept 2018)
//To be clear, Qualcomm relies purely on Arm's microarchitectures for all its current releases. NUVIA's IP in mobile is years away. Qualcomm's engineers haven't developed a fully-custom mobile CPU microarchitecture in almost decade (IIRC, the Snapdragon 820 in 2015). This should read, "nothing particularly magical about Apple's or Arm's microarchitectures."
//Ideally, we should compare Apple's M-series vs Intel's desktop CPUs. But, sure, as A & M use the same uArch, people extrapolate.
//
Intel's node exclusivity is by Intel's design and choice. Intel has used TSMC for decades, but Intel prefers internal foundries for IA (aka CPU compute) cores. It's like saying "this comparison is invalid because this car uses a custom in-house engine and that one was co-developed among three OEMs." Well, yeah: the first manufacturer picked custom.
Intel could have chosen TSMC years prior, too; Intel just never made the time nor humility to port. Virtually every other CPU firm in the world has used external fabs (Samsung a primary exception). Intel doesn't get handicaps because Intel made a bad decision. Intel's engineers & corporate make loved their pride too much, so they will live with their decisions now.
In the end, "Fantasy Nodes" (e.g., "If only AMD were on TSMC N5! If only Samsung were on TSMC N3! If only Intel were on TSMC N7 years ago!) is a fun game, but uArch + node are chosen years earlier.
//
But the comparisons need not include power. We can absolutely compare Apple vs Arm vs AMD vs Intel on IPC + peak performance + clock scaling + RAM bandwidth + cache latencies in thousands of applications. In IPC, Apple & Arm are significantly ahead of their x86 counterparts, for example.
To be clear, I absolutely recognise the importance of architecture. But I also recognise the effects of lithography, supporting RAM, hard disk, optimisation of software and so on. But when I see too much emphasis on one of them it puts me off. Depending on time period , you will see the company ahead in computation power touting the advantages of their architecture. It was once Intel, it is now Apple. This is only for hype and marketing purposes
I could take one by one the examples you mentioned, but this would derail the discussion out of its intended goal.
For example , it is clear, regarding qualcomm, that it managed to deliver something comparable to Apple not directly but after developing 2 architectures on TSMC's 5nm. But this is also true for Apple Intel and AMD. Often the best advantage of the new node is seen in a couple of years and not in the first attempt. So, Qualcomm lagging behind Apple with Snapdragomn 8 plus, gen 1 is not an argument.
Again, this is not my main point. I want to bring an example comparing an Apple chip and an Intel chip . Striving to compare chips operating within comparable power envelopes, within comparable lithographies and see if architecture is the beginning and the end of importance ( it is not) But this time we compare an Apple product with an Intel one.
So let's compare Intel 1265u and a12z bionic .
Lithographies at about the same density and performance. TSMC's 7nm against Intel's 10 nm
Power consumption rated at 15w for both.
Geekbench 5 scores for a12z 1100 and 4500.
Geekbech 5 scores for Intel core 1265u 1800 and 6500.
So, at the same power envelope and about equivalent lithography Apple lags behind by a considerable margin.Seemingly....
Same results you get for their embedded gpus.
So, is Intel's architecture so much better than Apple's. ? Probably not, because of potential more liberal power draw intervals. We will never
accurately know, because companies lately are secretive , not disclosing architectural details like mother Apple that showed the way.. So Intel is actually able to build power efficient chips at the same level of performance. As is Apple able to build power consuming monsters, like m1 max.
Given the right materials, a particular strategy(computation at low or high power) all chip designers can produce similar results.
But rarely companies, build chips from top to bottom. Lately , they are more incapable than in the past and resort to foundries to get their silicon baked. Not that they have ever been able to build the furnace , but at least they used to buy one and bake their chips. Now , they don't know or willing to bake them themselves, with the possible exception of Intel.