Monday, December 28th 2020

Intel Core i7-11700K "Rocket Lake" CPU Outperforms AMD Ryzen 9 5950X in Single-Core Tests
Intel's Rocket Lake-S platform is scheduled to arrive at the beginning of the following year, which is just a few days away. The Rocket Lake lineup of processors is going to be Intel's 11th generation of Core desktop CPUs and the platform is expected to make a debut with Intel's newest Cypress Cove core design. Thanks to the Geekbench 5 submission, we have the latest information about the performance of the upcoming Intel Core i7-11700K 8C/16T processor. Based on the Cypress Cove core, the CPU is allegedly bringing a double-digit IPC increase, according to Intel.
In the single-core result, the CPU has managed to score 1807 points, while the multi-core score is 10673 points. The CPU ran at the base clock of 3.6 GHz, while the boost frequency is fixed at 5.0 GHz. Compared to the previous, 10th generation, Intel Core i7-10700K which scores 1349 single-core score and 8973 points multi-core score, the Rocket Lake CPU has managed to put out 34% higher single-core and 19% higher multi-core score. When it comes to the comparison to AMD offerings, the highest-end Ryzen 9 5950X is about 7.5% slower in single-core result, and of course much faster in multi-core result thanks to double the number of cores.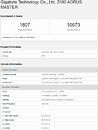

Sources:
Leakbench, via VideoCardz
In the single-core result, the CPU has managed to score 1807 points, while the multi-core score is 10673 points. The CPU ran at the base clock of 3.6 GHz, while the boost frequency is fixed at 5.0 GHz. Compared to the previous, 10th generation, Intel Core i7-10700K which scores 1349 single-core score and 8973 points multi-core score, the Rocket Lake CPU has managed to put out 34% higher single-core and 19% higher multi-core score. When it comes to the comparison to AMD offerings, the highest-end Ryzen 9 5950X is about 7.5% slower in single-core result, and of course much faster in multi-core result thanks to double the number of cores.


114 Comments on Intel Core i7-11700K "Rocket Lake" CPU Outperforms AMD Ryzen 9 5950X in Single-Core Tests
By the way that website is one of the best, but for some items they don’t ship outside UK
Plenty of intel CPU but few others in stock and favourite ones like 5900x aren't about anymore.
Oh to be rich.
The Xilinx purchase probably helps: since it will give them a stable source of revenue, allowing them to play a bit more aggressive in the months and years ahead.
Apple's obsession with a ultra wide front end (and ultra wide everything really) seems to be rather wasteful, there is no obvious reason why that's actually required at the moment, I bet you everything that with half the decode stage the performance regression would be marginal.
I mean most of the performance that's worth extracting through ILP sits in loops and those don't put pressure on the decode stage because you'll keep hitting the instruction cache anyway which is colossal on something like M1. Actually the more I think about it the more absurd Apple's design choices appear to me.
The M1 can fit 192kB into its L1 i-cache, which performs a bit faster than the Intel/AMD uOp cache thanks to 8-way decoding. Intel / AMD only have 48kB i-L1 (for Rocket Lake) or 32kB i-L1 (AMD Zen 3), and smaller than that for its uOp cache.
-------
EDIT: I should say "Seems to have an advantage". Its not very clear if Apple's big decoder is a good strategy yet IMO. But its interesting, and worth keeping an eye on. Especially because it seems like an area that may be harder to implement into x86.
What I am also saying it that I haven't actually seen any evidence that such a wide decoder is actually worth it. Wide decode means a lot of delay in the circuitry which means poor clock speed scaling.
What happens when 8K or whatever is next becomes a thing? Apple products become obsolete and cheap, which is why a used Ipad Pros get sold for dirt cheap. 2-3 year old one is now $270 VS the initial price of $1k. Almost as bad as other ASIC hardware like GPU's, but 1K of X86 hardware will retain its value longer, and you can upgrade RAM and GPU's, increase storage and it just works.
Apple has a superior decoder: just 8-uops/tick no matter what. Its the "more expensive transistor budget" compared to a uop cache. Apple can achieve 8uops/tick across the entire 192kB L1 instruction cache, while Intel Skylake / AMD Zen3 can only achieve 4-uops/tick across a 48kB L1 cache (Skylake) / 32kB L1 (Zen3) cache, and a 6-uop/tick across a smaller region inside of the uOp cache.
technosports.co.in/2020/12/28/intel-b560-chipset-motherboards-will-support-overclocking-core-i9-11900k-blows-away-ryzen-7-5800x/
But seriously I'm starting to really feel, between this and AMD's new offerings, the upgrade itch. Just need a little patience for all these new goodies to become obtainable.
Anyway, who knows how true this is... but it's a good sign so far. Wondering what the power draw will be (more than AMD I'd guess), but if IPC is back up there along with clocks and they keep the more reasonable pricing... it sounds like a solid option in the market to me...
Is Geekbench a "Realworld benchmark" now ? :)