Friday, January 11th 2019

AMD Radeon VII Detailed Some More: Die-size, Secret-sauce, Ray-tracing, and More
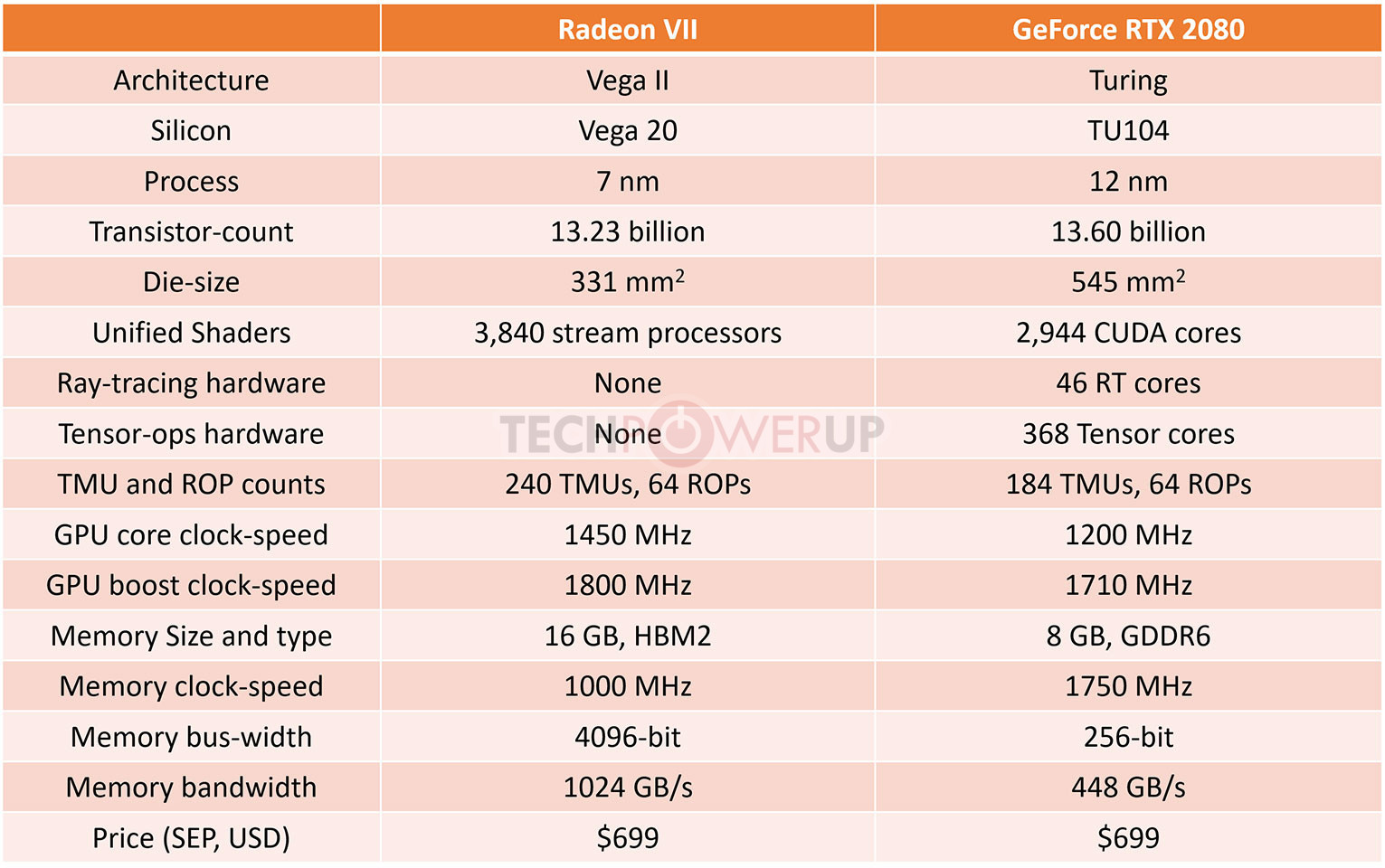
AMD pulled off a surprise at its CES 2019 keynote address, with the announcement of the Radeon VII client-segment graphics card targeted at gamers. We went hands-on with the card earlier this week. The company revealed a few more technical details of the card in its press-deck for the card. To begin with, the company talks about the immediate dividends of switching from 14 nm to 7 nm, with a reduction in die-size from 495 mm² on the "Vega 10" silicon to 331 mm² on the new "Vega 20" silicon. The company has reworked the die to feature a 4096-bit wide HBM2 memory interface, the "Vega 20" MCM now features four 32 Gbit HBM2 memory stacks, which make up the card's 16 GB of memory. The memory clock has been dialed up to 1000 MHz from 945 MHz on the RX Vega 64, which when coupled with the doubled bus-width, works out to a phenomenal 1 TB/s memory bandwidth.
We know from AMD's late-2018 announcement of the Radeon Instinct MI60 machine-learning accelerator based on the same silicon that "Vega 20" features a total of 64 NGCUs (next-generation compute units). To carve out the Radeon VII, AMD disabled 4 of these, resulting in an NGCU count of 60, which is halfway between the RX Vega 56 and RX Vega 64, resulting in a stream-processor count of 3,840. The reduced NGCU count could help AMD harvest the TSMC-built 7 nm GPU die better. AMD is attempting to make up the vast 44 percent performance gap between the RX Vega 64 and the GeForce RTX 2080 with a combination of factors.


 First, AMD appears to be maximizing the clock-speed headroom achieved from the switch to 7 nm. The Radeon VII can boost its engine clock all the way up to 1800 MHz, which may not seem significantly higher than the on-paper 1545 MHz boost frequency of the RX Vega 64, but the Radeon VII probably sustains its boost frequencies better. Second, the slide showing the competitive performance of Radeon VII against the RTX 2080 pins its highest performance gains over the NVIDIA rival in the "Vulkan" title "Strange Brigade," which is known to heavily leverage asynchronous-compute. AMD continues to have a technological upper-hand over NVIDIA in this area. AMD mentions "enhanced" asynchronous-compute for the Radeon VII, which means the company may have improved the ACEs (async-compute engines) on the "Vega 20" silicon, specialized hardware that schedule async-compute workloads among the NGCUs. With its given specs, the Radeon VII has a maximum FP32 throughput of 13.8 TFLOP/s
First, AMD appears to be maximizing the clock-speed headroom achieved from the switch to 7 nm. The Radeon VII can boost its engine clock all the way up to 1800 MHz, which may not seem significantly higher than the on-paper 1545 MHz boost frequency of the RX Vega 64, but the Radeon VII probably sustains its boost frequencies better. Second, the slide showing the competitive performance of Radeon VII against the RTX 2080 pins its highest performance gains over the NVIDIA rival in the "Vulkan" title "Strange Brigade," which is known to heavily leverage asynchronous-compute. AMD continues to have a technological upper-hand over NVIDIA in this area. AMD mentions "enhanced" asynchronous-compute for the Radeon VII, which means the company may have improved the ACEs (async-compute engines) on the "Vega 20" silicon, specialized hardware that schedule async-compute workloads among the NGCUs. With its given specs, the Radeon VII has a maximum FP32 throughput of 13.8 TFLOP/s
The third and most obvious area of improvement is memory. The "Vega 20" silicon is lavishly endowed with 16 GB of "high-bandwidth cache" memory, which thanks to the doubling in bus-width and increased memory clocks, results in 1 TB/s of memory bandwidth. Such high physical bandwidth could, in theory, allow AMD's designers to get rid of memory compression which probably frees up some of the GPU's number-crunching resources. The memory size also helps. AMD is once again throwing brute bandwidth to overcome any memory-management issues its architecture may have.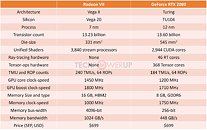 The Radeon VII is being extensively marketed as a competitor to GeForce RTX 2080. NVIDIA holds a competitive edge with its hardware being DirectX Raytracing (DXR) ready, and even integrated specialized components called RT cores into its "Turing" GPUs. The "Vega 20" continues to lack such components, however AMD CEO Dr. Lisa Su confirmed at her post-keynote press round-table that the company is working on ray-tracing. "I think ray tracing is important technology; it's something that we're working on as well, from both a hardware/software standpoint."
The Radeon VII is being extensively marketed as a competitor to GeForce RTX 2080. NVIDIA holds a competitive edge with its hardware being DirectX Raytracing (DXR) ready, and even integrated specialized components called RT cores into its "Turing" GPUs. The "Vega 20" continues to lack such components, however AMD CEO Dr. Lisa Su confirmed at her post-keynote press round-table that the company is working on ray-tracing. "I think ray tracing is important technology; it's something that we're working on as well, from both a hardware/software standpoint."
Responding to a specific question by a reporter on whether AMD has ray-tracing technology, Dr. Su said: "I'm not going to get into a tit for tat, that's just not my style. So I'll tell you that. What I will say is ray tracing is an important technology. It's one of the important technologies; there are lots of other important technologies and you will hear more about what we're doing with ray tracing. You know, we certainly have a lot going on, both hardware and software, as we bring up that entire ecosystem."
One way of reading between the lines would be - and this is speculation on our part - that AMD could working on retrofitting some of its GPUs powerful enough to handle raytracing with DXR support through a future driver update, as well as working on future generations of GPUs with hardware-acceleration for many of the tasks that are required to get hybrid rasterization work (adding real-time raytraced objects to rasterized 3D scenes). Just as real-time raytracing is technically possible on "Pascal" even if daunting on the hardware, with good enough work directed at getting a ray-tracing model to work on NGCUs leveraging async-compute, some semblance of GPU-accelerated real-time ray-tracing compatible with DXR could probably be achieved. This is not a part of the feature-set of Radeon VII at launch.
The Radeon VII will be available from 7th February, priced at $699, which is on-par with the SEP of the RTX 2080, despite the lack of real-time raytracing (at least at launch). AMD could shepherd its developer-relations on future titles being increasingly reliant on asynchronous compute, the "Vulkan" API, and other technologies its hardware is good at.
We know from AMD's late-2018 announcement of the Radeon Instinct MI60 machine-learning accelerator based on the same silicon that "Vega 20" features a total of 64 NGCUs (next-generation compute units). To carve out the Radeon VII, AMD disabled 4 of these, resulting in an NGCU count of 60, which is halfway between the RX Vega 56 and RX Vega 64, resulting in a stream-processor count of 3,840. The reduced NGCU count could help AMD harvest the TSMC-built 7 nm GPU die better. AMD is attempting to make up the vast 44 percent performance gap between the RX Vega 64 and the GeForce RTX 2080 with a combination of factors.




The third and most obvious area of improvement is memory. The "Vega 20" silicon is lavishly endowed with 16 GB of "high-bandwidth cache" memory, which thanks to the doubling in bus-width and increased memory clocks, results in 1 TB/s of memory bandwidth. Such high physical bandwidth could, in theory, allow AMD's designers to get rid of memory compression which probably frees up some of the GPU's number-crunching resources. The memory size also helps. AMD is once again throwing brute bandwidth to overcome any memory-management issues its architecture may have.
Responding to a specific question by a reporter on whether AMD has ray-tracing technology, Dr. Su said: "I'm not going to get into a tit for tat, that's just not my style. So I'll tell you that. What I will say is ray tracing is an important technology. It's one of the important technologies; there are lots of other important technologies and you will hear more about what we're doing with ray tracing. You know, we certainly have a lot going on, both hardware and software, as we bring up that entire ecosystem."
One way of reading between the lines would be - and this is speculation on our part - that AMD could working on retrofitting some of its GPUs powerful enough to handle raytracing with DXR support through a future driver update, as well as working on future generations of GPUs with hardware-acceleration for many of the tasks that are required to get hybrid rasterization work (adding real-time raytraced objects to rasterized 3D scenes). Just as real-time raytracing is technically possible on "Pascal" even if daunting on the hardware, with good enough work directed at getting a ray-tracing model to work on NGCUs leveraging async-compute, some semblance of GPU-accelerated real-time ray-tracing compatible with DXR could probably be achieved. This is not a part of the feature-set of Radeon VII at launch.
The Radeon VII will be available from 7th February, priced at $699, which is on-par with the SEP of the RTX 2080, despite the lack of real-time raytracing (at least at launch). AMD could shepherd its developer-relations on future titles being increasingly reliant on asynchronous compute, the "Vulkan" API, and other technologies its hardware is good at.
154 Comments on AMD Radeon VII Detailed Some More: Die-size, Secret-sauce, Ray-tracing, and More
so just Vega but at 7nm and more hbm2 to boost up the price.
where is Navi??
My Vega 56 with the LC Bios on a custom loop does 1780Mhz, so yeah I guess you can have that 16GB of HBM2.
The EVGA 2080ti Black went up $100 last night, I guess thats something too, should have gotten one $999, what a "steal".
What AMD showed was better marketing for nVidia then what even nVidia can come up with.
"AMD used CEO in leather jacket! It's super effective!"
In those 5 titles that support it ? I thought even AMD themselves let the async shader fad die on its own,almost no one has implemented it for three years it's been out.
Turning on RT on more powerful cards would be poinless if they're not hardware accelerated for RT. 2070 has 60TFlops of RT performance and it barely copes.
Turing does everything this does and some more.
As much as Jensen Huang is an ass-hat, what he said has some truth in it.
Dedicated Hardware acceleration for RT is a smokescreen IMO, the key is if you can cut down your FP or INT instructions as small as possible and run as many as parallel as possible. AMD does have some FP division capability so its possible that some cards can be retrofitted for RT.
At 64 ROPs per card the Raster power of the card is comparable to a 295X when CF is working (a 4 year and 9 month old card)
Navi may not be a high end but really good mid range. So just letting you know don't be disappointed. AMD has more to gain from a new architecture so wait until that to see good things.Got it. AMD cant have features that boost performance in games. Only Nvidia can. So AMD users should turn off async compute in games because Nvidia cant do it as good and turn off vulkan. Every company is going to show off the best their hardware can do. Whether you like it or not. WHat you are saying is one sided talk. Plus there are more benchmark numbers out there for vega 2 you just need to look.Honestly if they got this performance with 64 ROPs that is even more impressive. they still managed to squeeze 25-30% more performance out of Vega from same old GCN with a shrink.
This is the only Vega20 block-diagram available for now (picked up from MI60 slides):
I only see four pixel engines per pipeline, 16 in all, which do 4 pixels/clock, working out to 64 ROPs.
anyway,my point was wrong in the first place since I looked at v64 vs 1080 only, the same chart shows turing cards seem to get better in vulkan+async on mode so let's not argue about something I was wrong about in the first place.
Makes me feel better about AMD's performance numbers at least! Suppose they left it in to counteract the insane spikes up. Dunno, weird they left that one in.
If this has the full FP64 performance, this card might indeed has some merit, as a Vega FE replacement.
A much cheaper Radeon Pro without all the proper certifications, that is if this card has access to the Pro drivers and ROCm etc.
If they do happend to add 64 more ROPS then the performance benefit should be alot better then what it is now, right? Because the original VEGA seemed to be bottlenecked by both amount of ROPS and memory bandwidth. It's a different chip then which i find a weird move since NAVI is coming out as well. That means they are running at least 3 different GPU's on the assembly line from RX590 to VEGA and NAVI. The 60 CU's seem to be a choice to get best from a single wafer. Perhaps there are bios mods available for a full 64 CU unlock. :D
Furthermore the performance seems good; i'm about to slam 2000 euro into a complete new TR2 system so this card is more then welcome.
Do not expect RayTracing in hardware until end of 2020 and even then they will be years behind nVidia who will, by that time, be in the process of readying their third gen RTX cards for release.
We need Intel to enter the market with RayTracing from the get go in 2020.
I also have a feeling that AMD may be working secretly with Intel on RayTracing tech to sett up a unified standard against nvidias RTX.