Thursday, September 3rd 2020

NVIDIA RTX IO Detailed: GPU-assisted Storage Stack Here to Stay Until CPU Core-counts Rise
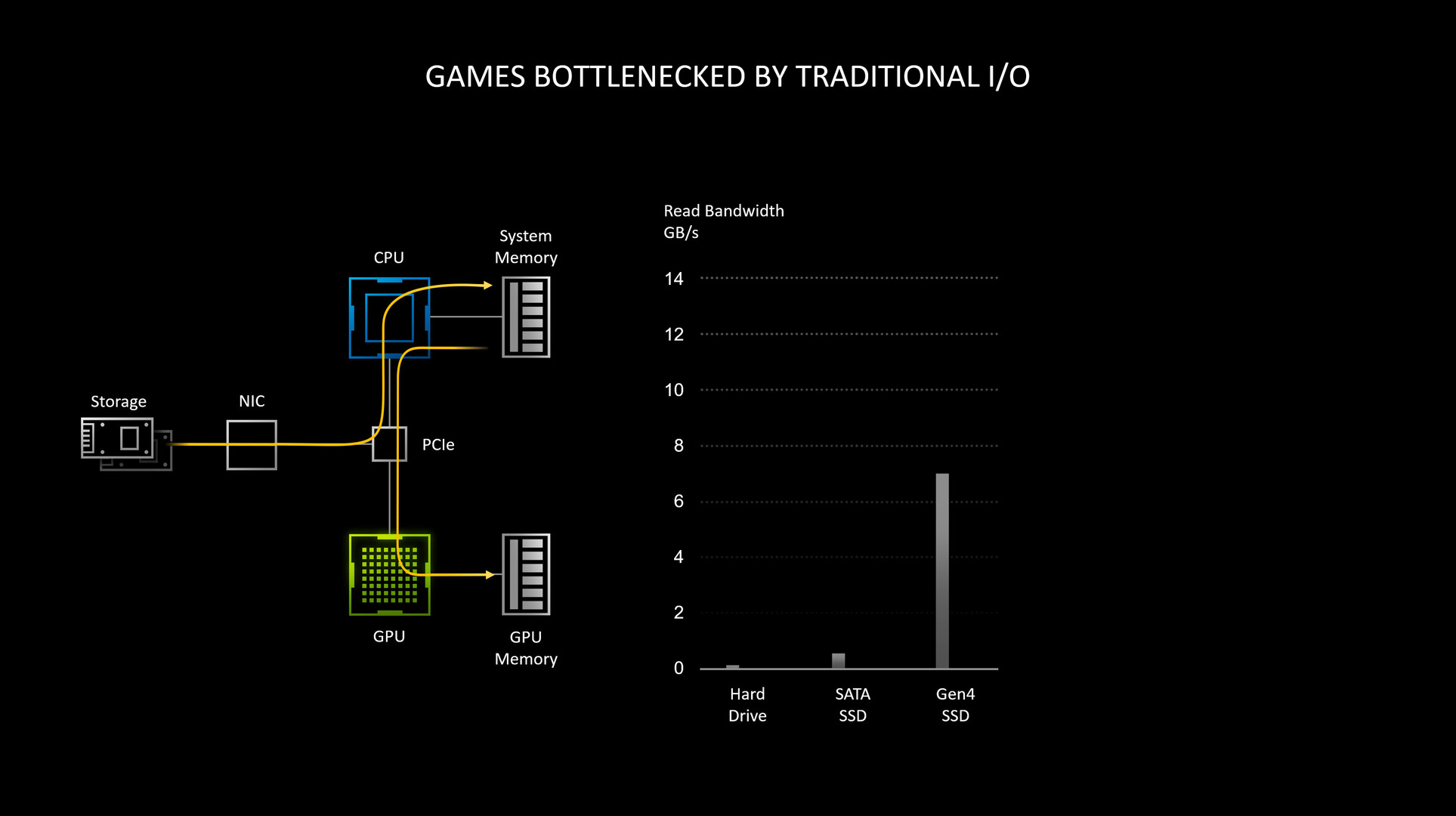
NVIDIA at its GeForce "Ampere" launch event announced the RTX IO technology. Storage is the weakest link in a modern computer, from a performance standpoint, and SSDs have had a transformational impact. With modern SSDs leveraging PCIe, consumer storage speeds are now bound to grow with each new PCIe generation doubling per-lane IO bandwidth. PCI-Express Gen 4 enables 64 Gbps bandwidth per direction on M.2 NVMe SSDs, AMD has already implemented it across its Ryzen desktop platform, Intel has it on its latest mobile platforms, and is expected to bring it to its desktop platform with "Rocket Lake." While more storage bandwidth is always welcome, the storage processing stack (the task of processing ones and zeroes to the physical layer), is still handled by the CPU. With rise in storage bandwidth, the IO load on the CPU rises proportionally, to a point where it can begin to impact performance. Microsoft sought to address this emerging challenge with the DirectStorage API, but NVIDIA wants to build on this.
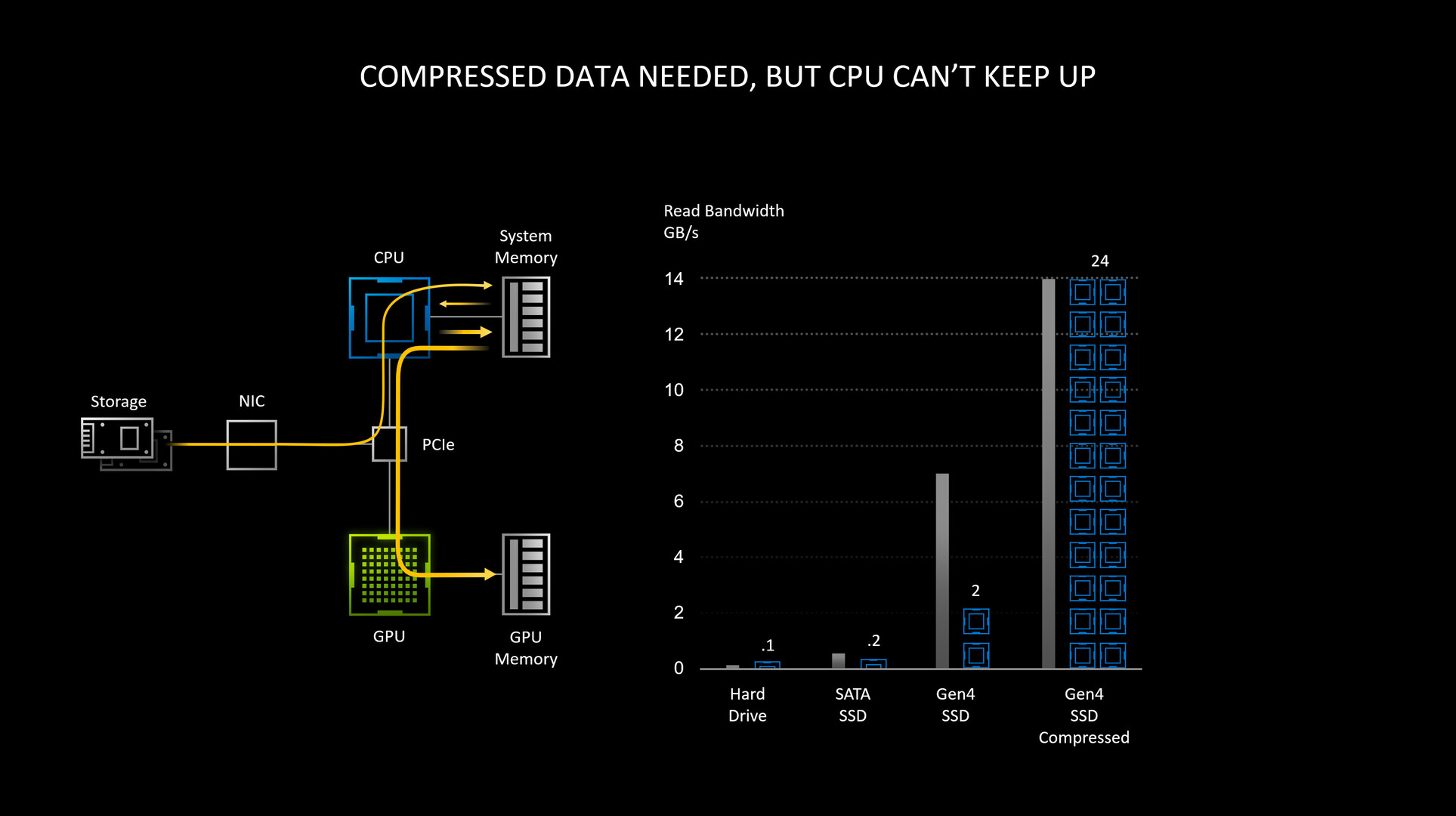
According to tests by NVIDIA, reading uncompressed data from an SSD at 7 GB/s (typical max sequential read speeds of client-segment PCIe Gen 4 M.2 NVMe SSDs), requires the full utilization of two CPU cores. The OS typically spreads this workload across all available CPU cores/threads on a modern multi-core CPU. Things change dramatically when compressed data (such as game resources) are being read, in a gaming scenario, with a high number of IO requests. Modern AAA games have hundreds of thousands of individual resources crammed into compressed resource-pack files.

 Although at a disk IO-level, ones and zeroes are still being moved at up to 7 GB/s, the de-compressed data stream at the CPU-level can be as high as 14 GB/s (best case compression). Add to this, each IO request comes with its own overhead - a set of instructions for the CPU to fetch x piece of resource from y file, and deliver to z buffer, along with instructions to de-compress or decrypt the resource. This could take an enormous amount of CPU muscle at a high IO throughput scale, and NVIDIA pegs the number of CPU cores required as high as 24. As we explained earlier, DirectStorage enables a path for devices to directly process the storage stack to access the resources they need. The API by Microsoft was originally developed for the Xbox Series X, but is making its debut on the PC platform.
Although at a disk IO-level, ones and zeroes are still being moved at up to 7 GB/s, the de-compressed data stream at the CPU-level can be as high as 14 GB/s (best case compression). Add to this, each IO request comes with its own overhead - a set of instructions for the CPU to fetch x piece of resource from y file, and deliver to z buffer, along with instructions to de-compress or decrypt the resource. This could take an enormous amount of CPU muscle at a high IO throughput scale, and NVIDIA pegs the number of CPU cores required as high as 24. As we explained earlier, DirectStorage enables a path for devices to directly process the storage stack to access the resources they need. The API by Microsoft was originally developed for the Xbox Series X, but is making its debut on the PC platform.
NVIDIA RTX IO is a concentric outer layer of DirectStorage, which is optimized further for gaming, and NVIDIA's GPU architecture. RTX IO brings to the table GPU-accelerated lossless data decompression, which means data remains compressed and bunched up with fewer IO headers, as it's being moved from the disk to the GPU, leveraging DirectStorage. NVIDIA claims that this improves IO performance by a factor of 2. NVIDIA further claims that GeForce RTX GPUs, thanks to their high CUDA core counts, are capable of offloading "dozens" of CPU cores, driving decompression performance beyond even what compressed data loads PCIe Gen 4 SSDs can throw at them.
There is, however, a tiny wrinkle. Games need to be optimized for DirectStorage. Since the API has already been deployed on Xbox since the Xbox Series X, most AAA games for Xbox that have PC versions, already have some awareness of the tech, however, the PC versions will need to be patched to use the tech. Games will further need NVIDIA RTX IO awareness, and NVIDIA needs to add support on a per-game basis via GeForce driver updates. NVIDIA didn't detail which GPUs will support the tech, but given its wording, and the use of "RTX" in the branding of the feature, NVIDIA could release the feature to RTX 20-series "Turing" and RTX 30-series "Ampere." The GTX 16-series probably misses out as what NVIDIA hopes to accomplish with RTX IO is probably too heavy on the 16-series, and this may have purely been a performance-impact based decision for NVIDIA.
According to tests by NVIDIA, reading uncompressed data from an SSD at 7 GB/s (typical max sequential read speeds of client-segment PCIe Gen 4 M.2 NVMe SSDs), requires the full utilization of two CPU cores. The OS typically spreads this workload across all available CPU cores/threads on a modern multi-core CPU. Things change dramatically when compressed data (such as game resources) are being read, in a gaming scenario, with a high number of IO requests. Modern AAA games have hundreds of thousands of individual resources crammed into compressed resource-pack files.
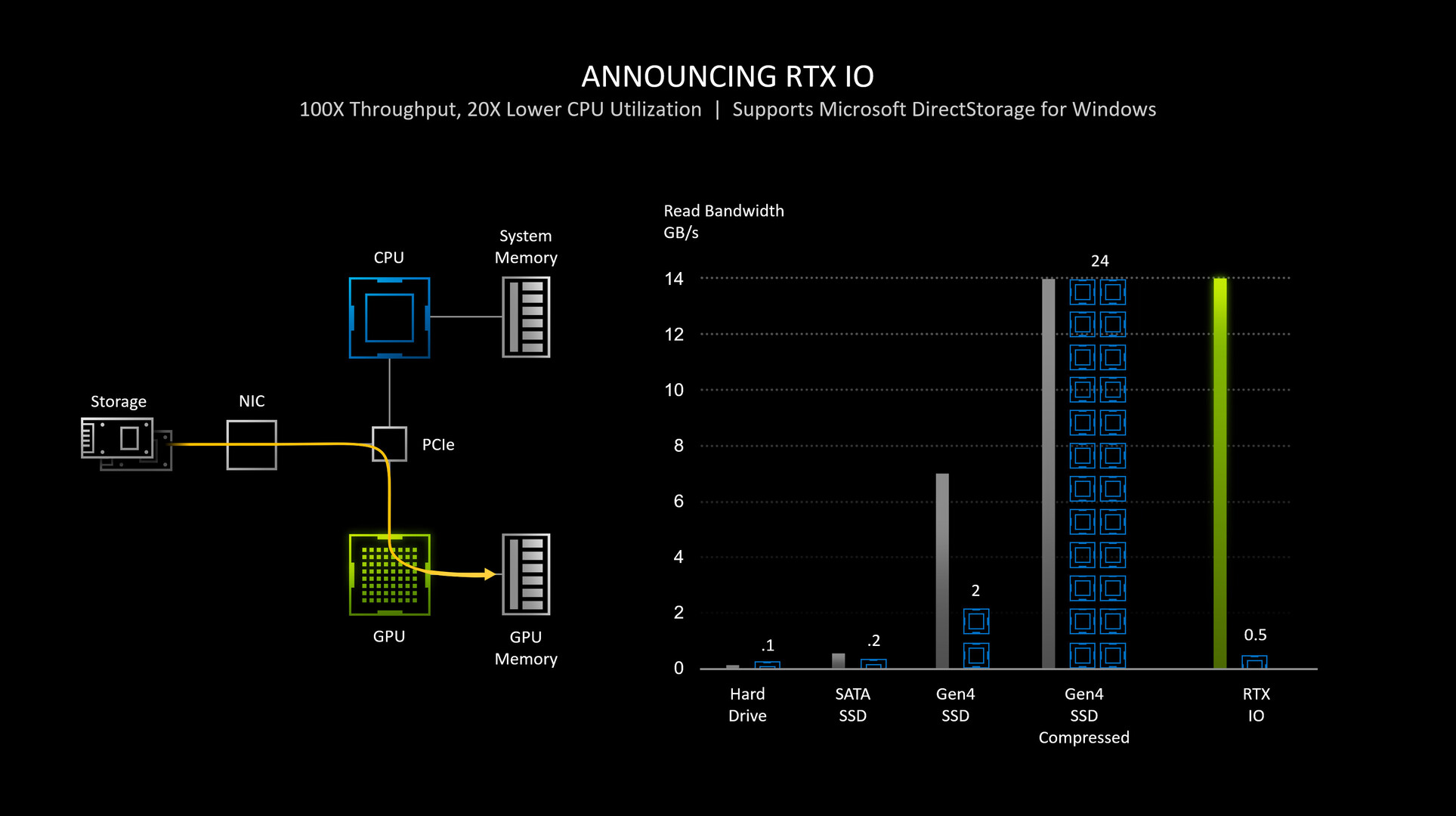
NVIDIA RTX IO is a concentric outer layer of DirectStorage, which is optimized further for gaming, and NVIDIA's GPU architecture. RTX IO brings to the table GPU-accelerated lossless data decompression, which means data remains compressed and bunched up with fewer IO headers, as it's being moved from the disk to the GPU, leveraging DirectStorage. NVIDIA claims that this improves IO performance by a factor of 2. NVIDIA further claims that GeForce RTX GPUs, thanks to their high CUDA core counts, are capable of offloading "dozens" of CPU cores, driving decompression performance beyond even what compressed data loads PCIe Gen 4 SSDs can throw at them.
There is, however, a tiny wrinkle. Games need to be optimized for DirectStorage. Since the API has already been deployed on Xbox since the Xbox Series X, most AAA games for Xbox that have PC versions, already have some awareness of the tech, however, the PC versions will need to be patched to use the tech. Games will further need NVIDIA RTX IO awareness, and NVIDIA needs to add support on a per-game basis via GeForce driver updates. NVIDIA didn't detail which GPUs will support the tech, but given its wording, and the use of "RTX" in the branding of the feature, NVIDIA could release the feature to RTX 20-series "Turing" and RTX 30-series "Ampere." The GTX 16-series probably misses out as what NVIDIA hopes to accomplish with RTX IO is probably too heavy on the 16-series, and this may have purely been a performance-impact based decision for NVIDIA.
52 Comments on NVIDIA RTX IO Detailed: GPU-assisted Storage Stack Here to Stay Until CPU Core-counts Rise
www.nvidia.com/en-us/geforce/news/rtx-io-gpu-accelerated-storage-technology/
As for RT, as I said - I believe nothing until I see it. Right now, I think NVIDIA will pressure benchmarking sites to include RT titles in benchmark suite.
As for looking terrible, what if it is? Should we hide those results? I think not, publish them and publish screenshots/videos and see is it worth investing +700g in 3090 over 3080 or whatever else... Buyers should decide, based on true input - quality/quantity included.
As for the rest of that part: that's a critique completely unrelated to this thread, Ampere, and any new GPU in general. It's a critique of potential shortcomings of how most sites do GPU and CPU testing. And it is likely valid to some degree, but ... irrelevant here. I agree that it would be nice to see tests run on lower end hardware too, but that would double the workload on already overworked and underpaid reviewers, so it's not going to happen, sadly. At least not until people start paying for their content.
Nvidia won't have to pressure anyone to include RT titles in their benchmark suites. Any professional reviewer will add a couple of titles for it, as is done with all new major features, APIs, etc. That's the point of having a diverse lineup of games, after all. And any site only including RT-on testing would either need to present a compelling argument for this, or I would ignore them as that would be a clear sign of poor methodology on their part. That has nothing to do with Nvidia.
And I never commented on your opinions of how current RT looks, so I have no idea who you're responding to there.
If it was a fixed function block, why would Turing be able to do it? Its not like Huang would have a new hardware function in Turing and forgot to brag about it for two years.
Nvidia already have compression/decompression with their GPU since Pascal to improve VRAM bandwidth
www.anandtech.com/show/10325/the-nvidia-geforce-gtx-1080-and-1070-founders-edition-review/8
I do wonder if that special workstation GPU of AMD's, that allowed installation of an NVMe as a large cache drive, also helped that concept along.
Its all about Disk i/o and decompressing assets.
I said what I think of supposed GPU-accelerated storage - I'll believe it when I see it. NVIDIA put a lot of dubious claims lately - I actually know quite a bit about ray-tracing and know they are misrepresenting what they do, but they also ray-trace *sound* (sic) and whatnot - now they accelerate PCIe4 M.2. Right. I need to see real-life proof that it's happening and what are the gains.
Basically with the new API, an NVMe drive can easily saturate its max bandwidth.
Pretty much all modern NVMe drive can handle >300 000 IOPs, at 64K blocks size that >19.2GB/s of bandwidth
PCIe Gen 4 x4 max bandwidth is 7.8GB/s.
Now when you compress/decompress the data stream, the effective bandwidth is 14GB/s as noted in Nvidia slide. Which is even higher throughput than using RAMDISK on Dual Channel DDR4.
I guess another option to increase throughput is using 2 PCIe 4.0 x4 NVMe in RAID 0. Either way you have plenty of option to take advantage of MS DirectStorage API: RAID 0, high core count CPU or a Nvidia GPU.
Let say you have a link that can send 10 GB/s. You want to send 2 GB uncompress or 1 GB compress. The first one will take at least 200 ms where the second one would take 100 ms.
This is just for pure data transfer but you can see how it can reduce latency on large transfers
Also, these days the major energy cost come from moving the data around and not from doing the calculation itself. If you can move the data in a compressed state, you can save power there.
But what I would like to know is can we just uncompress just before using it and continue to save on bandwidth and storage while it sit in GPU memory? Just in time decompression!
That do not seem to do that there but I think it would be the thing to do as soon as we can have decompression engine fast enough to handle the load.I think the future might be interesting. If AMD want to be the leader on PC, they might bring to PC OMI (Open memory interface) where the memory or storage is attached to the CPU via a super fast serial bus (Using way less pin and die space than modern memory technology). The actual memory controller would be shifted directly on the memory stick. The CPU would become memory agnostics. You could upgrade your CPU or memory independly. Storage (like optane) could also be attach via this.
The pin count is much smaller than with modern memory so you can have way more channel if required.
This is based on the OpenCAPI protocol. OpenCAPI itself would be used to attach any kind of accelerator. The chiplet architecture from AMD would probably make it easy for them to switch to these kinds or architecture and it's probably the future.
These are open standard pushed by IBM but i would see AMD using them or pushing their own standard in the future that have a similar goal. With these standard, the GPU could connect directly to the Memory controler and vice versa.
AMD could sell a lot of those types of devices outside of gaming as well it's a device that is desirable in today's society in other area's ML, data centers, ect...could have the microSD slot be PCIe based and slot it into a PCIe x1 slot as well doubt it would add much extra to the cost plus it's a good way to draw power for all those things I would think 75w would be actually overkill to power those things and probably closer to like what 10w to 25w!!? About the only thing that would draw much power would be the CPU and 2-4c CPU isn't gonna draw crap for power these days could just use a mobile chip great way for AMD to bin those further in fact kill 2 birds with one stone. Like mentioned the compression saves a lot of bandwidth/latency and part of VRAM usage is old data that's still stuck in usage because of bandwidth and latency constraints getting in the way which if you can speed those things up you obviously stream in and out the data more effectively and quickly at any given moment. Just having that extra capacity space to send the data to and fetch back quickly would be big with HBCC. It would be interesting if it reduced latency enough to pretty much eliminate most of the CF/SLI micro stutter negatives as well. What you mention sound cool, but I'm really unsure about the cost aspect on that. I think what I mention could be done at good entry price point and of course AMD could improve them gradually yearly or every other year. You might actually speed up your own GPU with one and not have to buy a whole god damn new card in the process.
To me this is kind of what AMD should do with it's GPU's integrate just a fraction of this onto a GPU and make future GPU's compatible with it so any ugprade is compatible with it and help do some mGPU assigning the newer quicker card to cache accelerate/compress/decompress/offload possibly a touch on the fly post process while matching the other cards performance capabilities simply uses excess CPU/GPU resources for all the other improvement aspects. Really provided the two cards aren't too far apart in age and specs I'd think it would work alright. In cases were there are more glaring gaps certain features could just be enabled/disabled in terms of what it accelerates be it rendering, storage, compression/decompression perhaps it's older and it just handles the cache and compression on one card and the newer card handles all the other stuff. I just can't see how it could be a bad thing for AMD to do they can use it to help bin mobile chips better which is more lucrative add a selling feature to it's GPU's and diversify into another area entirely in storage acceleration it could even be used for path tracing storage on either the CPU cache or the SSD. It free's up overhead to the rest of the system as well the OS the CPU the memory and the storage become less strained from the offloading impact of it.
The point of this is that it bypasses the CPU, it had to go all into the CPU, RAM, and circuitry travel distance, a whole deoutor before it went to the GPU, now all of that is bypassed.
Seriously, try to be less patronizing... Especially when making uncalled-for replies to people who know much more about the subject than you do...
I was also interested in seeing you argue your points about both the two first points in the post you quoted (about GPU-accelerated decompression and "RT" audio), but again you don't seem to have come here to have any kind of exchange of opinions or knowledge. Which is really too bad.I would assume on Nvidia's internal servers and the work computers of their employees, and nowhere else. Nvidia doesn't tend to be very open source-oriented.