Friday, April 5th 2024
X-Silicon Startup Wants to Combine RISC-V CPU, GPU, and NPU in a Single Processor
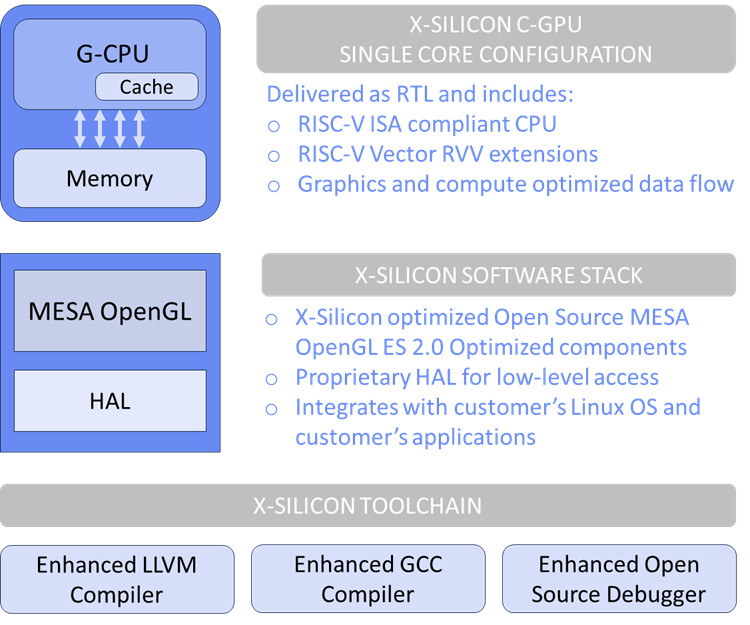
While we are all used to having a system with a CPU, GPU, and, recently, NPU—X-Silicon Inc. (XSi), a startup founded by former Silicon Valley veterans—has unveiled an interesting RISC-V processor that can simultaneously handle CPU, GPU, and NPU workloads in a chip. This innovative chip architecture, which will be open-source, aims to provide a flexible and efficient solution for a wide range of applications, including artificial intelligence, virtual reality, automotive systems, and IoT devices. The new microprocessor combines a RISC-V CPU core with vector capabilities and GPU acceleration into a single chip, creating a versatile all-in-one processor. By integrating the functionality of a CPU and GPU into a single core, X-Silicon's design offers several advantages over traditional architectures. The chip utilizes the open-source RISC-V instruction set architecture (ISA) for both CPU and GPU operations, running a single instruction stream. This approach promises lower memory footprint execution and improved efficiency, as there is no need to copy data between separate CPU and GPU memory spaces.
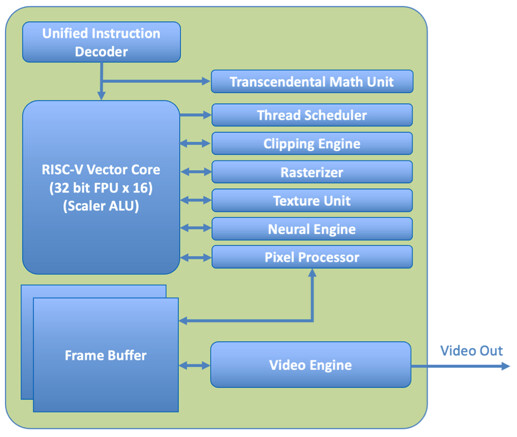
Called the C-GPU architecture, X-Silicon uses RISC-V Vector Core, which has 16 32-bit FPUs and a Scaler ALU for processing regular integers as well as floating point instructions. A unified instruction decoder feeds the cores, which are connected to a thread scheduler, texture unit, rasterizer, clipping engine, neural engine, and pixel processors. All is fed into a frame buffer, which feeds the video engine for video output. The setup of the cores allows the users to program each core individually for HPC, AI, video, or graphics workloads. Without software, there is no usable chip, which prompts X-Silicon to work on OpenGL ES, Vulkan, Mesa, and OpenCL APIs. Additionally, the company plans to release a hardware abstraction layer (HAL) for direct chip programming. According to Jon Peddie Research (JPR), the industry has been seeking an open-standard GPU that is flexible and scalable enough to support various markets. X-Silicon's CPU/GPU hybrid chip aims to address this need by providing manufacturers with a single, open-chip design that can handle any desired workload. The XSi gave no timeline, but it has plans to distribute the IP to OEMs and hyperscalers, so the first silicon is still away.


Sources:
Jon Peddie Research, X-Silicon, via Tom's Hardware
Called the C-GPU architecture, X-Silicon uses RISC-V Vector Core, which has 16 32-bit FPUs and a Scaler ALU for processing regular integers as well as floating point instructions. A unified instruction decoder feeds the cores, which are connected to a thread scheduler, texture unit, rasterizer, clipping engine, neural engine, and pixel processors. All is fed into a frame buffer, which feeds the video engine for video output. The setup of the cores allows the users to program each core individually for HPC, AI, video, or graphics workloads. Without software, there is no usable chip, which prompts X-Silicon to work on OpenGL ES, Vulkan, Mesa, and OpenCL APIs. Additionally, the company plans to release a hardware abstraction layer (HAL) for direct chip programming. According to Jon Peddie Research (JPR), the industry has been seeking an open-standard GPU that is flexible and scalable enough to support various markets. X-Silicon's CPU/GPU hybrid chip aims to address this need by providing manufacturers with a single, open-chip design that can handle any desired workload. The XSi gave no timeline, but it has plans to distribute the IP to OEMs and hyperscalers, so the first silicon is still away.
31 Comments on X-Silicon Startup Wants to Combine RISC-V CPU, GPU, and NPU in a Single Processor
sounds like a startup using buzzwords to get money.
NVIDIA for example has been using Special Function Units (SFU) to handle them, located along more general CUDA cores inside Streaming Multiprocessors (SM) since at least G80. In one form or another they have been present in every graphics-related acceleration implementation.
I don't really see a potential for this idea. Traditional SoCs have already tried minimizing the physical gap between general and graphics processors with mixed results. Sure you get simpler memory management and lower latency, but you replace it with lower power envelope and much more limited real estate. Merging all aspects into one makes those limitations even worse, plus you add a much more complex scheduler and a most likely humongous instruction set.
A jack of all trade is a master of none.
Edit: NVIDIA published a paper on SFU's design in 2005, you can find it on IEEE Xplore if you have access or on Anna's Archive if you don't via DOI:10.1109/ARITH.2005.7
While it's an older paper it explains why a specialized hardware implementation was beneficial vs. a general approach.
Did you even look at the paper? It explains their implementation which is using lookup tables in ROM because doing it "by hand" every time is wasteful.
Anyway we know enough about NVIDIA SASS to know that instructions containing the MUFU. prefix are handled by the SFUs.
You can take a simple example:
Compile it with and you'll get:
PTX by cuobjdump -ptx:
and SASS by cuobjdump -sass:
So that's using SFUs directly. Remove the -use_fast_math and you'll get a hybrid version:
images.anandtech.com/reviews/cpu/amd/roadahead/evolving2.jpg
I still remember the image above. :)
Step3:
"The final step in the evolution of Fusion is where the CPU and GPU are truly integrated, and the GPU is accessed by user mode instructions just like the CPU. You can expect to talk to the GPU via extensions to the x86 ISA, and the GPU will have its own register file (much like FP and integer units each have their own register files)."
Link to this article:
www.anandtech.com/show/2229/3
The processor inside the C64 famously did not have a multiply instruction. You may find it odd but most processors today simply emulate instructions, it's not done for speed, back then they didn't do it because it simply took too much space.This doesn't really say anything other that what is already known, SASS actually gets compiled into micro ops, what those micro ops are no one knows. Anyway all of this is still in line with what I am saying, these instructions are just emulated, whether you do it at micro op level or in assembly it should make no difference. Why do you think that if you write modern C code using transcendental functions the compiler wont output any special instructions ? Intel and AMD are just stupid ? They don't know how to make dedicated really fast hardware for transcendental ops ? No, it just doesn't matter.
GPU manufactures are kind of forced to add these at the ISA level, because you can't get portable code and they write the compilers themselves and every time they make a new GPU they usually change the ISA as well, so they have to provide these primitives, not for speed reasons but for ease of use. You can't just plop in some library that does all this when you program on a GPU like you do on a CPU.
Why does every NVIDIA documentation piece, every architectural diagram of SMs mention SFUs if they are simply "emulated"? Why bother with specifying the number of units per SM for each generation?
You can even test it yourself by occupying all CUDA cores and then launching operations directly on SFUs.
By the way the reason they mention the number of those "SFUs" is because GPU cores are usually really limited in the number or combinations of instructions they can emit per clock, so it might be useful to know how that might impact performance.
If the previous linked NVIDIA paper wasn't enough for you then here's another one proving that in fact SFUs exist, and can be used to improve performance and significantly improve energy efficiency of certain calculations. The authors even were able to use SFUs for double-precision, which is something NVIDIA themselves doesn't support in CUDA.
SFUs exist in the same sense CUDA cores exist, Nvidia has no concrete definition for what a "CUDA core" is. As far as I can tell total CUDA cores = number of FP32 FMAD units, it's not a core by any definition, it doesn't fetch and decode instructions by itself, yet they insist to call it a "core". Same with these SFUs, they do not fetch and decode instructions either, the SM does since that's what's actually generating the wavefronts, so what does that unit even do ? Anyway this has been going on for too long, if you think Nvidia has some special hardware block to compute sin and cos and whatnot, that's fine, whatever.
It's slow because it's just doing a series expansion, a bunch of x - x^3/3! +x^5/5!... to calculate sin(x) for example, there is no special way to do that in hardware, it will just have to be a series of instructions to calculate that up to whatever term. You can try and use look up tables or use approximations that converge faster but it will still all come down to a bunch of adds and multiplies in series, it's unavoidable.
However, at least the scalar integer and FP multiplications have been optimised to no end - and they execute in *one clock cycle* on recent CPUs at least since Skylake and Zen 1. Vector integer and double-precision FP multiplications seem to be equally fast, but I don't understand enough about data formats there. Agner Fog collected all the data you can think of.
I guess we have an industry-wide conspiracy for introducing emulated virtual hardware units to handle transcendentals. All 3 PC vendors agreed to lie at the same time in the same way I guess :)Yes, NVIDIA is actually lying in their architectural whitepapers, in every single one. They publish scientific papers on the implementation of "sin and cos and whatnot", get it accepted to IEEE journal just for fun.
Are you a troll? You provided no sources for your claims, just how you think things work.
Edit: Added Intel.
Investor scam warning!
Build it, show it running a 3D-game with at least 60 FPS, then trigger a press release again.