Monday, November 12th 2018

AMD "Zen 2" IPC 29 Percent Higher than "Zen"
AMD reportedly put out its IPC (instructions per clock) performance guidance for its upcoming "Zen 2" micro-architecture in a version of its Next Horizon investor meeting, and the numbers are staggering. The next-generation CPU architecture provides a massive 29 percent IPC uplift over the original "Zen" architecture. While not developed for the enterprise segment, the stopgap "Zen+" architecture brought about 3-5 percent IPC uplifts over "Zen" on the backs of faster on-die caches and improved Precision Boost algorithms. "Zen 2" is being developed for the 7 nm silicon fabrication process, and on the "Rome" MCM, is part of the 8-core chiplets that aren't subdivided into CCX (8 cores per CCX).
According to Expreview, AMD conducted DKERN + RSA test for integer and floating point units, to arrive at a performance index of 4.53, compared to 3.5 of first-generation Zen, which is a 29.4 percent IPC uplift (loosely interchangeable with single-core performance). "Zen 2" goes a step beyond "Zen+," with its designers turning their attention to critical components that contribute significantly toward IPC - the core's front-end, and the number-crunching machinery, FPU. The front-end of "Zen" and "Zen+" cores are believed to be refinements of previous-generation architectures such as "Excavator." Zen 2 gets a brand-new front-end that's better optimized to distribute and collect workloads between the various on-die components of the core. The number-crunching machinery gets bolstered by 256-bit FPUs, and generally wider execution pipelines and windows. These come together yielding the IPC uplift. "Zen 2" will get its first commercial outing with AMD's 2nd generation EPYC "Rome" 64-core enterprise processors.

Update Nov 14: AMD has issued the following statement regarding these claims.
Source:
Expreview
According to Expreview, AMD conducted DKERN + RSA test for integer and floating point units, to arrive at a performance index of 4.53, compared to 3.5 of first-generation Zen, which is a 29.4 percent IPC uplift (loosely interchangeable with single-core performance). "Zen 2" goes a step beyond "Zen+," with its designers turning their attention to critical components that contribute significantly toward IPC - the core's front-end, and the number-crunching machinery, FPU. The front-end of "Zen" and "Zen+" cores are believed to be refinements of previous-generation architectures such as "Excavator." Zen 2 gets a brand-new front-end that's better optimized to distribute and collect workloads between the various on-die components of the core. The number-crunching machinery gets bolstered by 256-bit FPUs, and generally wider execution pipelines and windows. These come together yielding the IPC uplift. "Zen 2" will get its first commercial outing with AMD's 2nd generation EPYC "Rome" 64-core enterprise processors.

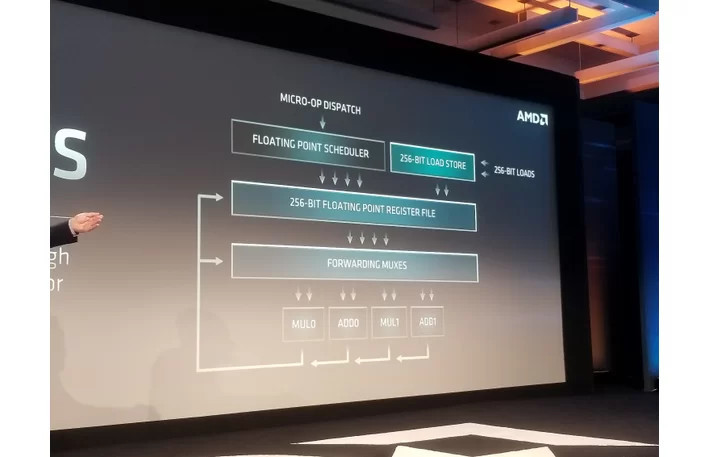
As we demonstrated at our Next Horizon event last week, our next-generation AMD EPYC server processor based on the new 'Zen 2' core delivers significant performance improvements as a result of both architectural advances and 7nm process technology. Some news media interpreted a 'Zen 2' comment in the press release footnotes to be a specific IPC uplift claim. The data in the footnote represented the performance improvement in a microbenchmark for a specific financial services workload which benefits from both integer and floating point performance improvements and is not intended to quantify the IPC increase a user should expect to see across a wide range of applications. We will provide additional details on 'Zen 2' IPC improvements, and more importantly how the combination of our next-generation architecture and advanced 7nm process technology deliver more performance per socket, when the products launch.
162 Comments on AMD "Zen 2" IPC 29 Percent Higher than "Zen"
-16c with high clocks would have a high TDP, the current motherboards would have been problems to support them.
-16c would have to be double the current value of the 2700x, and even then AMD would have a lower profit/cpu sold.
- 8c CPU is more than enough for gaming, even for future releases.
Would you buy a 3700x @ 16c at U$ 599~ ? Or would be better a 3700x with "just 8c", low latency, optimized for gaming at U$ 349~399 ?
Valantar with the entire I/O & MC off the die it opens up a world of possibilities with Zen, having said that I'll go back again to the point I made in other threads. The 8 core CCX makes sense for servers & perhaps HEDT, however when it comes to APU (mainly notebooks) I don't see a market for 8 cores there. I also don't see AMD selling an APU with 6/4 cores disabled, even if it is high end desktop/notebooks.
The point I'm making is that either AMD makes two CCX, one with 8 cores & the other with 4, or they'll probably go with the same 4 core CCX. The image I posted is probably misconstrued, I also don't know for certain if the link shown inside the die is IF or just a logical connection (via L3?) between 2 CCX.
There is no way they will hit 20-29%. That is just wishful thinking on AMD's part, most likely in specific scenarios.
Of course, I'd love to e proved wrong here.
How I envision AMD's Zen2 roadmap:
Ryzen Mobile:
15-25W: 4-core chiplet + small I/O die (<16 lanes PCIe, DC memory, 1-2 IF links), either integrated GPU on the chiplet or separate iGPU chiplet
35-65W: 8-core chiplet + small I/O die (<16 lanes PCIe, DC memory, 1-2 IF links), separate iGPU chiplet or no iGPU (unlikely, iGPU useful for power savings)
Ryzen Desktop:
Low-end: 4-core chiplet + medium I/O die (< 32 lanes PCIe, DC memory, 2 IF links), possible iGPU (either on-chiplet or separate)
Mid-range: 8-core chiplet + medium I/O die (< 32 lanes PCIe, DC memory, 2 IF links), possible iGPU on specialized SKUs
High-end: 2x 8-core chiplet + medium I/O die (< 32 lanes PCIe, DC memory, 2 IF links)
Threadripper:
(possible "entry TR3": 2x 8-core chiplet + large I/O die (64 lanes PCIe, QC memory, 4 IF links), though this would partially compete with high-end Ryzen just with more RAM B/W and PCIe and likely only have a single 16-core SKU, making it unlikely to exist)
Main: 4x 8-core chiplet + large I/O die (64 lanes PCIe, QC memory, 4 IF links)
EPYC:
Small: 4x 8-core chiplet + XL I/O die (128 lanes PCIe, 8C memory, 8 IF links)
Large: 8x 8-core chiplet + XL I/O die (128 lanes PCIe, 8C memory, 8 IF links)
Uncertiainty:
-Mobile might go with an on-chiplet iGPU and only one IF link on the I/O die, but this would mean no iGPU on >4-core mobile SKUs (unless they make a third chiplet design), while Intel already has 6-cores with iGPUs. As such, I'm leaning towards 2 IF links and a separate iGPU chiplet for ease of scaling, even if the I/O die will be slightly bigger and IF power draw will increase.
Laying out the roadmap like this has a few benefits:
-Only two chiplet designs across all markets.
-Scaling happens through I/O dice, which are made on an older process, are much simpler than CPUs, and should thus be both quick and cheap to make various versions of.
-A separate iGPU chiplet connected through IF makes mobile SKUs easier to design, and the GPU die might be used in dGPUs also.
-Separate iGPU chiplets allow for multiple iGPU sizes - allowing more performance on the high end, or less power draw on the low end.
-Allows for up to 8-core chips with iGPUs in both mobile and desktop.
Of course, this is all pulled straight out of my rear end. Still, one is allowed to dream, no?Well, they claim to have measured a 29.4% increase. That's not wishful thinking at least. But as I pointed out in a previous post:
I'll wait for third party benchmarks. AMD has made way too many *technically true claims over the years.
*Technically true in one specific workload, overall the performance boost was less then half what AMD claimed, but it was true in one workload, so technically they didnt lie.
Serving Mainstream, HEDT, and Server customers from a single die integrated into multiple packages, is one of the main reasons AMD are in such good shape right now - Intel has to produce their Mainstream, LCC, HCC, and XCC dies and then bin and disable cores on all 4 of them for each market segment. AMD only has to produce and bin one die, to throw onto a variety of packages at *every level* of their product stack.
It's not even worth producing a second die unless the move would bring in not only more profit, but enough extra profit to completely cover the cost of tooling up for that. Bear in mind here that I mean something very specific:
If AMD spends 1bn to produce a second die, and rakes in 1.5bn extra profit over last year, that doesn't necessarily mean tooling up for the extra die was worth it. What if their profits still would have gone up by 1bn anyway, using a single die in production? If that were the case, tooling up just cost AMD a cool $1,000,000,000 in order to make $500,000,000. Sure, they might have gained a bit more marketshare, but not only did it lose them money, it also ended up making their product design procedures more complex and caused additional overheads right the way up through every level of the company, keeping track of the two independent pieces of silicon. It also probably means having further stratification in motherboards and chipsets, whereas right now AMD are very flexible in what they can do to bring these packages to older chipsets or avoid bringing in new ones.
Edit: Not to mention, that using a single, much higher capability die, has other benefits - Like for example being able to provide customers with a *much* longer support period for upgrades - something that has already won them sales with their "AM4 until 2020" approach bringing in consumers who are sick of Intel's socket and chipset-hopping.
Or simply being able to unlock CCXs on new products as and when the market demands that - After all, why would you intentionally design a product that reduces your ability to respond to competition, when your competition is Intel, who you *know* are scrambling to use their higher R&D budget to smack you down again before you get too far ahead?
The NH-D15 didn't exist. There were no AIOs of any kind, and that's why back then, we all struggled to cool Prescott Cores and first Gen i7s.
For example, The i7 975 was a 130W part. The fastest Pentium 4 chips were officially 115W. Intel's Datasheets of that time don't specify how TDP was calculated, but if we assume that they were doing what they do now, which is quote TDP at base clocks under a "close to worst case" workload, then we're probably in good shape.
The i7-975 then, had a 3,333MHz base clock, a 3.467 All-Core boost, and a 3.6GHz single core boost. Not a lot of boost happening here, only an extra 133MHz on all cores. You'd expect no real increase in temperatures under your cooler from such a mild overclock, unless you were OC'ing something like an old P3, so we can probably assume that means the Intel TDP from then, if measured according to today's standards, was probably pretty close to "correct" - You could expect your i7 975 to stick pretty close to that 130W TDP figure in a real world scenario. And this was legitimately a hard to cool chip! Even the best air coolers sometimes struggled.
Compare that to the 9900K, which is breaking 150W power consumption all over the internet, and you suddenly realise - The only reason these chips are surviving in the wild is because:
1 - Intel's current Arch will maintain it's maximum clocks way up into the 90+ Celsius range
2 - People are putting them under NH-D15s - and even then we're seeing temperature numbers that, back in the P4 days, would have been considered "Uncomfortable" and "dangerous".
The 9900K is, as far as I can tell, simply the most power hungry and hard to cool processor that Intel has ever released on a mainstream platform. It runs at the *ragged edge* of acceptability. You can't just brush this sort of thing off with "The market has seen 95W chips before". That's not what the 9900K actually is. It's something much, much more obscene.
Picked the wrong quote, was meant to quote @WikiFM …Smartcom
That said, there's no denying what Intel has now is redesign trying to fit more tricks into the current process node which should be long behind us. Thus, it's an architecture stretched past its intended lifetime.
That's why actual Performance is usually by default measured using the figure of the actually absolute and fixed unit FLOPS (Floating Point Operations Per Second) or MIPS (Million Instructions per Second) – hence the performance of instructions per (clock-) cycle while performing a processing of a equally pre-defined kind of instruction (in this case, floating-point numbers).
Smartcom
But these chips and this silicon aren't designed to be 3.6GHz parts in daily use. They are ~4.7GHz parts that Intel reduced the base clocks on, in order to be able to claim a 95W TDP. If you had the choice between running a 7700K and a 9900K at base clocks, the 7700K would actually get you the better gaming performance in most games. Would you say that's Intel's intention? To create a market where a CPU 2 generations old, with half the cores, outperforms their current flagship in exactly the task Intel advertise the 9900K to perform?
Or would you say that actually, Intel has transitioned from using boost clock as "This is extra performance if you can cool it", to using boost clock as the figure expected to sell the CPU, and therefore the figure most users expect to see in use?
You can clearly see this in the progression of the flagships, each generation.
6700K - 4.0GHz Base, 4 Cores, 95W TDP
7700K - 4.2GHz Base, 4 Cores, 95W TDP
8700K - 3.7GHz Base, 6 Cores, 95W TDP
9900K - 3.6GHz Base, 8 Cores, 95W TDP.
Oh well would you look at that - As soon as Intel started adding cores, they dropped the base clocks dramatically in order to keep their "95W TDP at base clocks" claim technically true. But look at the all core boost clocks:
4.0GHz, 4.4GHz, 4.3GHz, 4.7GHz
They dipped by 100MHz on the 8700K, to prevent a problem similar to the 7700K, which was known to spike in temperature even under adequate cooling, only to come back up on the 9900K, but this time with Solder TIM to prevent that from happening.
Single core is the same story - 4.2, 4.5, 4.7, 5.0. A constant increase in clockspeed each generation.
Like I said - Boost is no longer a boost. Boost has become the expected performance standard of Intel chips. Once you judge the chips on that basis, the 9900K reveals itself to be a power hungry monster that makes the hottest Prescott P4 chips look mild in comparison.
A 29% IPC uplift would certainly be welcome, but keep in mind this is about twice the accumulated improvements from Sandy Bridge -> Skylake. I wonder how this thread would turn out if someone claimed Ice Lake would offer 29% IPC gains?:rolleyes:
Let's not have another Vega Victory Dance™. We need to clam down this extreme hype and be realistic. Zen 2 is an evolved Zen, it will probably do tweaks and small improvements across the design, but it will not be a major improvement over Zen.
ir.amd.com/news-releases/news-release-details/amd-takes-high-performance-datacenter-computing-next-horizon
If the (extra) power savings materialize for ULP & ULV products then it makes sense to deploy a 4 core CCX over there, however an 8 core CCX will have better latencies & probably higher clocks as well.
My 6700K has no trouble downclocking to save power when it's not necessary. The 3rd Gen i5 I'm typing this on has no trouble with that either. The Pentium 4 660 had it, I can find from a cursory google. In fact, support for the power-saving tech was originally mainly difficult not due to the platforms, but because of a lack of operating system support for the feature. "Smarter" power saving algorithms should have nothing to do with "Turbo boost" technology.
We disagree in that you think it is reasonable for Intel to consider a 9900K as "working according to spec" at 3.6GHz and "Overclocked" at 4.7GHz, when clearly these products are actually designed to run at higher clocks, and are expected to by consumers, and *will run* at higher clocks, it's just that it is only achievable at a *much* higher TDP than intel claims their CPU actually has.
They can't have their cake and eat it - Either the 9900K is "The world's fastest gaming CPU (At 150W TDP)", or it is a 95W part (but isn't anywhere close to being the fastest gaming CPU at that TDP).
Intel should not be allowed to advertise this product as both of these mutually exclusive things.